 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Relation Mining Network for Zero-Shot Learning
May 06, 2024Zero-shot learning (ZSL) aims to recognize novel classes through transferring shared semantic knowledge (e.g., attributes) from seen classes to unseen classes. Recently, attention-based methods have exhibited significant progress which align visual features and attributes via a spatial attention mechanism. However, these methods only explore visual-semantic relationship in the spatial dimension, which can lead to classification ambiguity when different attributes share similar attention regions, and semantic relationship between attributes is rarely discussed. To alleviate the above problems, we propose a Dual Relation Mining Network (DRMN) to enable more effective visual-semantic interactions and learn semantic relationship among attributes for knowledge transfer. Specifically, we introduce a Dual Attention Block (DAB) for visual-semantic relationship mining, which enriches visual information by multi-level feature fusion and conducts spatial attention for visual to semantic embedding. Moreover, an attribute-guided channel attention is utilized to decouple entangled semantic features. For semantic relationship modeling, we utilize a Semantic Interaction Transformer (SIT) to enhance the generalization of attribute representations among images. Additionally, a global classification branch is introduced as a complement to human-defined semantic attributes, and we then combine the results with attribute-based classification. Extensive experiments demonstrate that the proposed DRMN leads to new state-of-the-art performances on three standard ZSL benchmarks, i.e., CUB, SUN, and AwA2.
Anchor-based Robust Finetuning of Vision-Language Models
Apr 09, 2024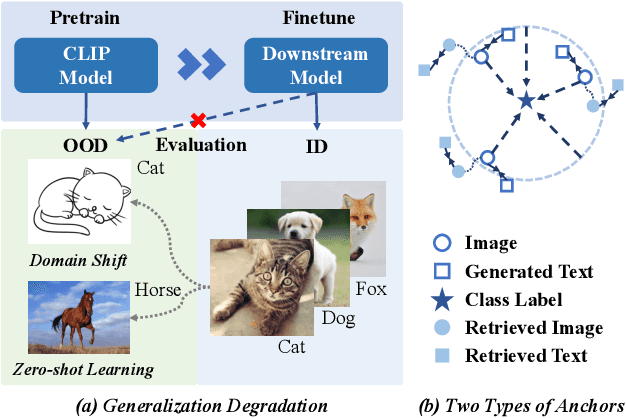
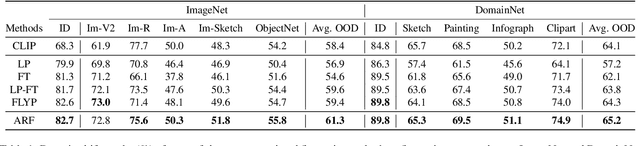
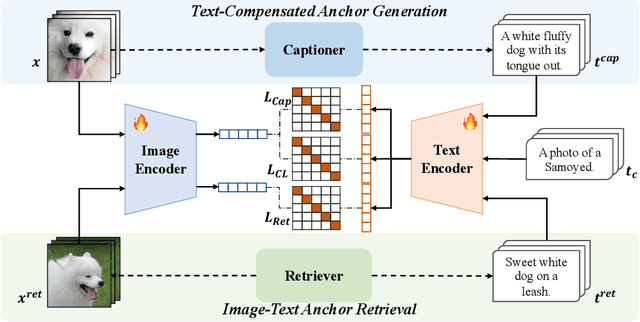
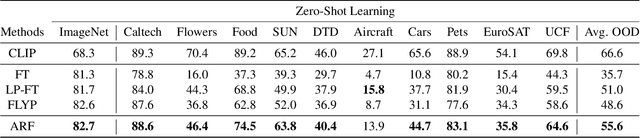
We aim at finetuning a vision-language model without hurting its out-of-distribution (OOD) generalization. We address two types of OOD generalization, i.e., i) domain shift such as natural to sketch images, and ii) zero-shot capability to recognize the category that was not contained in the finetune data. Arguably, the diminished OOD generalization after finetuning stems from the excessively simplified finetuning target, which only provides the class information, such as ``a photo of a [CLASS]''. This is distinct from the process in that CLIP was pretrained, where there is abundant text supervision with rich semantic information. Therefore, we propose to compensate for the finetune process using auxiliary supervision with rich semantic information, which acts as anchors to preserve the OOD generalization. Specifically, two types of anchors are elaborated in our method, including i) text-compensated anchor which uses the images from the finetune set but enriches the text supervision from a pretrained captioner, ii) image-text-pair anchor which is retrieved from the dataset similar to pretraining data of CLIP according to the downstream task, associating with the original CLIP text with rich semantics. Those anchors are utilized as auxiliary semantic information to maintain the original feature space of CLIP, thereby preserving the OOD generalization capabilities. Comprehensive experiments demonstrate that our method achieves in-distribution performance akin to conventional finetuning while attaining new state-of-the-art results on domain shift and zero-shot learning benchmarks.
Location-free Human Pose Estimation
May 25, 2022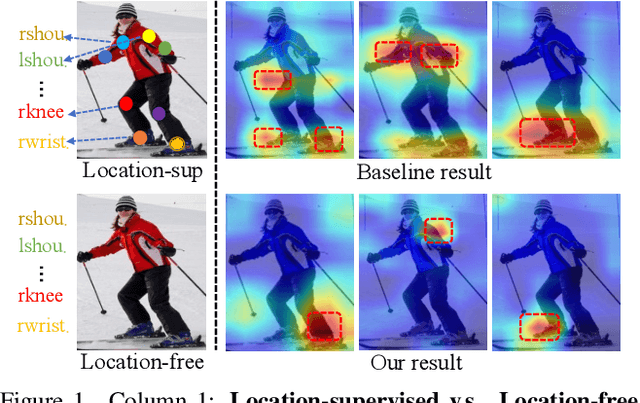
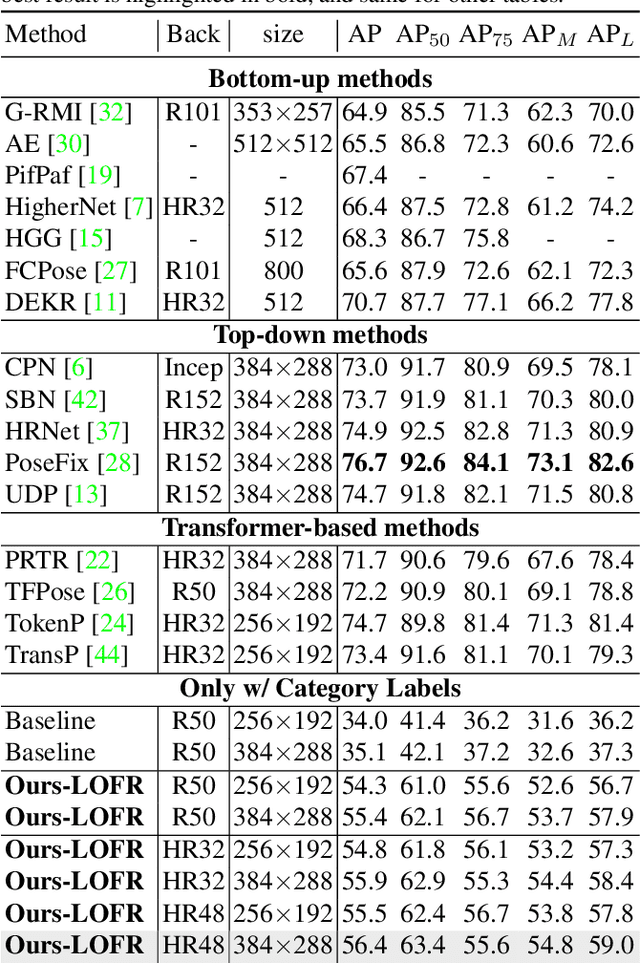
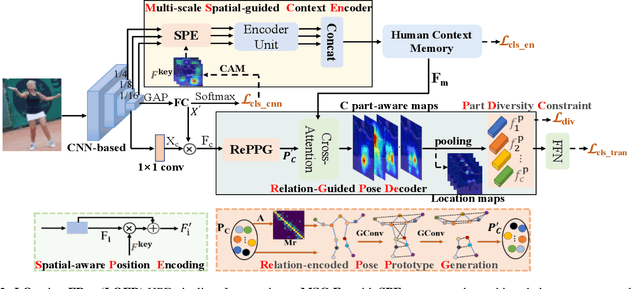
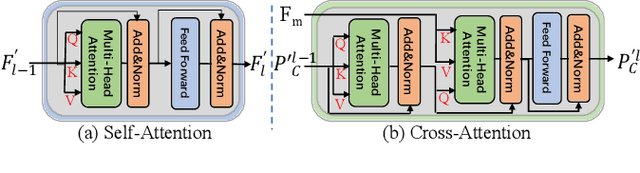
Human pose estimation (HPE) usually requires large-scale training data to reach high performance. However, it is rather time-consuming to collect high-quality and fine-grained annotations for human body. To alleviate this issue, we revisit HPE and propose a location-free framework without supervision of keypoint locations. We reformulate the regression-based HPE from the perspective of classification. Inspired by the CAM-based weakly-supervised object localization, we observe that the coarse keypoint locations can be acquired through the part-aware CAMs but unsatisfactory due to the gap between the fine-grained HPE and the object-level localization. To this end, we propose a customized transformer framework to mine the fine-grained representation of human context, equipped with the structural relation to capture subtle differences among keypoints. Concretely, we design a Multi-scale Spatial-guided Context Encoder to fully capture the global human context while focusing on the part-aware regions and a Relation-encoded Pose Prototype Generation module to encode the structural relations. All these works together for strengthening the weak supervision from image-level category labels on locations. Our model achieves competitive performance on three datasets when only supervised at a category-level and importantly, it can achieve comparable results with fully-supervised methods with only 25\% location labels on MS-COCO and MPII.
Unveiling the Potential of Structure Preserving for Weakly Supervised Object Localization
Mar 30, 2021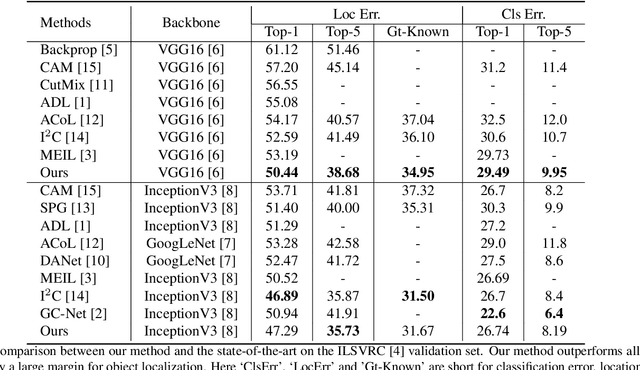

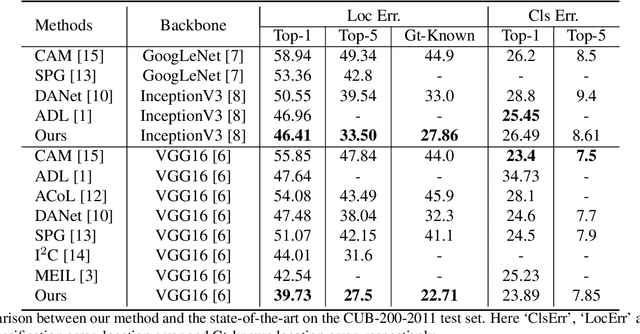
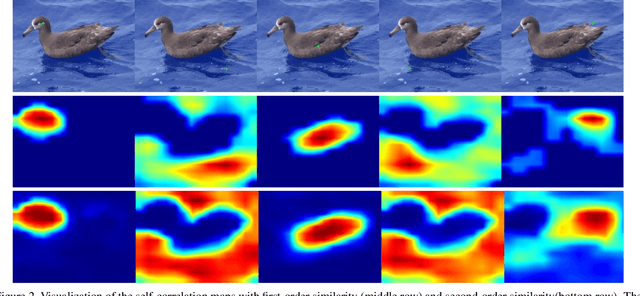
Weakly supervised object localization(WSOL) remains an open problem given the deficiency of finding object extent information using a classification network. Although prior works struggled to localize objects through various spatial regularization strategies, we argue that how to extract object structural information from the trained classification network is neglected. In this paper, we propose a two-stage approach, termed structure-preserving activation (SPA), toward fully leveraging the structure information incorporated in convolutional features for WSOL. First, a restricted activation module (RAM) is designed to alleviate the structure-missing issue caused by the classification network on the basis of the observation that the unbounded classification map and global average pooling layer drive the network to focus only on object parts. Second, we designed a post-process approach, termed self-correlation map generating (SCG) module to obtain structure-preserving localization maps on the basis of the activation maps acquired from the first stage. Specifically, we utilize the high-order self-correlation (HSC) to extract the inherent structural information retained in the learned model and then aggregate HSC of multiple points for precise object localization. Extensive experiments on two publicly available benchmarks including CUB-200-2011 and ILSVRC show that the proposed SPA achieves substantial and consistent performance gains compared with baseline approaches.Code and models are available at https://github.com/Panxjia/SPA_CVPR2021