 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQ-Hawkeye: Reliable Visual Policy Optimization for Image Quality Assessment
Jan 30, 2026Image Quality Assessment (IQA) predicts perceptual quality scores consistent with human judgments. Recent RL-based IQA methods built on MLLMs focus on generating visual quality descriptions and scores, ignoring two key reliability limitations: (i) although the model's prediction stability varies significantly across training samples, existing GRPO-based methods apply uniform advantage weighting, thereby amplifying noisy signals from unstable samples in gradient updates; (ii) most works emphasize text-grounded reasoning over images while overlooking the model's visual perception ability of image content. In this paper, we propose Q-Hawkeye, an RL-based reliable visual policy optimization framework that redesigns the learning signal through unified Uncertainty-Aware Dynamic Optimization and Perception-Aware Optimization. Q-Hawkeye estimates predictive uncertainty using the variance of predicted scores across multiple rollouts and leverages this uncertainty to reweight each sample's update strength, stabilizing policy optimization. To strengthen perceptual reliability, we construct paired inputs of degraded images and their original images and introduce an Implicit Perception Loss that constrains the model to ground its quality judgments in genuine visual evidence. Extensive experiments demonstrate that Q-Hawkeye outperforms state-of-the-art methods and generalizes better across multiple datasets. The code and models will be made available.
Advancing Adaptive Multi-Stage Video Anomaly Reasoning: A Benchmark Dataset and Method
Jan 15, 2026Recent progress in reasoning capabilities of Multimodal Large Language Models(MLLMs) has highlighted their potential for performing complex video understanding tasks. However, in the domain of Video Anomaly Detection and Understanding (VAD&U), existing MLLM-based methods are largely limited to anomaly localization or post-hoc description, lacking explicit reasoning processes, risk awareness, and decision-oriented interpretation. To address this gap, we define a new task termed Video Anomaly Reasoning (VAR), which elevates video anomaly analysis from descriptive understanding to structured, multi-stage reasoning. VAR explicitly requires models to perform progressive reasoning over anomalous events before answering anomaly-related questions, encompassing visual perception, causal interpretation, and risk-aware decision making. To support this task, we present a new dataset with 8,641 videos, where each video is annotated with diverse question types corresponding to different reasoning depths, totaling more than 50,000 samples, making it one of the largest datasets for video anomaly. The annotations are based on a structured Perception-Cognition-Action Chain-of-Thought (PerCoAct-CoT), which formalizes domain-specific reasoning priors for video anomaly understanding. This design enables systematic evaluation of multi-stage and adaptive anomaly reasoning. In addition, we propose Anomaly-Aware Group Relative Policy Optimization to further enhance reasoning reliability under weak supervision. Building upon the proposed task and dataset, we develop an end-to-end MLLM-based VAR model termed Vad-R1-Plus, which supports adaptive hierarchical reasoning and risk-aware decision making. Extensive experiments demonstrate that the proposed benchmark and method effectively advance the reasoning capabilities of MLLMs on VAR tasks, outperforming both open-source and proprietary baselines.
Diffusion Model Regularized Implicit Neural Representation for CT Metal Artifact Reduction
Dec 09, 2025



Computed tomography (CT) images are often severely corrupted by artifacts in the presence of metals. Existing supervised metal artifact reduction (MAR) approaches suffer from performance instability on known data due to their reliance on limited paired metal-clean data, which limits their clinical applicability. Moreover, existing unsupervised methods face two main challenges: 1) the CT physical geometry is not effectively incorporated into the MAR process to ensure data fidelity; 2) traditional heuristics regularization terms cannot fully capture the abundant prior knowledge available. To overcome these shortcomings, we propose diffusion model regularized implicit neural representation framework for MAR. The implicit neural representation integrates physical constraints and imposes data fidelity, while the pre-trained diffusion model provides prior knowledge to regularize the solution. Experimental results on both simulated and clinical data demonstrate the effectiveness and generalization ability of our method, highlighting its potential to be applied to clinical settings.
Enhancing Multimodal Protein Function Prediction Through Dual-Branch Dynamic Selection with Reconstructive Pre-Training
Nov 06, 2025Multimodal protein features play a crucial role in protein function prediction. However, these features encompass a wide range of information, ranging from structural data and sequence features to protein attributes and interaction networks, making it challenging to decipher their complex interconnections. In this work, we propose a multimodal protein function prediction method (DSRPGO) by utilizing dynamic selection and reconstructive pre-training mechanisms. To acquire complex protein information, we introduce reconstructive pre-training to mine more fine-grained information with low semantic levels. Moreover, we put forward the Bidirectional Interaction Module (BInM) to facilitate interactive learning among multimodal features. Additionally, to address the difficulty of hierarchical multi-label classification in this task, a Dynamic Selection Module (DSM) is designed to select the feature representation that is most conducive to current protein function prediction. Our proposed DSRPGO model improves significantly in BPO, MFO, and CCO on human datasets, thereby outperforming other benchmark models.
PVNet: Point-Voxel Interaction LiDAR Scene Upsampling Via Diffusion Models
Aug 23, 2025Accurate 3D scene understanding in outdoor environments heavily relies on high-quality point clouds. However, LiDAR-scanned data often suffer from extreme sparsity, severely hindering downstream 3D perception tasks. Existing point cloud upsampling methods primarily focus on individual objects, thus demonstrating limited generalization capability for complex outdoor scenes. To address this issue, we propose PVNet, a diffusion model-based point-voxel interaction framework to perform LiDAR point cloud upsampling without dense supervision. Specifically, we adopt the classifier-free guidance-based DDPMs to guide the generation, in which we employ a sparse point cloud as the guiding condition and the synthesized point clouds derived from its nearby frames as the input. Moreover, we design a voxel completion module to refine and complete the coarse voxel features for enriching the feature representation. In addition, we propose a point-voxel interaction module to integrate features from both points and voxels, which efficiently improves the environmental perception capability of each upsampled point. To the best of our knowledge, our approach is the first scene-level point cloud upsampling method supporting arbitrary upsampling rates. Extensive experiments on various benchmarks demonstrate that our method achieves state-of-the-art performance. The source code will be available at https://github.com/chengxianjing/PVNet.
HeLo: Heterogeneous Multi-Modal Fusion with Label Correlation for Emotion Distribution Learning
Jul 09, 2025Multi-modal emotion recognition has garnered increasing attention as it plays a significant role in human-computer interaction (HCI) in recent years. Since different discrete emotions may exist at the same time, compared with single-class emotion recognition, emotion distribution learning (EDL) that identifies a mixture of basic emotions has gradually emerged as a trend. However, existing EDL methods face challenges in mining the heterogeneity among multiple modalities. Besides, rich semantic correlations across arbitrary basic emotions are not fully exploited. In this paper, we propose a multi-modal emotion distribution learning framework, named HeLo, aimed at fully exploring the heterogeneity and complementary information in multi-modal emotional data and label correlation within mixed basic emotions. Specifically, we first adopt cross-attention to effectively fuse the physiological data. Then, an optimal transport (OT)-based heterogeneity mining module is devised to mine the interaction and heterogeneity between the physiological and behavioral representations. To facilitate label correlation learning, we introduce a learnable label embedding optimized by correlation matrix alignment. Finally, the learnable label embeddings and label correlation matrices are integrated with the multi-modal representations through a novel label correlation-driven cross-attention mechanism for accurate emotion distribution learning. Experimental results on two publicly available datasets demonstrate the superiority of our proposed method in emotion distribution learning.
Vad-R1: Towards Video Anomaly Reasoning via Perception-to-Cognition Chain-of-Thought
May 26, 2025Recent advancements in reasoning capability of Multimodal Large Language Models (MLLMs) demonstrate its effectiveness in tackling complex visual tasks. However, existing MLLM-based Video Anomaly Detection (VAD) methods remain limited to shallow anomaly descriptions without deep reasoning. In this paper, we propose a new task named Video Anomaly Reasoning (VAR), which aims to enable deep analysis and understanding of anomalies in the video by requiring MLLMs to think explicitly before answering. To this end, we propose Vad-R1, an end-to-end MLLM-based framework for VAR. Specifically, we design a Perception-to-Cognition Chain-of-Thought (P2C-CoT) that simulates the human process of recognizing anomalies, guiding the MLLM to reason anomaly step-by-step. Based on the structured P2C-CoT, we construct Vad-Reasoning, a dedicated dataset for VAR. Furthermore, we propose an improved reinforcement learning algorithm AVA-GRPO, which explicitly incentivizes the anomaly reasoning capability of MLLMs through a self-verification mechanism with limited annotations. Experimental results demonstrate that Vad-R1 achieves superior performance, outperforming both open-source and proprietary models on VAD and VAR tasks. Codes and datasets will be released at https://github.com/wbfwonderful/Vad-R1.
Single Image Reflection Removal via inter-layer Complementarity
May 19, 2025Although dual-stream architectures have achieved remarkable success in single image reflection removal, they fail to fully exploit inter-layer complementarity in their physical modeling and network design, which limits the quality of image separation. To address this fundamental limitation, we propose two targeted improvements to enhance dual-stream architectures: First, we introduce a novel inter-layer complementarity model where low-frequency components extracted from the residual layer interact with the transmission layer through dual-stream architecture to enhance inter-layer complementarity. Meanwhile, high-frequency components from the residual layer provide inverse modulation to both streams, improving the detail quality of the transmission layer. Second, we propose an efficient inter-layer complementarity attention mechanism which first cross-reorganizes dual streams at the channel level to obtain reorganized streams with inter-layer complementary structures, then performs attention computation on the reorganized streams to achieve better inter-layer separation, and finally restores the original stream structure for output. Experimental results demonstrate that our method achieves state-of-the-art separation quality on multiple public datasets while significantly reducing both computational cost and model complexity.
ViEEG: Hierarchical Neural Coding with Cross-Modal Progressive Enhancement for EEG-Based Visual Decoding
May 18, 2025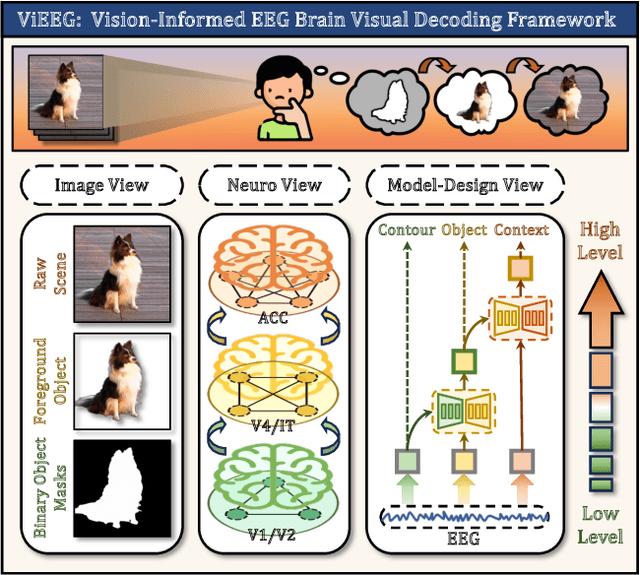


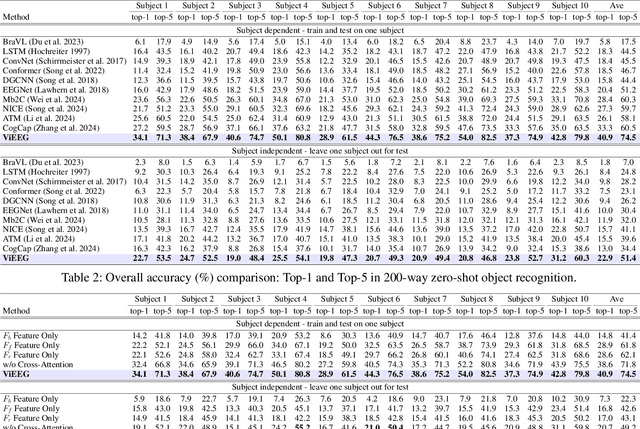
Understanding and decoding brain activity into visual representations is a fundamental challenge at the intersection of neuroscience and artificial intelligence. While EEG-based visual decoding has shown promise due to its non-invasive, low-cost nature and millisecond-level temporal resolution, existing methods are limited by their reliance on flat neural representations that overlook the brain's inherent visual hierarchy. In this paper, we introduce ViEEG, a biologically inspired hierarchical EEG decoding framework that aligns with the Hubel-Wiesel theory of visual processing. ViEEG decomposes each visual stimulus into three biologically aligned components-contour, foreground object, and contextual scene-serving as anchors for a three-stream EEG encoder. These EEG features are progressively integrated via cross-attention routing, simulating cortical information flow from V1 to IT to the association cortex. We further adopt hierarchical contrastive learning to align EEG representations with CLIP embeddings, enabling zero-shot object recognition. Extensive experiments on the THINGS-EEG dataset demonstrate that ViEEG achieves state-of-the-art performance, with 40.9% Top-1 accuracy in subject-dependent and 22.9% Top-1 accuracy in cross-subject settings, surpassing existing methods by over 45%. Our framework not only advances the performance frontier but also sets a new paradigm for biologically grounded brain decoding in AI.
Lightweight Contrastive Distilled Hashing for Online Cross-modal Retrieval
Feb 28, 2025Deep online cross-modal hashing has gained much attention from researchers recently, as its promising applications with low storage requirement, fast retrieval efficiency and cross modality adaptive, etc. However, there still exists some technical hurdles that hinder its applications, e.g., 1) how to extract the coexistent semantic relevance of cross-modal data, 2) how to achieve competitive performance when handling the real time data streams, 3) how to transfer the knowledge learned from offline to online training in a lightweight manner. To address these problems, this paper proposes a lightweight contrastive distilled hashing (LCDH) for cross-modal retrieval, by innovatively bridging the offline and online cross-modal hashing by similarity matrix approximation in a knowledge distillation framework. Specifically, in the teacher network, LCDH first extracts the cross-modal features by the contrastive language-image pre-training (CLIP), which are further fed into an attention module for representation enhancement after feature fusion. Then, the output of the attention module is fed into a FC layer to obtain hash codes for aligning the sizes of similarity matrices for online and offline training. In the student network, LCDH extracts the visual and textual features by lightweight models, and then the features are fed into a FC layer to generate binary codes. Finally, by approximating the similarity matrices, the performance of online hashing in the lightweight student network can be enhanced by the supervision of coexistent semantic relevance that is distilled from the teacher network. Experimental results on three widely used datasets demonstrate that LCDH outperforms some state-of-the-art methods.