 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Anomaly Detection and Search via Reinforcement Learning
Aug 31, 2022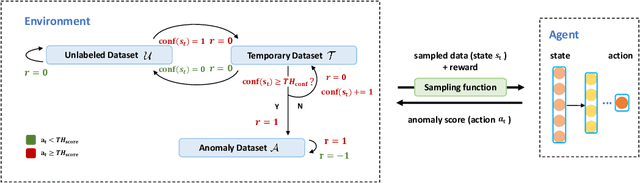
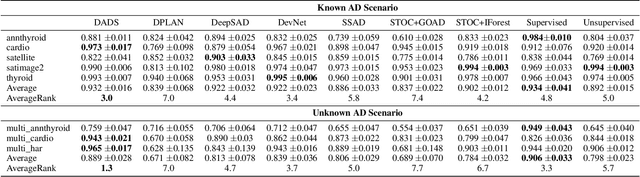
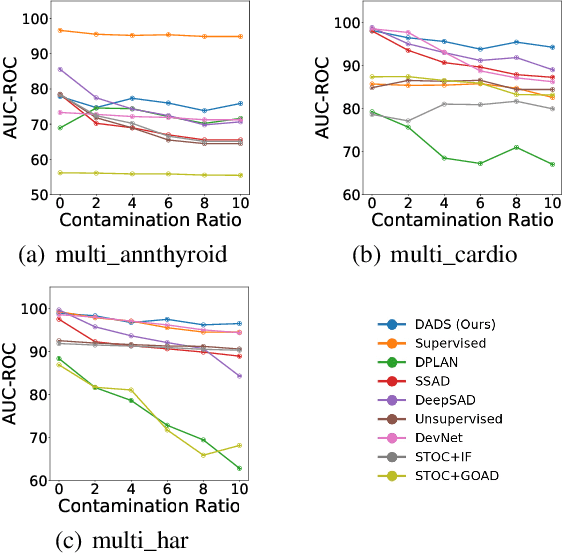
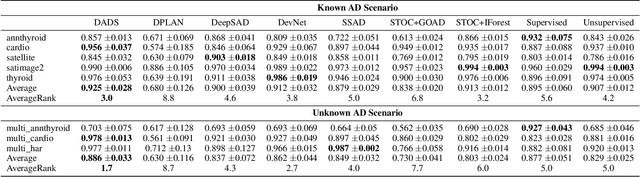
Semi-supervised Anomaly Detection (AD) is a kind of data mining task which aims at learning features from partially-labeled datasets to help detect outliers. In this paper, we classify existing semi-supervised AD methods into two categories: unsupervised-based and supervised-based, and point out that most of them suffer from insufficient exploitation of labeled data and under-exploration of unlabeled data. To tackle these problems, we propose Deep Anomaly Detection and Search (DADS), which applies Reinforcement Learning (RL) to balance exploitation and exploration. During the training process, the agent searches for possible anomalies with hierarchically-structured datasets and uses the searched anomalies to enhance performance, which in essence draws lessons from the idea of ensemble learning. Experimentally, we compare DADS with several state-of-the-art methods in the settings of leveraging labeled known anomalies to detect both other known anomalies and unknown anomalies. Results show that DADS can efficiently and precisely search anomalies from unlabeled data and learn from them, thus achieving good performance.
A Concept and Argumentation based Interpretable Model in High Risk Domains
Aug 17, 2022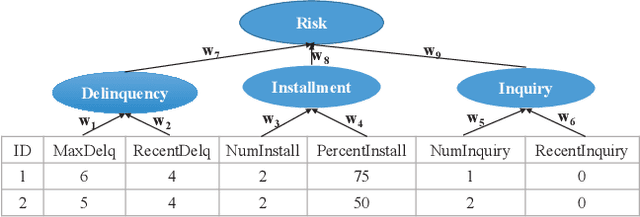

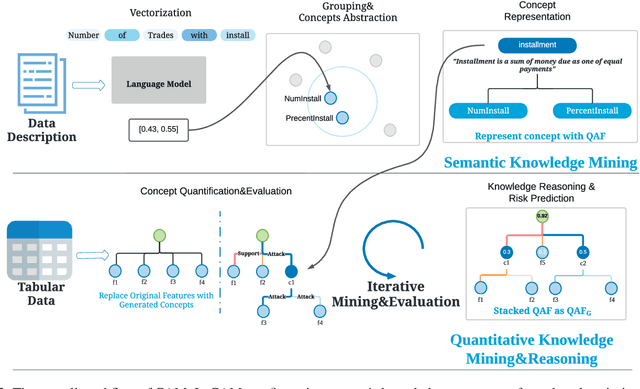
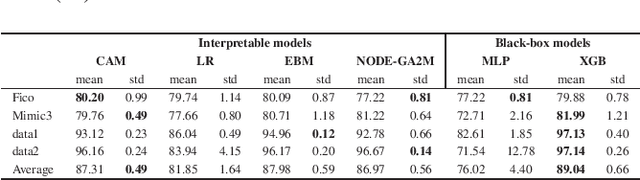
Interpretability has become an essential topic for artificial intelligence in some high-risk domains such as healthcare, bank and security. For commonly-used tabular data, traditional methods trained end-to-end machine learning models with numerical and categorical data only, and did not leverage human understandable knowledge such as data descriptions. Yet mining human-level knowledge from tabular data and using it for prediction remain a challenge. Therefore, we propose a concept and argumentation based model (CAM) that includes the following two components: a novel concept mining method to obtain human understandable concepts and their relations from both descriptions of features and the underlying data, and a quantitative argumentation-based method to do knowledge representation and reasoning. As a result of it, CAM provides decisions that are based on human-level knowledge and the reasoning process is intrinsically interpretable. Finally, to visualize the purposed interpretable model, we provide a dialogical explanation that contain dominated reasoning path within CAM. Experimental results on both open source benchmark dataset and real-word business dataset show that (1) CAM is transparent and interpretable, and the knowledge inside the CAM is coherent with human understanding; (2) Our interpretable approach can reach competitive results comparing with other state-of-art models.
Knowledge Amalgamation for Object Detection with Transformers
Mar 07, 2022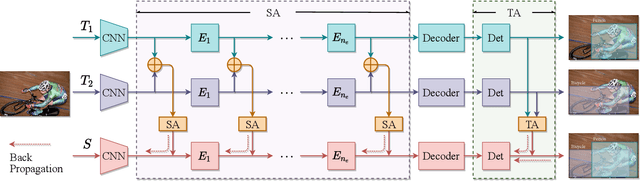


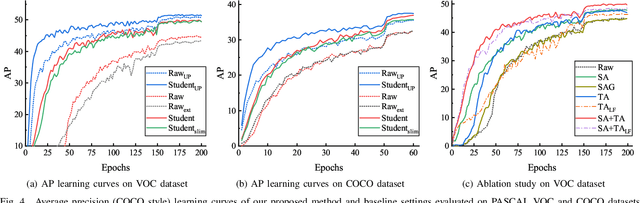
Knowledge amalgamation (KA) is a novel deep model reusing task aiming to transfer knowledge from several well-trained teachers to a multi-talented and compact student. Currently, most of these approaches are tailored for convolutional neural networks (CNNs). However, there is a tendency that transformers, with a completely different architecture, are starting to challenge the domination of CNNs in many computer vision tasks. Nevertheless, directly applying the previous KA methods to transformers leads to severe performance degradation. In this work, we explore a more effective KA scheme for transformer-based object detection models. Specifically, considering the architecture characteristics of transformers, we propose to dissolve the KA into two aspects: sequence-level amalgamation (SA) and task-level amalgamation (TA). In particular, a hint is generated within the sequence-level amalgamation by concatenating teacher sequences instead of redundantly aggregating them to a fixed-size one as previous KA works. Besides, the student learns heterogeneous detection tasks through soft targets with efficiency in the task-level amalgamation. Extensive experiments on PASCAL VOC and COCO have unfolded that the sequence-level amalgamation significantly boosts the performance of students, while the previous methods impair the students. Moreover, the transformer-based students excel in learning amalgamated knowledge, as they have mastered heterogeneous detection tasks rapidly and achieved superior or at least comparable performance to those of the teachers in their specializations.
Personalized Image Semantic Segmentation
Aug 12, 2021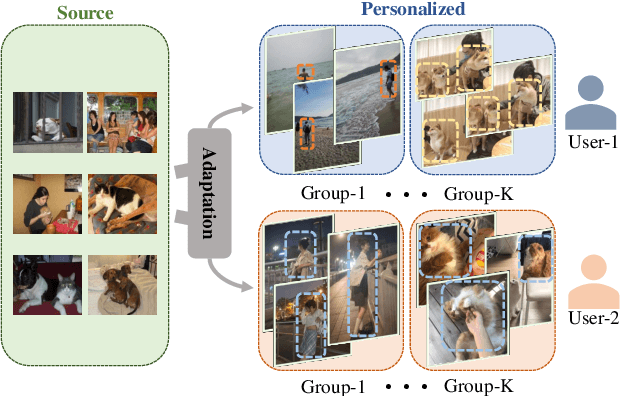
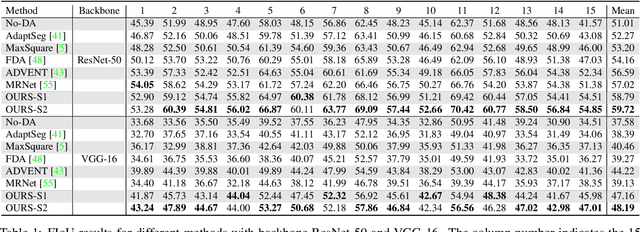
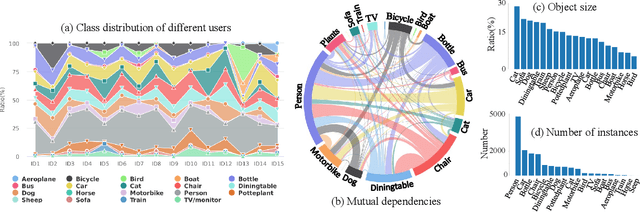
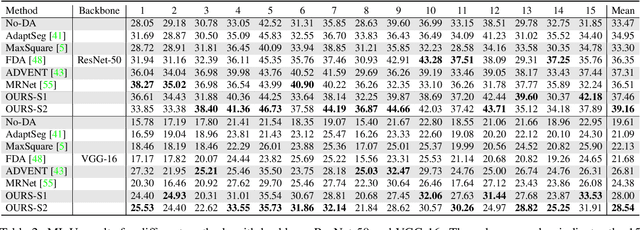
Semantic segmentation models trained on public datasets have achieved great success in recent years. However, these models didn't consider the personalization issue of segmentation though it is important in practice. In this paper, we address the problem of personalized image segmentation. The objective is to generate more accurate segmentation results on unlabeled personalized images by investigating the data's personalized traits. To open up future research in this area, we collect a large dataset containing various users' personalized images called PIS (Personalized Image Semantic Segmentation). We also survey some recent researches related to this problem and report their performance on our dataset. Furthermore, by observing the correlation among a user's personalized images, we propose a baseline method that incorporates the inter-image context when segmenting certain images. Extensive experiments show that our method outperforms the existing methods on the proposed dataset. The code and the PIS dataset will be made publicly available.
DEPARA: Deep Attribution Graph for Deep Knowledge Transferability
Mar 17, 2020
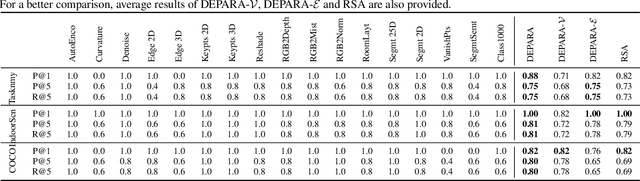


Exploring the intrinsic interconnections between the knowledge encoded in PRe-trained Deep Neural Networks (PR-DNNs) of heterogeneous tasks sheds light on their mutual transferability, and consequently enables knowledge transfer from one task to another so as to reduce the training effort of the latter. In this paper, we propose the DEeP Attribution gRAph (DEPARA) to investigate the transferability of knowledge learned from PR-DNNs. In DEPARA, nodes correspond to the inputs and are represented by their vectorized attribution maps with regards to the outputs of the PR-DNN. Edges denote the relatedness between inputs and are measured by the similarity of their features extracted from the PR-DNN. The knowledge transferability of two PR-DNNs is measured by the similarity of their corresponding DEPARAs. We apply DEPARA to two important yet under-studied problems in transfer learning: pre-trained model selection and layer selection. Extensive experiments are conducted to demonstrate the effectiveness and superiority of the proposed method in solving both these problems. Code, data and models reproducing the results in this paper are available at \url{https://github.com/zju-vipa/DEPARA}.
Class Regularization: Improve Few-shot Image Classification by Reducing Meta Shift
Dec 18, 2019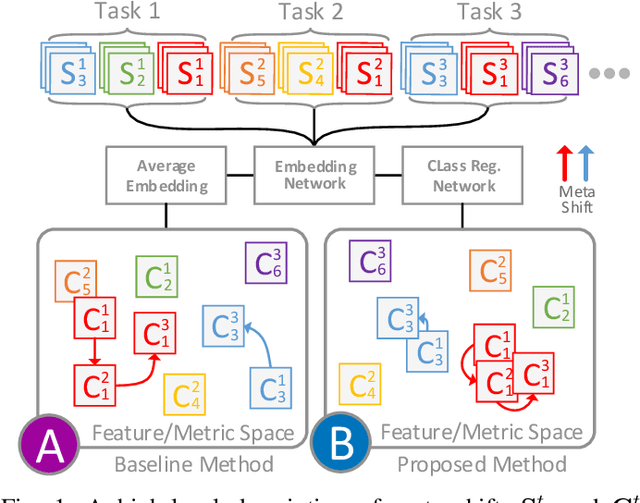
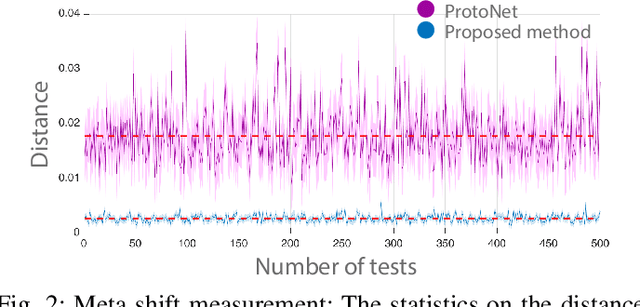

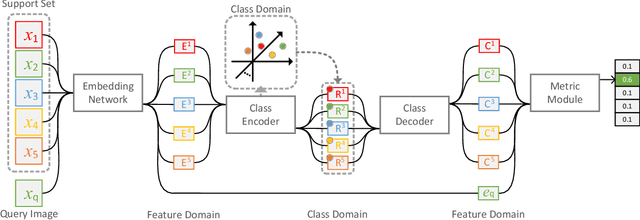
Few-shot image classification requires the classifier to robustly cope with unseen classes even if there are only a few samples for each class. Recent advances benefit from the meta-learning process where episodic tasks are formed to train a model that can adapt to class change. However, these tasks are independent to each other and existing works mainly rely on limited samples of individual support set in a single meta task. This strategy leads to severe meta shift issues across multiple tasks, meaning the learned prototypes or class descriptors are not stable as each task only involves their own support set. To avoid this problem, we propose a concise Class Regularization Network which aggregates the embedding features of all samples in the entire training set and further regularizes the generated class descriptor. The key is to train a class encoder and decoder structure that can encode the embedding sample features into a class domain with trained class basis, and generate a more stable and general class descriptor from the decoder. We evaluate our work by extensive comparisons with previous methods on two benchmark datasets (MiniImageNet and CUB). The results show that our method achieves state-of-the-art performance over previous work.
Self-Supervised Learning For Few-Shot Image Classification
Nov 14, 2019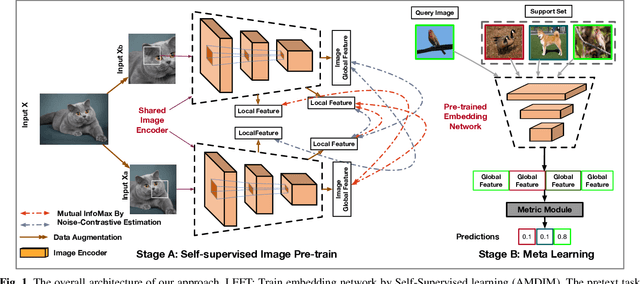
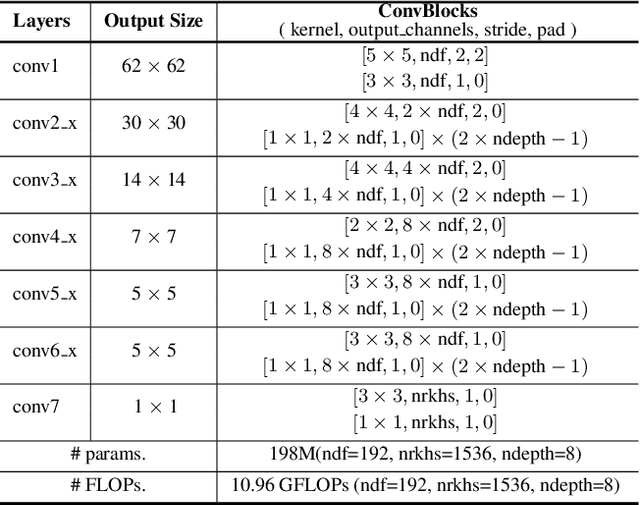
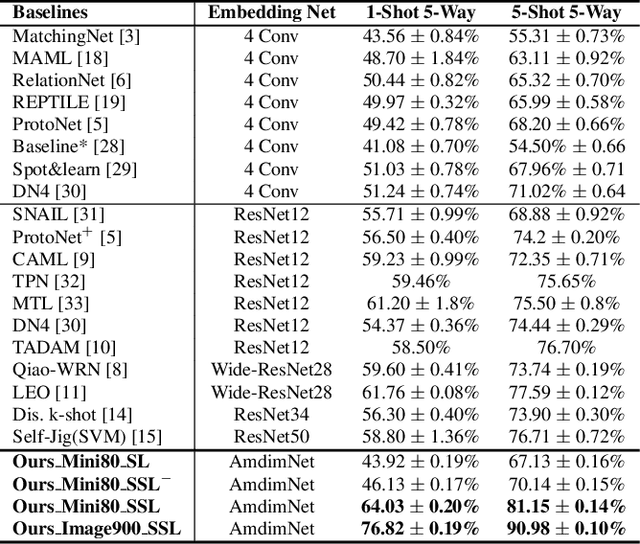
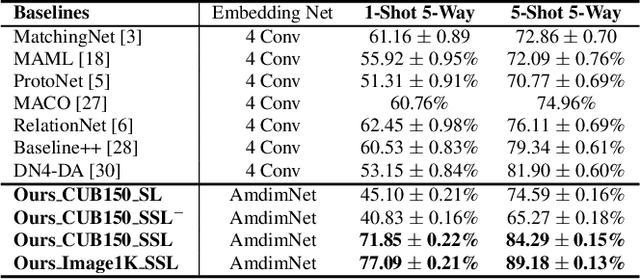
Few-shot image classification aims to classify unseen classes with limited labeled samples. Recent works benefit from the meta-learning process with episodic tasks and can fast adapt to class from training to testing. Due to the limited number of samples for each task, the initial embedding network for meta learning becomes an essential component and can largely affects the performance in practice. To this end, many pre-trained methods have been proposed, and most of them are trained in supervised way with limited transfer ability for unseen classes. In this paper, we proposed to train a more generalized embedding network with self-supervised learning (SSL) which can provide slow and robust representation for downstream tasks by learning from the data itself. We evaluate our work by extensive comparisons with previous baseline methods on two few-shot classification datasets ({\em i.e.,} MiniImageNet and CUB). Based on the evaluation results, the proposed method achieves significantly better performance, i.e., improve 1-shot and 5-shot tasks by nearly \textbf{3\%} and \textbf{4\%} on MiniImageNet, by nearly \textbf{9\%} and \textbf{3\%} on CUB. Moreover, the proposed method can gain the improvement of (\textbf{15\%}, \textbf{13\%}) on MiniImageNet and (\textbf{15\%}, \textbf{8\%}) on CUB by pretraining using more unlabeled data. Our code will be available at \hyperref[https://github.com/phecy/SSL-FEW-SHOT.]{https://github.com/phecy/ssl-few-shot.}
Hierarchical Video Frame Sequence Representation with Deep Convolutional Graph Network
Jun 02, 2019


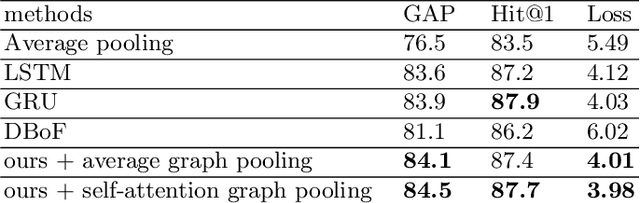
High accuracy video label prediction (classification) models are attributed to large scale data. These data could be frame feature sequences extracted by a pre-trained convolutional-neural-network, which promote the efficiency for creating models. Unsupervised solutions such as feature average pooling, as a simple label-independent parameter-free based method, has limited ability to represent the video. While the supervised methods, like RNN, can greatly improve the recognition accuracy. However, the video length is usually long, and there are hierarchical relationships between frames across events in the video, the performance of RNN based models are decreased. In this paper, we proposes a novel video classification method based on a deep convolutional graph neural network(DCGN). The proposed method utilize the characteristics of the hierarchical structure of the video, and performed multi-level feature extraction on the video frame sequence through the graph network, obtained a video representation re ecting the event semantics hierarchically. We test our model on YouTube-8M Large-Scale Video Understanding dataset, and the result outperforms RNN based benchmarks.
* ECCV 2018
Small Boxes Big Data: A Deep Learning Approach to Optimize Variable Sized Bin Packing
Feb 14, 2017
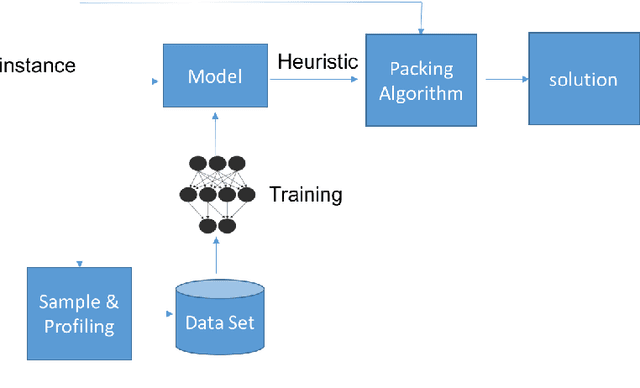
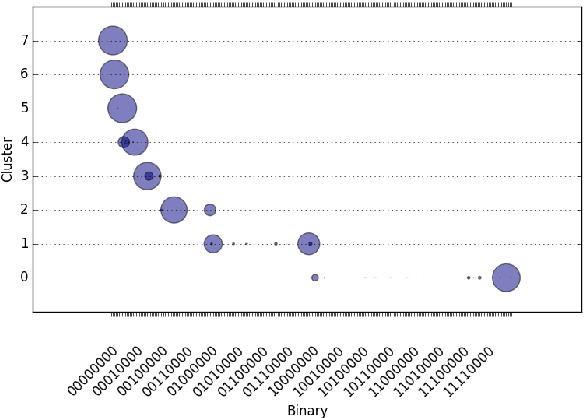
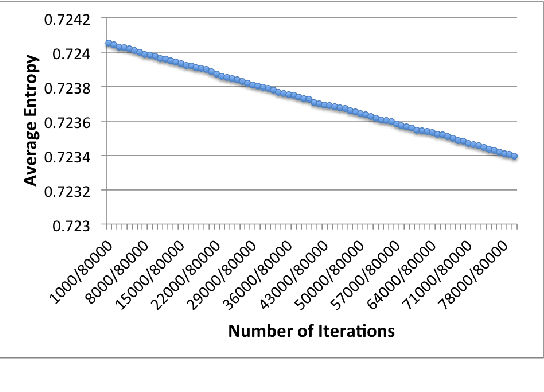
Bin Packing problems have been widely studied because of their broad applications in different domains. Known as a set of NP-hard problems, they have different vari- ations and many heuristics have been proposed for obtaining approximate solutions. Specifically, for the 1D variable sized bin packing problem, the two key sets of optimization heuristics are the bin assignment and the bin allocation. Usually the performance of a single static optimization heuristic can not beat that of a dynamic one which is tailored for each bin packing instance. Building such an adaptive system requires modeling the relationship between bin features and packing perform profiles. The primary drawbacks of traditional AI machine learnings for this task are the natural limitations of feature engineering, such as the curse of dimensionality and feature selection quality. We introduce a deep learning approach to overcome the drawbacks by applying a large training data set, auto feature selection and fast, accurate labeling. We show in this paper how to build such a system by both theoretical formulation and engineering practices. Our prediction system achieves up to 89% training accuracy and 72% validation accuracy to select the best heuristic that can generate a better quality bin packing solution.