 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClinical Cognition Alignment for Gastrointestinal Diagnosis with Multimodal LLMs
Mar 21, 2026Multimodal Large Language Models (MLLMs) have demonstrated remarkable potential in medical image analysis. However, their application in gastrointestinal endoscopy is currently hindered by two critical limitations: the misalignment between general model reasoning and standardized clinical cognitive pathways, and the lack of causal association between visual features and diagnostic outcomes. In this paper, we propose a novel Clinical-Cognitive-Aligned (CogAlign) framework to address these challenges. First, we endow the model with rigorous clinical analytical capabilities by constructing the hierarchical clinical cognition dataset and employing Supervised Fine-Tuning (SFT). Unlike conventional approaches, this strategy internalizes the hierarchical diagnostic logic of experts, ranging from anatomical localization and morphological evaluation to microvascular analysis, directly into the model. Second, to eliminate visual bias, we provide a theoretical analysis demonstrating that standard supervised tuning inevitably converges to spurious background correlations. Guided by this insight, we propose a counterfactual-driven reinforcement learning strategy to enforce causal rectification. By generating counterfactual normal samples via lesion masking and optimizing through clinical-cognition-centric rewards, we constrain the model to strictly ground its diagnosis in causal lesion features. Extensive experiments demonstrate that our approach achieves State-of-the-Art (SoTA) performance across multiple benchmarks, significantly enhancing diagnostic accuracy in complex clinical scenarios. All source code and datasets will be made publicly available.
VisionNVS: Self-Supervised Inpainting for Novel View Synthesis under the Virtual-Shift Paradigm
Mar 18, 2026A fundamental bottleneck in Novel View Synthesis (NVS) for autonomous driving is the inherent supervision gap on novel trajectories: models are tasked with synthesizing unseen views during inference, yet lack ground truth images for these shifted poses during training. In this paper, we propose VisionNVS, a camera-only framework that fundamentally reformulates view synthesis from an ill-posed extrapolation problem into a self-supervised inpainting task. By introducing a ``Virtual-Shift'' strategy, we use monocular depth proxies to simulate occlusion patterns and map them onto the original view. This paradigm shift allows the use of raw, recorded images as pixel-perfect supervision, effectively eliminating the domain gap inherent in previous approaches. Furthermore, we address spatial consistency through a Pseudo-3D Seam Synthesis strategy, which integrates visual data from adjacent cameras during training to explicitly model real-world photometric discrepancies and calibration errors. Experiments demonstrate that VisionNVS achieves superior geometric fidelity and visual quality compared to LiDAR-dependent baselines, offering a robust solution for scalable driving simulation.
WildSVG: Towards Reliable SVG Generation Under Real-Word Conditions
Feb 24, 2026We introduce the task of SVG extraction, which consists in translating specific visual inputs from an image into scalable vector graphics. Existing multimodal models achieve strong results when generating SVGs from clean renderings or textual descriptions, but they fall short in real-world scenarios where natural images introduce noise, clutter, and domain shifts. A central challenge in this direction is the lack of suitable benchmarks. To address this need, we introduce the WildSVG Benchmark, formed by two complementary datasets: Natural WildSVG, built from real images containing company logos paired with their SVG annotations, and Synthetic WildSVG, which blends complex SVG renderings into real scenes to simulate difficult conditions. Together, these resources provide the first foundation for systematic benchmarking SVG extraction. We benchmark state-of-the-art multimodal models and find that current approaches perform well below what is needed for reliable SVG extraction in real scenarios. Nonetheless, iterative refinement methods point to a promising path forward, and model capabilities are steadily improving
Evaluating Low-Light Image Enhancement Across Multiple Intensity Levels
Nov 19, 2025Imaging in low-light environments is challenging due to reduced scene radiance, which leads to elevated sensor noise and reduced color saturation. Most learning-based low-light enhancement methods rely on paired training data captured under a single low-light condition and a well-lit reference. The lack of radiance diversity limits our understanding of how enhancement techniques perform across varying illumination intensities. We introduce the Multi-Illumination Low-Light (MILL) dataset, containing images captured at diverse light intensities under controlled conditions with fixed camera settings and precise illuminance measurements. MILL enables comprehensive evaluation of enhancement algorithms across variable lighting conditions. We benchmark several state-of-the-art methods and reveal significant performance variations across intensity levels. Leveraging the unique multi-illumination structure of our dataset, we propose improvements that enhance robustness across diverse illumination scenarios. Our modifications achieve up to 10 dB PSNR improvement for DSLR and 2 dB for the smartphone on Full HD images.
Semantic Causality-Aware Vision-Based 3D Occupancy Prediction
Sep 10, 2025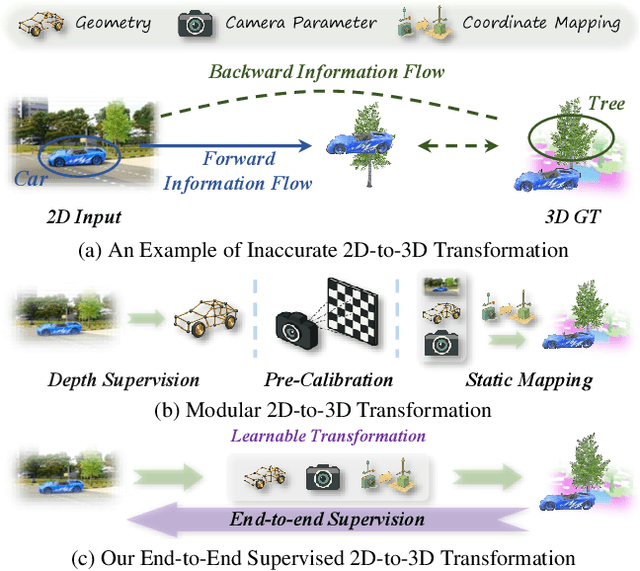

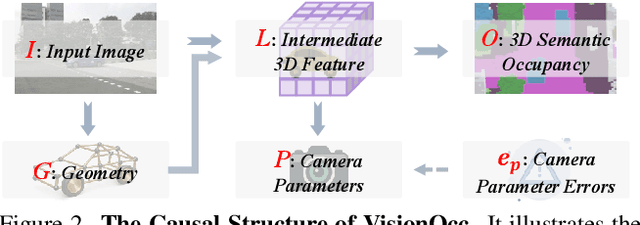
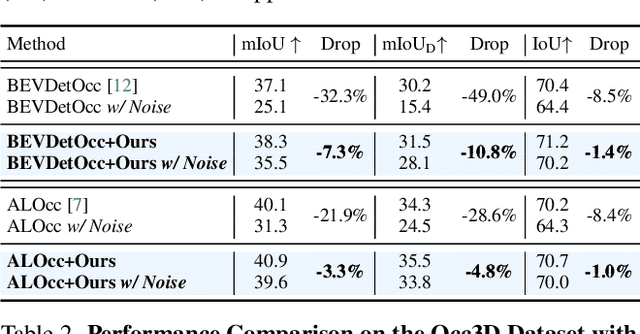
Vision-based 3D semantic occupancy prediction is a critical task in 3D vision that integrates volumetric 3D reconstruction with semantic understanding. Existing methods, however, often rely on modular pipelines. These modules are typically optimized independently or use pre-configured inputs, leading to cascading errors. In this paper, we address this limitation by designing a novel causal loss that enables holistic, end-to-end supervision of the modular 2D-to-3D transformation pipeline. Grounded in the principle of 2D-to-3D semantic causality, this loss regulates the gradient flow from 3D voxel representations back to the 2D features. Consequently, it renders the entire pipeline differentiable, unifying the learning process and making previously non-trainable components fully learnable. Building on this principle, we propose the Semantic Causality-Aware 2D-to-3D Transformation, which comprises three components guided by our causal loss: Channel-Grouped Lifting for adaptive semantic mapping, Learnable Camera Offsets for enhanced robustness against camera perturbations, and Normalized Convolution for effective feature propagation. Extensive experiments demonstrate that our method achieves state-of-the-art performance on the Occ3D benchmark, demonstrating significant robustness to camera perturbations and improved 2D-to-3D semantic consistency.
Rethinking Temporal Fusion with a Unified Gradient Descent View for 3D Semantic Occupancy Prediction
Apr 18, 2025We present GDFusion, a temporal fusion method for vision-based 3D semantic occupancy prediction (VisionOcc). GDFusion opens up the underexplored aspects of temporal fusion within the VisionOcc framework, focusing on both temporal cues and fusion strategies. It systematically examines the entire VisionOcc pipeline, identifying three fundamental yet previously overlooked temporal cues: scene-level consistency, motion calibration, and geometric complementation. These cues capture diverse facets of temporal evolution and make distinct contributions across various modules in the VisionOcc framework. To effectively fuse temporal signals across heterogeneous representations, we propose a novel fusion strategy by reinterpreting the formulation of vanilla RNNs. This reinterpretation leverages gradient descent on features to unify the integration of diverse temporal information, seamlessly embedding the proposed temporal cues into the network. Extensive experiments on nuScenes demonstrate that GDFusion significantly outperforms established baselines. Notably, on Occ3D benchmark, it achieves 1.4\%-4.8\% mIoU improvements and reduces memory consumption by 27\%-72\%.
You Only Click Once: Single Point Weakly Supervised 3D Instance Segmentation for Autonomous Driving
Feb 28, 2025Outdoor LiDAR point cloud 3D instance segmentation is a crucial task in autonomous driving. However, it requires laborious human efforts to annotate the point cloud for training a segmentation model. To address this challenge, we propose a YoCo framework, which generates 3D pseudo labels using minimal coarse click annotations in the bird's eye view plane. It is a significant challenge to produce high-quality pseudo labels from sparse annotations. Our YoCo framework first leverages vision foundation models combined with geometric constraints from point clouds to enhance pseudo label generation. Second, a temporal and spatial-based label updating module is designed to generate reliable updated labels. It leverages predictions from adjacent frames and utilizes the inherent density variation of point clouds (dense near, sparse far). Finally, to further improve label quality, an IoU-guided enhancement module is proposed, replacing pseudo labels with high-confidence and high-IoU predictions. Experiments on the Waymo dataset demonstrate YoCo's effectiveness and generality, achieving state-of-the-art performance among weakly supervised methods and surpassing fully supervised Cylinder3D. Additionally, the YoCo is suitable for various networks, achieving performance comparable to fully supervised methods with minimal fine-tuning using only 0.8% of the fully labeled data, significantly reducing annotation costs.
Generative Planning with 3D-vision Language Pre-training for End-to-End Autonomous Driving
Jan 15, 2025



Autonomous driving is a challenging task that requires perceiving and understanding the surrounding environment for safe trajectory planning. While existing vision-based end-to-end models have achieved promising results, these methods are still facing the challenges of vision understanding, decision reasoning and scene generalization. To solve these issues, a generative planning with 3D-vision language pre-training model named GPVL is proposed for end-to-end autonomous driving. The proposed paradigm has two significant aspects. On one hand, a 3D-vision language pre-training module is designed to bridge the gap between visual perception and linguistic understanding in the bird's eye view. On the other hand, a cross-modal language model is introduced to generate holistic driving decisions and fine-grained trajectories with perception and navigation information in an auto-regressive manner. Experiments on the challenging nuScenes dataset demonstrate that the proposed scheme achieves excellent performances compared with state-of-the-art methods. Besides, the proposed GPVL presents strong generalization ability and real-time potential when handling high-level commands in various scenarios. It is believed that the effective, robust and efficient performance of GPVL is crucial for the practical application of future autonomous driving systems. Code is available at https://github.com/ltp1995/GPVL
Cross-Modal Mapping: Eliminating the Modality Gap for Few-Shot Image Classification
Dec 28, 2024



In few-shot image classification tasks, methods based on pretrained vision-language models (such as CLIP) have achieved significant progress. Many existing approaches directly utilize visual or textual features as class prototypes, however, these features fail to adequately represent their respective classes. We identify that this limitation arises from the modality gap inherent in pretrained vision-language models, which weakens the connection between the visual and textual modalities. To eliminate this modality gap and enable textual features to fully represent class prototypes, we propose a simple and efficient Cross-Modal Mapping (CMM) method. This method employs a linear transformation to map image features into the textual feature space, ensuring that both modalities are comparable within the same feature space. Nevertheless, the modality gap diminishes the effectiveness of this mapping. To address this, we further introduce a triplet loss to optimize the spatial relationships between image features and class textual features, allowing class textual features to naturally serve as class prototypes for image features. Experimental results on 11 benchmark demonstrate an average improvement of approximately 3.5% compared to conventional methods and exhibit competitive performance on 4 distribution shift benchmarks.
Light-weight End-to-End Graph Interest Network for CTR Prediction in E-commerce Search
Jun 25, 2024Click-through-rate (CTR) prediction has an essential impact on improving user experience and revenue in e-commerce search. With the development of deep learning, graph-based methods are well exploited to utilize graph structure extracted from user behaviors and other information to help embedding learning. However, most of the previous graph-based methods mainly focus on recommendation scenarios, and therefore their graph structures highly depend on item's sequential information from user behaviors, ignoring query's sequential signal and query-item correlation. In this paper, we propose a new approach named Light-weight End-to-End Graph Interest Network (EGIN) to effectively mine users' search interests and tackle previous challenges. (i) EGIN utilizes query and item's correlation and sequential information from the search system to build a heterogeneous graph for better CTR prediction in e-commerce search. (ii) EGIN's graph embedding learning shares the same training input and is jointly trained with CTR prediction, making the end-to-end framework effortless to deploy in large-scale search systems. The proposed EGIN is composed of three parts: query-item heterogeneous graph, light-weight graph sampling, and multi-interest network. The query-item heterogeneous graph captures correlation and sequential information of query and item efficiently by the proposed light-weight graph sampling. The multi-interest network is well designed to utilize graph embedding to capture various similarity relationships between query and item to enhance the final CTR prediction. We conduct extensive experiments on both public and industrial datasets to demonstrate the effectiveness of the proposed EGIN. At the same time, the training cost of graph learning is relatively low compared with the main CTR prediction task, ensuring efficiency in practical applications.