 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlleviating Human-level Shift : A Robust Domain Adaptation Method for Multi-person Pose Estimation
Paper and Code

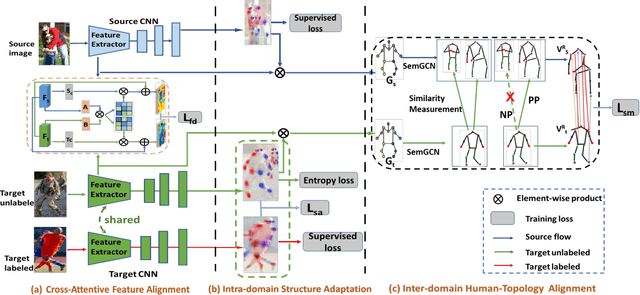
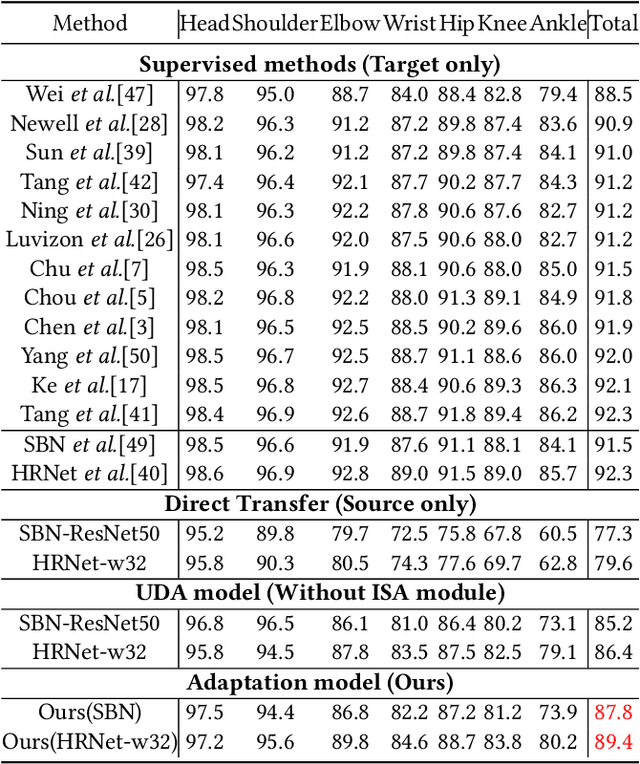

Human pose estimation has been widely studied with much focus on supervised learning requiring sufficient annotations. However, in real applications, a pretrained pose estimation model usually need be adapted to a novel domain with no labels or sparse labels. Such domain adaptation for 2D pose estimation hasn't been explored. The main reason is that a pose, by nature, has typical topological structure and needs fine-grained features in local keypoints. While existing adaptation methods do not consider topological structure of object-of-interest and they align the whole images coarsely. Therefore, we propose a novel domain adaptation method for multi-person pose estimation to conduct the human-level topological structure alignment and fine-grained feature alignment. Our method consists of three modules: Cross-Attentive Feature Alignment (CAFA), Intra-domain Structure Adaptation (ISA) and Inter-domain Human-Topology Alignment (IHTA) module. The CAFA adopts a bidirectional spatial attention module (BSAM)that focuses on fine-grained local feature correlation between two humans to adaptively aggregate consistent features for adaptation. We adopt ISA only in semi-supervised domain adaptation (SSDA) to exploit the corresponding keypoint semantic relationship for reducing the intra-domain bias. Most importantly, we propose an IHTA to learn more domain-invariant human topological representation for reducing the inter-domain discrepancy. We model the human topological structure via the graph convolution network (GCN), by passing messages on which, high-order relations can be considered. This structure preserving alignment based on GCN is beneficial to the occluded or extreme pose inference. Extensive experiments are conducted on two popular benchmarks and results demonstrate the competency of our method compared with existing supervised approaches.