 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Makes for Text to 360-degree Panorama Generation with Stable Diffusion?
May 28, 2025Recent prosperity of text-to-image diffusion models, e.g. Stable Diffusion, has stimulated research to adapt them to 360-degree panorama generation. Prior work has demonstrated the feasibility of using conventional low-rank adaptation techniques on pre-trained diffusion models to generate panoramic images. However, the substantial domain gap between perspective and panoramic images raises questions about the underlying mechanisms enabling this empirical success. We hypothesize and examine that the trainable counterparts exhibit distinct behaviors when fine-tuned on panoramic data, and such an adaptation conceals some intrinsic mechanism to leverage the prior knowledge within the pre-trained diffusion models. Our analysis reveals the following: 1) the query and key matrices in the attention modules are responsible for common information that can be shared between the panoramic and perspective domains, thus are less relevant to panorama generation; and 2) the value and output weight matrices specialize in adapting pre-trained knowledge to the panoramic domain, playing a more critical role during fine-tuning for panorama generation. We empirically verify these insights by introducing a simple framework called UniPano, with the objective of establishing an elegant baseline for future research. UniPano not only outperforms existing methods but also significantly reduces memory usage and training time compared to prior dual-branch approaches, making it scalable for end-to-end panorama generation with higher resolution. The code will be released.
v-CLR: View-Consistent Learning for Open-World Instance Segmentation
Apr 02, 2025In this paper, we address the challenging problem of open-world instance segmentation. Existing works have shown that vanilla visual networks are biased toward learning appearance information, \eg texture, to recognize objects. This implicit bias causes the model to fail in detecting novel objects with unseen textures in the open-world setting. To address this challenge, we propose a learning framework, called view-Consistent LeaRning (v-CLR), which aims to enforce the model to learn appearance-invariant representations for robust instance segmentation. In v-CLR, we first introduce additional views for each image, where the texture undergoes significant alterations while preserving the image's underlying structure. We then encourage the model to learn the appearance-invariant representation by enforcing the consistency between object features across different views, for which we obtain class-agnostic object proposals using off-the-shelf unsupervised models that possess strong object-awareness. These proposals enable cross-view object feature matching, greatly reducing the appearance dependency while enhancing the object-awareness. We thoroughly evaluate our method on public benchmarks under both cross-class and cross-dataset settings, achieving state-of-the-art performance. Project page: https://visual-ai.github.io/vclr
Mr. DETR: Instructive Multi-Route Training for Detection Transformers
Dec 13, 2024



Existing methods enhance the training of detection transformers by incorporating an auxiliary one-to-many assignment. In this work, we treat the model as a multi-task framework, simultaneously performing one-to-one and one-to-many predictions. We investigate the roles of each component in the transformer decoder across these two training targets, including self-attention, cross-attention, and feed-forward network. Our empirical results demonstrate that any independent component in the decoder can effectively learn both targets simultaneously, even when other components are shared. This finding leads us to propose a multi-route training mechanism, featuring a primary route for one-to-one prediction and two auxiliary training routes for one-to-many prediction. We enhance the training mechanism with a novel instructive self-attention that dynamically and flexibly guides object queries for one-to-many prediction. The auxiliary routes are removed during inference, ensuring no impact on model architecture or inference cost. We conduct extensive experiments on various baselines, achieving consistent improvements as shown in Figure 1.
Representation Compensation Networks for Continual Semantic Segmentation
Mar 10, 2022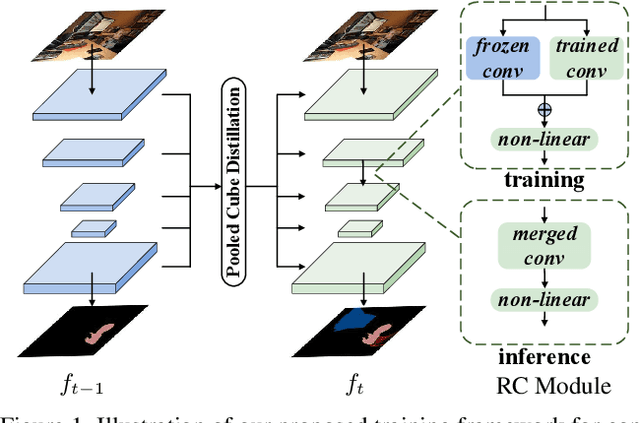
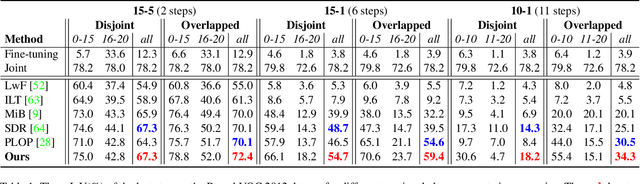
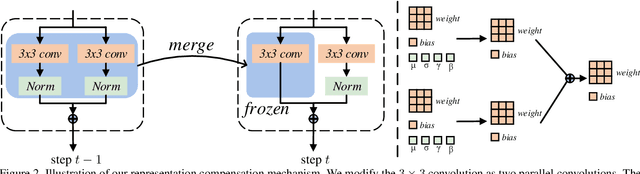

In this work, we study the continual semantic segmentation problem, where the deep neural networks are required to incorporate new classes continually without catastrophic forgetting. We propose to use a structural re-parameterization mechanism, named representation compensation (RC) module, to decouple the representation learning of both old and new knowledge. The RC module consists of two dynamically evolved branches with one frozen and one trainable. Besides, we design a pooled cube knowledge distillation strategy on both spatial and channel dimensions to further enhance the plasticity and stability of the model. We conduct experiments on two challenging continual semantic segmentation scenarios, continual class segmentation and continual domain segmentation. Without any extra computational overhead and parameters during inference, our method outperforms state-of-the-art performance. The code is available at \url{https://github.com/zhangchbin/RCIL}.
Personalized Image Semantic Segmentation
Aug 12, 2021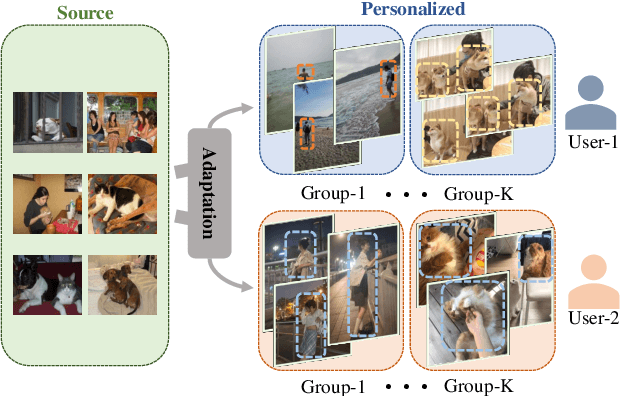
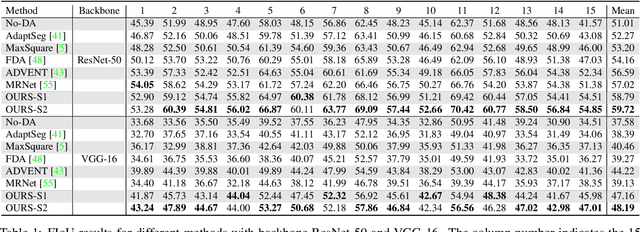
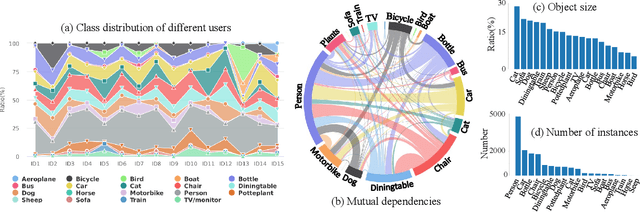
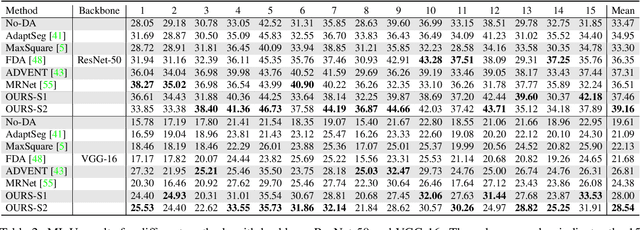
Semantic segmentation models trained on public datasets have achieved great success in recent years. However, these models didn't consider the personalization issue of segmentation though it is important in practice. In this paper, we address the problem of personalized image segmentation. The objective is to generate more accurate segmentation results on unlabeled personalized images by investigating the data's personalized traits. To open up future research in this area, we collect a large dataset containing various users' personalized images called PIS (Personalized Image Semantic Segmentation). We also survey some recent researches related to this problem and report their performance on our dataset. Furthermore, by observing the correlation among a user's personalized images, we propose a baseline method that incorporates the inter-image context when segmenting certain images. Extensive experiments show that our method outperforms the existing methods on the proposed dataset. The code and the PIS dataset will be made publicly available.
Delving Deep into Label Smoothing
Nov 25, 2020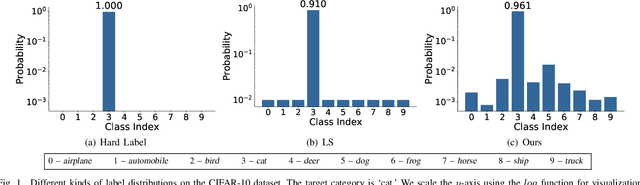
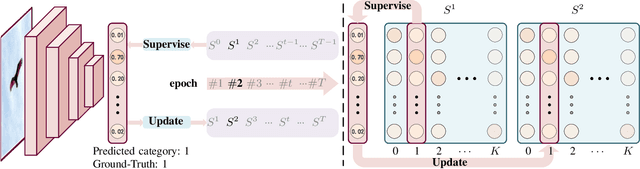

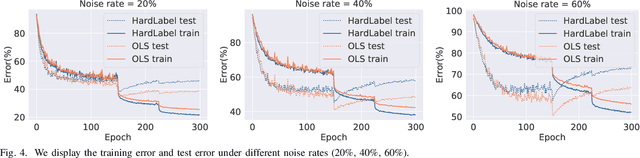
Label smoothing is an effective regularization tool for deep neural networks (DNNs), which generates soft labels by applying a weighted average between the uniform distribution and the hard label. It is often used to reduce the overfitting problem of training DNNs and further improve classification performance. In this paper, we aim to investigate how to generate more reliable soft labels. We present an Online Label Smoothing (OLS) strategy, which generates soft labels based on the statistics of the model prediction for the target category. The proposed OLS constructs a more reasonable probability distribution between the target categories and non-target categories to supervise DNNs. Experiments demonstrate that based on the same classification models, the proposed approach can effectively improve the classification performance on CIFAR-100, ImageNet, and fine-grained datasets. Additionally, the proposed method can significantly improve the robustness of DNN models to noisy labels compared to current label smoothing approaches. The code will be made publicly available.