 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Relation Mining Network for Zero-Shot Learning
May 06, 2024Zero-shot learning (ZSL) aims to recognize novel classes through transferring shared semantic knowledge (e.g., attributes) from seen classes to unseen classes. Recently, attention-based methods have exhibited significant progress which align visual features and attributes via a spatial attention mechanism. However, these methods only explore visual-semantic relationship in the spatial dimension, which can lead to classification ambiguity when different attributes share similar attention regions, and semantic relationship between attributes is rarely discussed. To alleviate the above problems, we propose a Dual Relation Mining Network (DRMN) to enable more effective visual-semantic interactions and learn semantic relationship among attributes for knowledge transfer. Specifically, we introduce a Dual Attention Block (DAB) for visual-semantic relationship mining, which enriches visual information by multi-level feature fusion and conducts spatial attention for visual to semantic embedding. Moreover, an attribute-guided channel attention is utilized to decouple entangled semantic features. For semantic relationship modeling, we utilize a Semantic Interaction Transformer (SIT) to enhance the generalization of attribute representations among images. Additionally, a global classification branch is introduced as a complement to human-defined semantic attributes, and we then combine the results with attribute-based classification. Extensive experiments demonstrate that the proposed DRMN leads to new state-of-the-art performances on three standard ZSL benchmarks, i.e., CUB, SUN, and AwA2.
Anchor-based Robust Finetuning of Vision-Language Models
Apr 09, 2024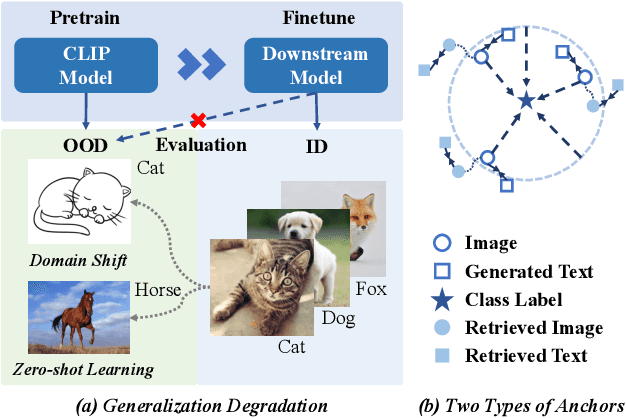
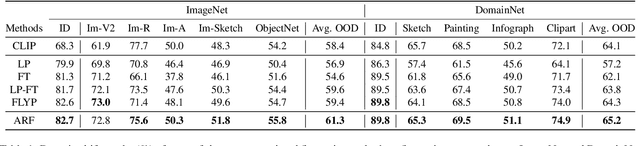
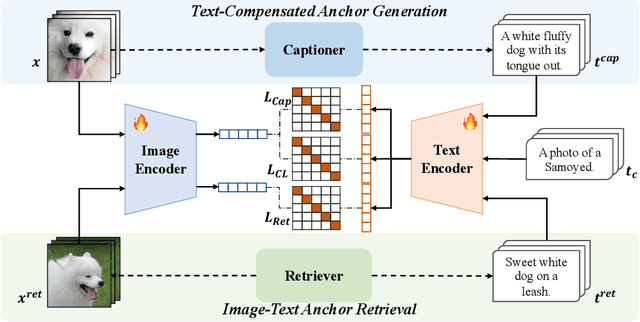
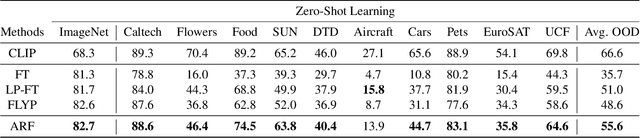
We aim at finetuning a vision-language model without hurting its out-of-distribution (OOD) generalization. We address two types of OOD generalization, i.e., i) domain shift such as natural to sketch images, and ii) zero-shot capability to recognize the category that was not contained in the finetune data. Arguably, the diminished OOD generalization after finetuning stems from the excessively simplified finetuning target, which only provides the class information, such as ``a photo of a [CLASS]''. This is distinct from the process in that CLIP was pretrained, where there is abundant text supervision with rich semantic information. Therefore, we propose to compensate for the finetune process using auxiliary supervision with rich semantic information, which acts as anchors to preserve the OOD generalization. Specifically, two types of anchors are elaborated in our method, including i) text-compensated anchor which uses the images from the finetune set but enriches the text supervision from a pretrained captioner, ii) image-text-pair anchor which is retrieved from the dataset similar to pretraining data of CLIP according to the downstream task, associating with the original CLIP text with rich semantics. Those anchors are utilized as auxiliary semantic information to maintain the original feature space of CLIP, thereby preserving the OOD generalization capabilities. Comprehensive experiments demonstrate that our method achieves in-distribution performance akin to conventional finetuning while attaining new state-of-the-art results on domain shift and zero-shot learning benchmarks.