 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-View Factorizing and Disentangling: A Novel Framework for Incomplete Multi-View Multi-Label Classification
Jan 11, 2025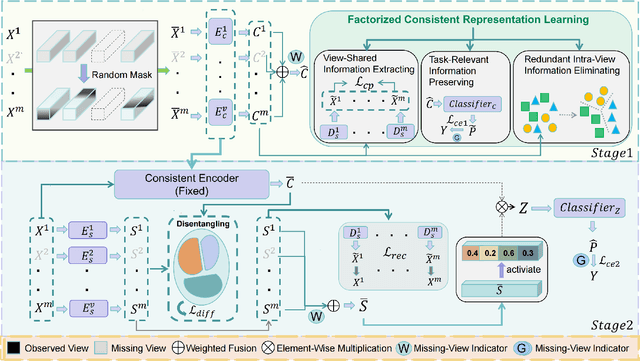
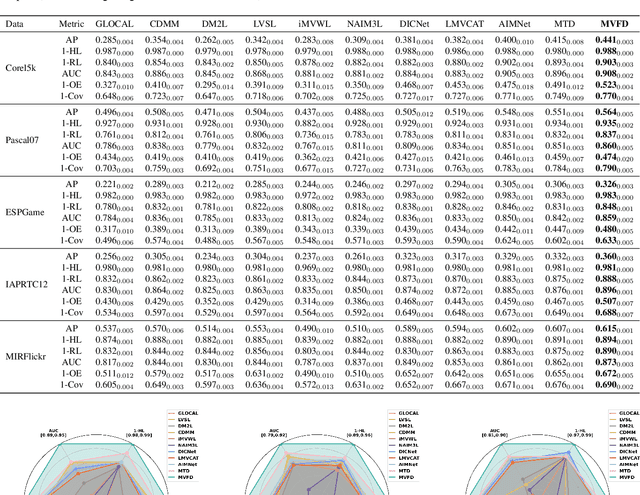
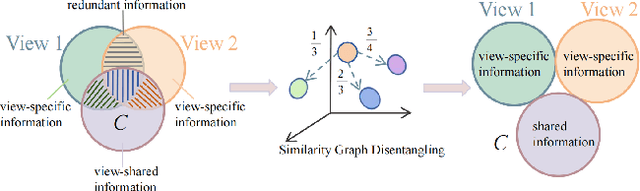
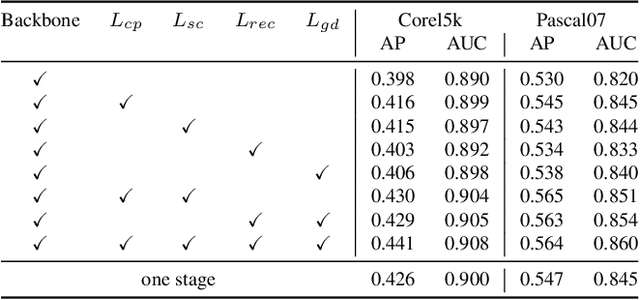
Multi-view multi-label classification (MvMLC) has recently garnered significant research attention due to its wide range of real-world applications. However, incompleteness in views and labels is a common challenge, often resulting from data collection oversights and uncertainties in manual annotation. Furthermore, the task of learning robust multi-view representations that are both view-consistent and view-specific from diverse views still a challenge problem in MvMLC. To address these issues, we propose a novel framework for incomplete multi-view multi-label classification (iMvMLC). Our method factorizes multi-view representations into two independent sets of factors: view-consistent and view-specific, and we correspondingly design a graph disentangling loss to fully reduce redundancy between these representations. Additionally, our framework innovatively decomposes consistent representation learning into three key sub-objectives: (i) how to extract view-shared information across different views, (ii) how to eliminate intra-view redundancy in consistent representations, and (iii) how to preserve task-relevant information. To this end, we design a robust task-relevant consistency learning module that collaboratively learns high-quality consistent representations, leveraging a masked cross-view prediction (MCP) strategy and information theory. Notably, all modules in our framework are developed to function effectively under conditions of incomplete views and labels, making our method adaptable to various multi-view and multi-label datasets. Extensive experiments on five datasets demonstrate that our method outperforms other leading approaches.
Cross-Modal Mapping: Eliminating the Modality Gap for Few-Shot Image Classification
Dec 28, 2024



In few-shot image classification tasks, methods based on pretrained vision-language models (such as CLIP) have achieved significant progress. Many existing approaches directly utilize visual or textual features as class prototypes, however, these features fail to adequately represent their respective classes. We identify that this limitation arises from the modality gap inherent in pretrained vision-language models, which weakens the connection between the visual and textual modalities. To eliminate this modality gap and enable textual features to fully represent class prototypes, we propose a simple and efficient Cross-Modal Mapping (CMM) method. This method employs a linear transformation to map image features into the textual feature space, ensuring that both modalities are comparable within the same feature space. Nevertheless, the modality gap diminishes the effectiveness of this mapping. To address this, we further introduce a triplet loss to optimize the spatial relationships between image features and class textual features, allowing class textual features to naturally serve as class prototypes for image features. Experimental results on 11 benchmark demonstrate an average improvement of approximately 3.5% compared to conventional methods and exhibit competitive performance on 4 distribution shift benchmarks.
Incomplete Multi-view Multi-label Classification via a Dual-level Contrastive Learning Framework
Nov 27, 2024Recently, multi-view and multi-label classification have become significant domains for comprehensive data analysis and exploration. However, incompleteness both in views and labels is still a real-world scenario for multi-view multi-label classification. In this paper, we seek to focus on double missing multi-view multi-label classification tasks and propose our dual-level contrastive learning framework to solve this issue. Different from the existing works, which couple consistent information and view-specific information in the same feature space, we decouple the two heterogeneous properties into different spaces and employ contrastive learning theory to fully disentangle the two properties. Specifically, our method first introduces a two-channel decoupling module that contains a shared representation and a view-proprietary representation to effectively extract consistency and complementarity information across all views. Second, to efficiently filter out high-quality consistent information from multi-view representations, two consistency objectives based on contrastive learning are conducted on the high-level features and the semantic labels, respectively. Extensive experiments on several widely used benchmark datasets demonstrate that the proposed method has more stable and superior classification performance.
Task-Augmented Cross-View Imputation Network for Partial Multi-View Incomplete Multi-Label Classification
Sep 12, 2024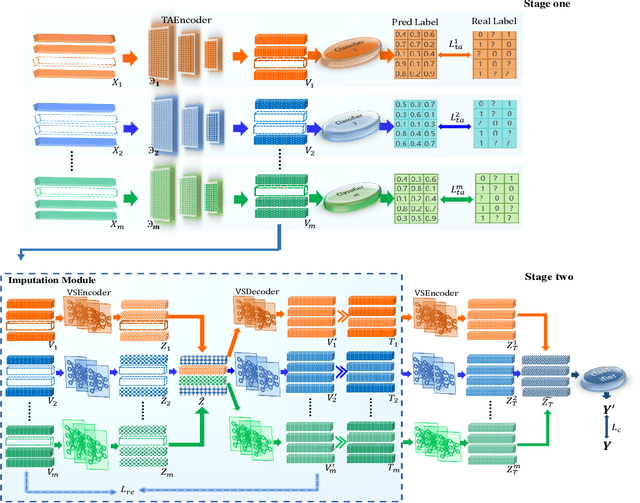
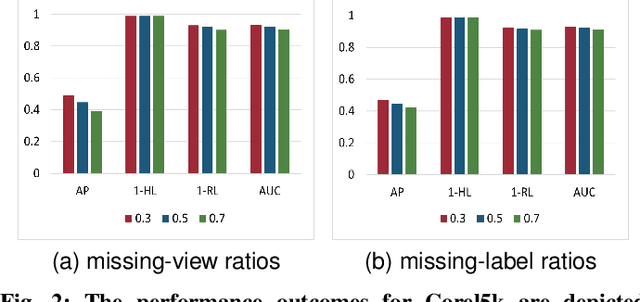
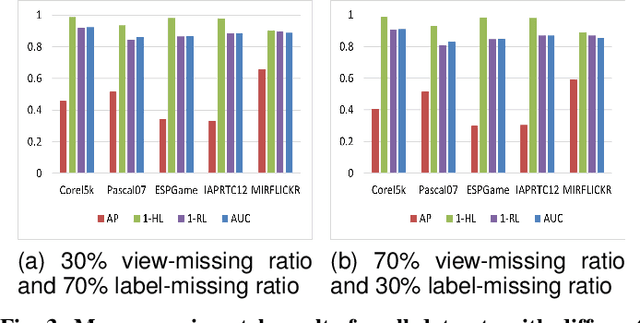
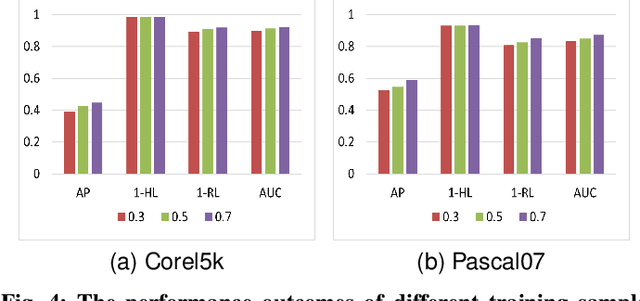
In real-world scenarios, multi-view multi-label learning often encounters the challenge of incomplete training data due to limitations in data collection and unreliable annotation processes. The absence of multi-view features impairs the comprehensive understanding of samples, omitting crucial details essential for classification. To address this issue, we present a task-augmented cross-view imputation network (TACVI-Net) for the purpose of handling partial multi-view incomplete multi-label classification. Specifically, we employ a two-stage network to derive highly task-relevant features to recover the missing views. In the first stage, we leverage the information bottleneck theory to obtain a discriminative representation of each view by extracting task-relevant information through a view-specific encoder-classifier architecture. In the second stage, an autoencoder based multi-view reconstruction network is utilized to extract high-level semantic representation of the augmented features and recover the missing data, thereby aiding the final classification task. Extensive experiments on five datasets demonstrate that our TACVI-Net outperforms other state-of-the-art methods.