 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocation-free Human Pose Estimation
May 25, 2022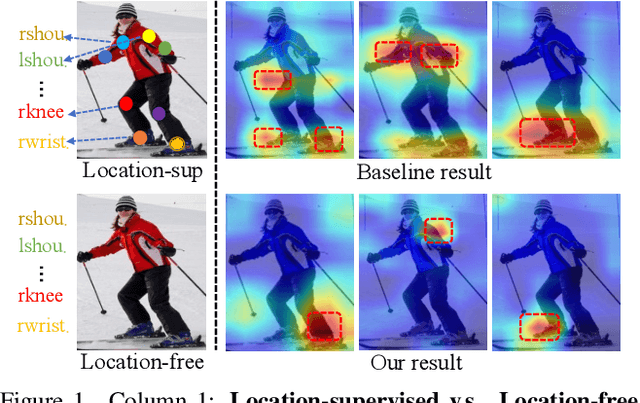
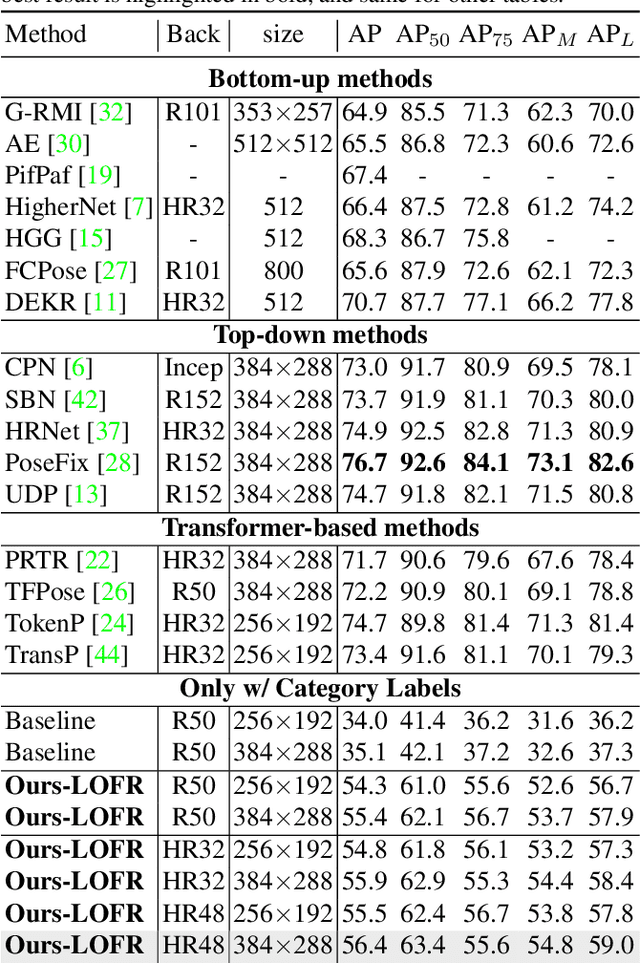
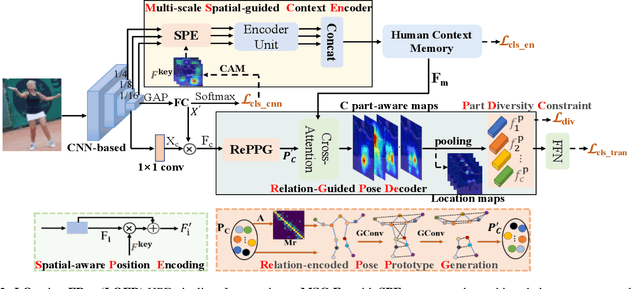
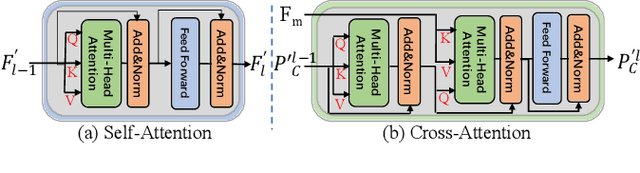
Human pose estimation (HPE) usually requires large-scale training data to reach high performance. However, it is rather time-consuming to collect high-quality and fine-grained annotations for human body. To alleviate this issue, we revisit HPE and propose a location-free framework without supervision of keypoint locations. We reformulate the regression-based HPE from the perspective of classification. Inspired by the CAM-based weakly-supervised object localization, we observe that the coarse keypoint locations can be acquired through the part-aware CAMs but unsatisfactory due to the gap between the fine-grained HPE and the object-level localization. To this end, we propose a customized transformer framework to mine the fine-grained representation of human context, equipped with the structural relation to capture subtle differences among keypoints. Concretely, we design a Multi-scale Spatial-guided Context Encoder to fully capture the global human context while focusing on the part-aware regions and a Relation-encoded Pose Prototype Generation module to encode the structural relations. All these works together for strengthening the weak supervision from image-level category labels on locations. Our model achieves competitive performance on three datasets when only supervised at a category-level and importantly, it can achieve comparable results with fully-supervised methods with only 25\% location labels on MS-COCO and MPII.
Alleviating Human-level Shift : A Robust Domain Adaptation Method for Multi-person Pose Estimation
Aug 13, 2020
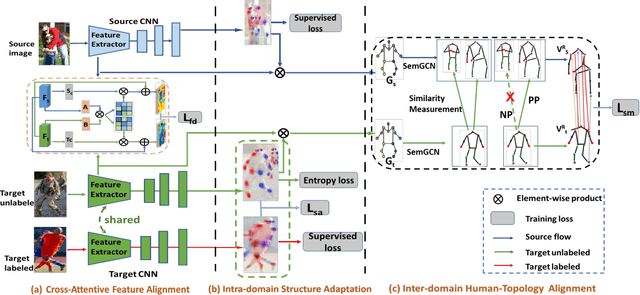
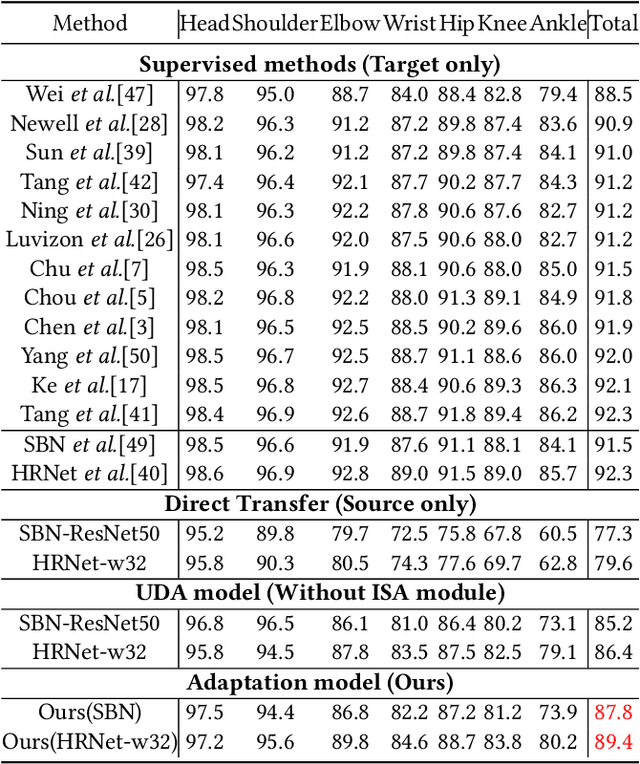

Human pose estimation has been widely studied with much focus on supervised learning requiring sufficient annotations. However, in real applications, a pretrained pose estimation model usually need be adapted to a novel domain with no labels or sparse labels. Such domain adaptation for 2D pose estimation hasn't been explored. The main reason is that a pose, by nature, has typical topological structure and needs fine-grained features in local keypoints. While existing adaptation methods do not consider topological structure of object-of-interest and they align the whole images coarsely. Therefore, we propose a novel domain adaptation method for multi-person pose estimation to conduct the human-level topological structure alignment and fine-grained feature alignment. Our method consists of three modules: Cross-Attentive Feature Alignment (CAFA), Intra-domain Structure Adaptation (ISA) and Inter-domain Human-Topology Alignment (IHTA) module. The CAFA adopts a bidirectional spatial attention module (BSAM)that focuses on fine-grained local feature correlation between two humans to adaptively aggregate consistent features for adaptation. We adopt ISA only in semi-supervised domain adaptation (SSDA) to exploit the corresponding keypoint semantic relationship for reducing the intra-domain bias. Most importantly, we propose an IHTA to learn more domain-invariant human topological representation for reducing the inter-domain discrepancy. We model the human topological structure via the graph convolution network (GCN), by passing messages on which, high-order relations can be considered. This structure preserving alignment based on GCN is beneficial to the occluded or extreme pose inference. Extensive experiments are conducted on two popular benchmarks and results demonstrate the competency of our method compared with existing supervised approaches.
Multi-Person Pose Estimation with Enhanced Feature Aggregation and Selection
Mar 20, 2020

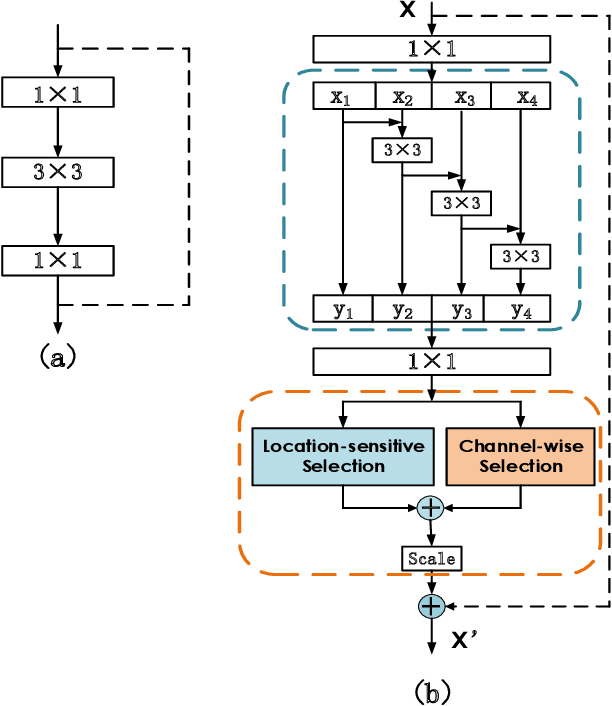
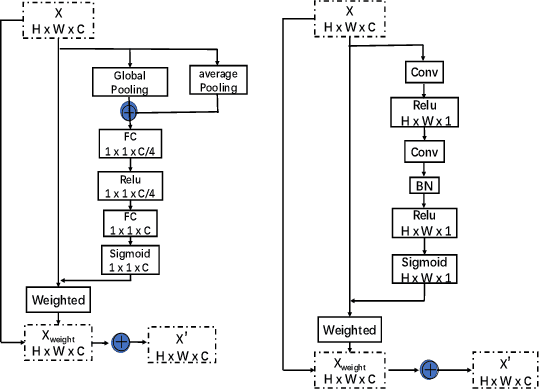
We propose a novel Enhanced Feature Aggregation and Selection network (EFASNet) for multi-person 2D human pose estimation. Due to enhanced feature representation, our method can well handle crowded, cluttered and occluded scenes. More specifically, a Feature Aggregation and Selection Module (FASM), which constructs hierarchical multi-scale feature aggregation and makes the aggregated features discriminative, is proposed to get more accurate fine-grained representation, leading to more precise joint locations. Then, we perform a simple Feature Fusion (FF) strategy which effectively fuses high-resolution spatial features and low-resolution semantic features to obtain more reliable context information for well-estimated joints. Finally, we build a Dense Upsampling Convolution (DUC) module to generate more precise prediction, which can recover missing joint details that are usually unavailable in common upsampling process. As a result, the predicted keypoint heatmaps are more accurate. Comprehensive experiments demonstrate that the proposed approach outperforms the state-of-the-art methods and achieves the superior performance over three benchmark datasets: the recent big dataset CrowdPose, the COCO keypoint detection dataset and the MPII Human Pose dataset. Our code will be released upon acceptance.