 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDivide-and-Conquer Inference for Large-Scale Visual Recognition with Multimodal Large Language Models
May 24, 2026Multimodal Large Language Models (MLLMs) have demonstrated strong capabilities across a wide range of vision language tasks. However, when applied to large scale image classification, their performance degrades significantly as the label space expands a phenomenon we define as Performance Collapse in Long Sequence Recognition. Through an information theoretic analysis, we reveal that this collapse stems from a fundamental conflict between the escalating information entropy and the prominent attention dilution and decay within attention mechanisms, which impairs the model's ability to maintain a sufficient signal-to-noise ratio when processing extremely long prompts. To mitigate this, we propose Divide-and-Conquer Inference (DCI), a novel test-time scaling strategy for visual recognition with MLLMs. DCI recursively decomposes complex global classification tasks into multiple simpler, localized subproblems and employs a dynamic pruning mechanism to compress the search space. This method effectively improves the local signal to noise ratio and model accuracy by mitigating the inherent weight dilution issues in long-sequence inference. Moreover, while traditional self-attention incurs a prohibitive quadratic computational complexity, DCI achieves more favorable scaling behavior and substantially accelerates inference in large scale classification scenarios. Extensive experiments on benchmarks such as ImageNet-1K and ImageNet-21K demonstrate that DCI consistently improves classification accuracy. This enables lightweight open-source models to rival or even surpass frontier closed-source giants without any additional training or fine-tuning. As a model-agnostic, plug-and-play paradigm, DCI offers an efficient approach for scaling the inferential precision of MLLMs in large-scale scenarios.
Step-level Denoising-time Diffusion Alignment with Multiple Objectives
Apr 15, 2026Reinforcement learning (RL) has emerged as a powerful tool for aligning diffusion models with human preferences, typically by optimizing a single reward function under a KL regularization constraint. In practice, however, human preferences are inherently pluralistic, and aligned models must balance multiple downstream objectives, such as aesthetic quality and text-image consistency. Existing multi-objective approaches either rely on costly multi-objective RL fine-tuning or on fusing separately aligned models at denoising time, but they generally require access to reward values (or their gradients) and/or introduce approximation error in the resulting denoising objectives. In this paper, we revisit the problem of RL fine-tuning for diffusion models and address the intractability of identifying the optimal policy by introducing a step-level RL formulation. Building on this, we further propose Multi-objective Step-level Denoising-time Diffusion Alignment (MSDDA), a retraining-free framework for aligning diffusion models with multiple objectives, obtaining the optimal reverse denoising distribution in closed form, with mean and variance expressed directly in terms of single-objective base models. We prove that this denoising-time objective is exactly equivalent to the step-level RL fine-tuning, introducing no approximation error. Moreover, we provide numerical results, which indicate our method outperforms existing denoising-time approaches.
A Capsule-Sized Multi-Wavelength Wireless Optical System for Edge-AI-Based Classification of Gastrointestinal Bleeding Flow Rate
Jan 25, 2026Post-endoscopic gastrointestinal (GI) rebleeding frequently occurs within the first 72 hours after therapeutic hemostasis and remains a major cause of early morbidity and mortality. Existing non-invasive monitoring approaches primarily provide binary blood detection and lack quantitative assessment of bleeding severity or flow dynamic, limiting their ability to support timely clinical decision-making during this high-risk period. In this work, we developed a capsule-sized, multi-wavelength optical sensing wireless platform for order-of-magnitude-level classification of GI bleeding flow rate, leveraging transmission spectroscopy and low-power edge artificial intelligence. The system performs time-resolved, multi-spectral measurements and employs a lightweight two-dimensional convolutional neural network for on-device flow-rate classification, with physics-based validation confirming consistency with wavelength-dependent hemoglobin absorption behavior. In controlled in vitro experiments under simulated gastric conditions, the proposed approach achieved an overall classification accuracy of 98.75% across multiple bleeding flow-rate levels while robustly distinguishing diverse non-blood gastrointestinal interference. By performing embedded inference directly on the capsule electronics, the system reduced overall energy consumption by approximately 88% compared with continuous wireless transmission of raw data, making prolonged, battery-powered operation feasible. Extending capsule-based diagnostics beyond binary blood detection toward continuous, site-specific assessment of bleeding severity, this platform has the potential to support earlier identification of clinically significant rebleeding and inform timely re-intervention during post-endoscopic surveillance.
TowerMind: A Tower Defence Game Learning Environment and Benchmark for LLM as Agents
Jan 09, 2026Recent breakthroughs in Large Language Models (LLMs) have positioned them as a promising paradigm for agents, with long-term planning and decision-making emerging as core general-purpose capabilities for adapting to diverse scenarios and tasks. Real-time strategy (RTS) games serve as an ideal testbed for evaluating these two capabilities, as their inherent gameplay requires both macro-level strategic planning and micro-level tactical adaptation and action execution. Existing RTS game-based environments either suffer from relatively high computational demands or lack support for textual observations, which has constrained the use of RTS games for LLM evaluation. Motivated by this, we present TowerMind, a novel environment grounded in the tower defense (TD) subgenre of RTS games. TowerMind preserves the key evaluation strengths of RTS games for assessing LLMs, while featuring low computational demands and a multimodal observation space, including pixel-based, textual, and structured game-state representations. In addition, TowerMind supports the evaluation of model hallucination and provides a high degree of customizability. We design five benchmark levels to evaluate several widely used LLMs under different multimodal input settings. The results reveal a clear performance gap between LLMs and human experts across both capability and hallucination dimensions. The experiments further highlight key limitations in LLM behavior, such as inadequate planning validation, a lack of multifinality in decision-making, and inefficient action use. We also evaluate two classic reinforcement learning algorithms: Ape-X DQN and PPO. By offering a lightweight and multimodal design, TowerMind complements the existing RTS game-based environment landscape and introduces a new benchmark for the AI agent field. The source code is publicly available on GitHub(https://github.com/tb6147877/TowerMind).
Intelligent recognition of GPR road hidden defect images based on feature fusion and attention mechanism
Dec 25, 2025Ground Penetrating Radar (GPR) has emerged as a pivotal tool for non-destructive evaluation of subsurface road defects. However, conventional GPR image interpretation remains heavily reliant on subjective expertise, introducing inefficiencies and inaccuracies. This study introduces a comprehensive framework to address these limitations: (1) A DCGAN-based data augmentation strategy synthesizes high-fidelity GPR images to mitigate data scarcity while preserving defect morphology under complex backgrounds; (2) A novel Multi-modal Chain and Global Attention Network (MCGA-Net) is proposed, integrating Multi-modal Chain Feature Fusion (MCFF) for hierarchical multi-scale defect representation and Global Attention Mechanism (GAM) for context-aware feature enhancement; (3) MS COCO transfer learning fine-tunes the backbone network, accelerating convergence and improving generalization. Ablation and comparison experiments validate the framework's efficacy. MCGA-Net achieves Precision (92.8%), Recall (92.5%), and mAP@50 (95.9%). In the detection of Gaussian noise, weak signals and small targets, MCGA-Net maintains robustness and outperforms other models. This work establishes a new paradigm for automated GPR-based defect detection, balancing computational efficiency with high accuracy in complex subsurface environments.
* Accepted for publication in *IEEE Transactions on Geoscience and Remote Sensing*
Lightweight framework for underground pipeline recognition and spatial localization based on multi-view 2D GPR images
Dec 24, 2025To address the issues of weak correlation between multi-view features, low recognition accuracy of small-scale targets, and insufficient robustness in complex scenarios in underground pipeline detection using 3D GPR, this paper proposes a 3D pipeline intelligent detection framework. First, based on a B/C/D-Scan three-view joint analysis strategy, a three-dimensional pipeline three-view feature evaluation method is established by cross-validating forward simulation results obtained using FDTD methods with actual measurement data. Second, the DCO-YOLO framework is proposed, which integrates DySample, CGLU, and OutlookAttention cross-dimensional correlation mechanisms into the original YOLOv11 algorithm, significantly improving the small-scale pipeline edge feature extraction capability. Furthermore, a 3D-DIoU spatial feature matching algorithm is proposed, which integrates three-dimensional geometric constraints and center distance penalty terms to achieve automated association of multi-view annotations. The three-view fusion strategy resolves inherent ambiguities in single-view detection. Experiments based on real urban underground pipeline data show that the proposed method achieves accuracy, recall, and mean average precision of 96.2%, 93.3%, and 96.7%, respectively, in complex multi-pipeline scenarios, which are 2.0%, 2.1%, and 0.9% higher than the baseline model. Ablation experiments validated the synergistic optimization effect of the dynamic feature enhancement module and Grad-CAM++ heatmap visualization demonstrated that the improved model significantly enhanced its ability to focus on pipeline geometric features. This study integrates deep learning optimization strategies with the physical characteristics of 3D GPR, offering an efficient and reliable novel technical framework for the intelligent recognition and localization of underground pipelines.
DMA: Online RAG Alignment with Human Feedback
Nov 06, 2025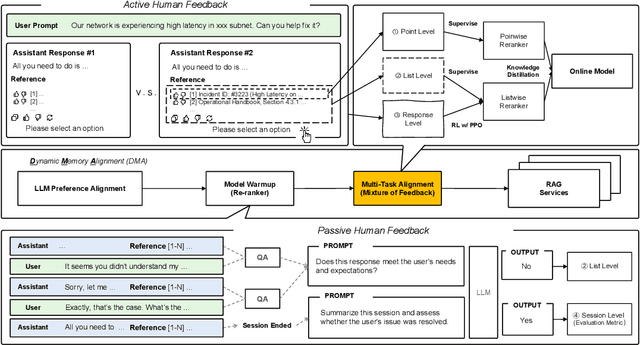

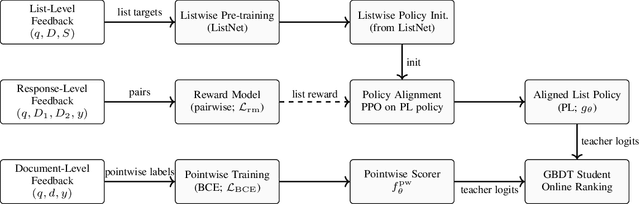
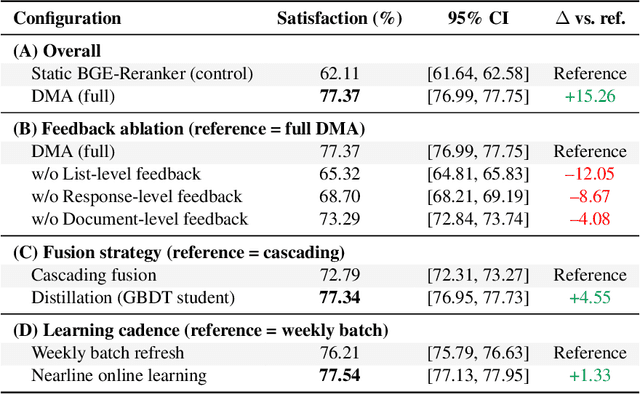
Retrieval-augmented generation (RAG) systems often rely on static retrieval, limiting adaptation to evolving intent and content drift. We introduce Dynamic Memory Alignment (DMA), an online learning framework that systematically incorporates multi-granularity human feedback to align ranking in interactive settings. DMA organizes document-, list-, and response-level signals into a coherent learning pipeline: supervised training for pointwise and listwise rankers, policy optimization driven by response-level preferences, and knowledge distillation into a lightweight scorer for low-latency serving. Throughout this paper, memory refers to the model's working memory, which is the entire context visible to the LLM for In-Context Learning. We adopt a dual-track evaluation protocol mirroring deployment: (i) large-scale online A/B ablations to isolate the utility of each feedback source, and (ii) few-shot offline tests on knowledge-intensive benchmarks. Online, a multi-month industrial deployment further shows substantial improvements in human engagement. Offline, DMA preserves competitive foundational retrieval while yielding notable gains on conversational QA (TriviaQA, HotpotQA). Taken together, these results position DMA as a principled approach to feedback-driven, real-time adaptation in RAG without sacrificing baseline capability.
Optimizing Efficiency of Mixed Traffic through Reinforcement Learning: A Topology-Independent Approach and Benchmark
Jan 28, 2025



This paper presents a mixed traffic control policy designed to optimize traffic efficiency across diverse road topologies, addressing issues of congestion prevalent in urban environments. A model-free reinforcement learning (RL) approach is developed to manage large-scale traffic flow, using data collected by autonomous vehicles to influence human-driven vehicles. A real-world mixed traffic control benchmark is also released, which includes 444 scenarios from 20 countries, representing a wide geographic distribution and covering a variety of scenarios and road topologies. This benchmark serves as a foundation for future research, providing a realistic simulation environment for the development of effective policies. Comprehensive experiments demonstrate the effectiveness and adaptability of the proposed method, achieving better performance than existing traffic control methods in both intersection and roundabout scenarios. To the best of our knowledge, this is the first project to introduce a real-world complex scenarios mixed traffic control benchmark. Videos and code of our work are available at https://sites.google.com/berkeley.edu/mixedtrafficplus/home
Learning to Change: Choreographing Mixed Traffic Through Lateral Control and Hierarchical Reinforcement Learning
Mar 21, 2024



The management of mixed traffic that consists of robot vehicles (RVs) and human-driven vehicles (HVs) at complex intersections presents a multifaceted challenge. Traditional signal controls often struggle to adapt to dynamic traffic conditions and heterogeneous vehicle types. Recent advancements have turned to strategies based on reinforcement learning (RL), leveraging its model-free nature, real-time operation, and generalizability over different scenarios. We introduce a hierarchical RL framework to manage mixed traffic through precise longitudinal and lateral control of RVs. Our proposed hierarchical framework combines the state-of-the-art mixed traffic control algorithm as a high level decision maker to improve the performance and robustness of the whole system. Our experiments demonstrate that the framework can reduce the average waiting time by up to 54% compared to the state-of-the-art mixed traffic control method. When the RV penetration rate exceeds 60%, our technique consistently outperforms conventional traffic signal control programs in terms of the average waiting time for all vehicles at the intersection.
GaussianGrasper: 3D Language Gaussian Splatting for Open-vocabulary Robotic Grasping
Mar 14, 2024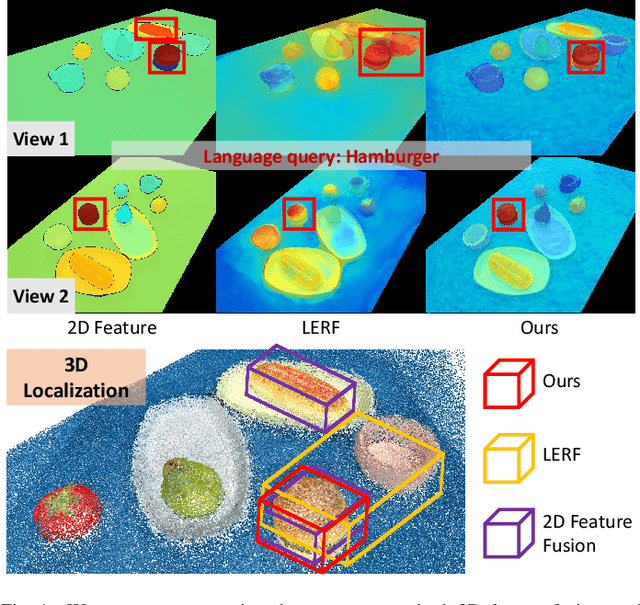
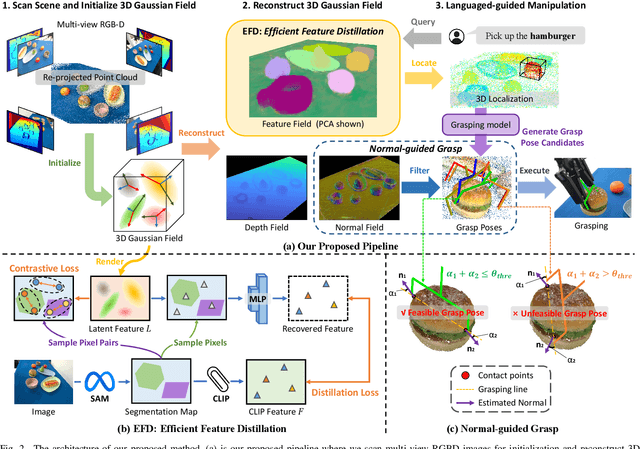
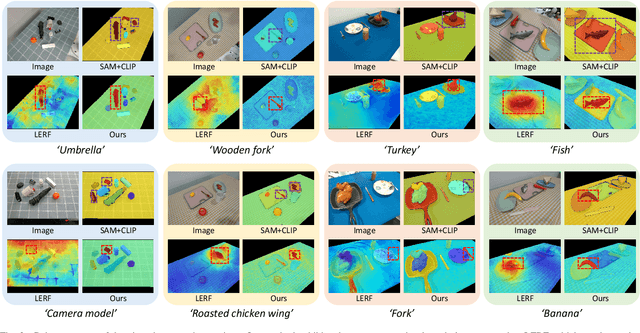

Constructing a 3D scene capable of accommodating open-ended language queries, is a pivotal pursuit, particularly within the domain of robotics. Such technology facilitates robots in executing object manipulations based on human language directives. To tackle this challenge, some research efforts have been dedicated to the development of language-embedded implicit fields. However, implicit fields (e.g. NeRF) encounter limitations due to the necessity of processing a large number of input views for reconstruction, coupled with their inherent inefficiencies in inference. Thus, we present the GaussianGrasper, which utilizes 3D Gaussian Splatting to explicitly represent the scene as a collection of Gaussian primitives. Our approach takes a limited set of RGB-D views and employs a tile-based splatting technique to create a feature field. In particular, we propose an Efficient Feature Distillation (EFD) module that employs contrastive learning to efficiently and accurately distill language embeddings derived from foundational models. With the reconstructed geometry of the Gaussian field, our method enables the pre-trained grasping model to generate collision-free grasp pose candidates. Furthermore, we propose a normal-guided grasp module to select the best grasp pose. Through comprehensive real-world experiments, we demonstrate that GaussianGrasper enables robots to accurately query and grasp objects with language instructions, providing a new solution for language-guided manipulation tasks. Data and codes can be available at https://github.com/MrSecant/GaussianGrasper.