 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards 3D Scene Understanding by Referring Synthetic Models
Paper and Code
Mar 20, 2022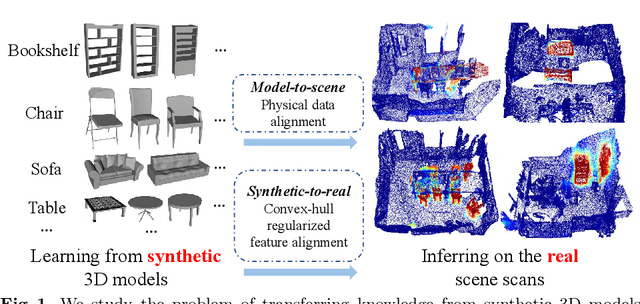
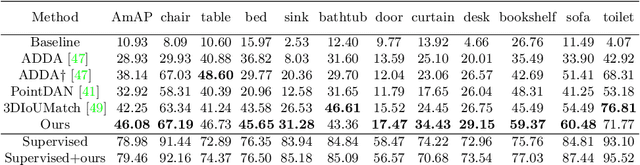

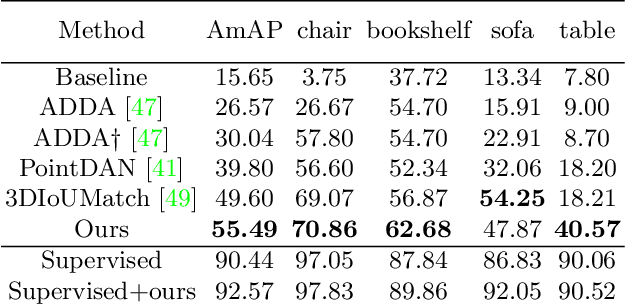
Promising performance has been achieved for visual perception on the point cloud. However, the current methods typically rely on labour-extensive annotations on the scene scans. In this paper, we explore how synthetic models alleviate the real scene annotation burden, i.e., taking the labelled 3D synthetic models as reference for supervision, the neural network aims to recognize specific categories of objects on a real scene scan (without scene annotation for supervision). The problem studies how to transfer knowledge from synthetic 3D models to real 3D scenes and is named Referring Transfer Learning (RTL). The main challenge is solving the model-to-scene (from a single model to the scene) and synthetic-to-real (from synthetic model to real scene's object) gap between the synthetic model and the real scene. To this end, we propose a simple yet effective framework to perform two alignment operations. First, physical data alignment aims to make the synthetic models cover the diversity of the scene's objects with data processing techniques. Then a novel \textbf{convex-hull regularized feature alignment} introduces learnable prototypes to project the point features of both synthetic models and real scenes to a unified feature space, which alleviates the domain gap. These operations ease the model-to-scene and synthetic-to-real difficulty for a network to recognize the target objects on a real unseen scene. Experiments show that our method achieves the average mAP of 46.08\% and 55.49\% on the ScanNet and S3DIS datasets by learning the synthetic models from the ModelNet dataset. Code will be publicly available.