 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMULTIBENCH++: A Unified and Comprehensive Multimodal Fusion Benchmarking Across Specialized Domains
Nov 14, 2025Although multimodal fusion has made significant progress, its advancement is severely hindered by the lack of adequate evaluation benchmarks. Current fusion methods are typically evaluated on a small selection of public datasets, a limited scope that inadequately represents the complexity and diversity of real-world scenarios, potentially leading to biased evaluations. This issue presents a twofold challenge. On one hand, models may overfit to the biases of specific datasets, hindering their generalization to broader practical applications. On the other hand, the absence of a unified evaluation standard makes fair and objective comparisons between different fusion methods difficult. Consequently, a truly universal and high-performance fusion model has yet to emerge. To address these challenges, we have developed a large-scale, domain-adaptive benchmark for multimodal evaluation. This benchmark integrates over 30 datasets, encompassing 15 modalities and 20 predictive tasks across key application domains. To complement this, we have also developed an open-source, unified, and automated evaluation pipeline that includes standardized implementations of state-of-the-art models and diverse fusion paradigms. Leveraging this platform, we have conducted large-scale experiments, successfully establishing new performance baselines across multiple tasks. This work provides the academic community with a crucial platform for rigorous and reproducible assessment of multimodal models, aiming to propel the field of multimodal artificial intelligence to new heights.
MedSG-Bench: A Benchmark for Medical Image Sequences Grounding
May 17, 2025Visual grounding is essential for precise perception and reasoning in multimodal large language models (MLLMs), especially in medical imaging domains. While existing medical visual grounding benchmarks primarily focus on single-image scenarios, real-world clinical applications often involve sequential images, where accurate lesion localization across different modalities and temporal tracking of disease progression (e.g., pre- vs. post-treatment comparison) require fine-grained cross-image semantic alignment and context-aware reasoning. To remedy the underrepresentation of image sequences in existing medical visual grounding benchmarks, we propose MedSG-Bench, the first benchmark tailored for Medical Image Sequences Grounding. It comprises eight VQA-style tasks, formulated into two paradigms of the grounding tasks, including 1) Image Difference Grounding, which focuses on detecting change regions across images, and 2) Image Consistency Grounding, which emphasizes detection of consistent or shared semantics across sequential images. MedSG-Bench covers 76 public datasets, 10 medical imaging modalities, and a wide spectrum of anatomical structures and diseases, totaling 9,630 question-answer pairs. We benchmark both general-purpose MLLMs (e.g., Qwen2.5-VL) and medical-domain specialized MLLMs (e.g., HuatuoGPT-vision), observing that even the advanced models exhibit substantial limitations in medical sequential grounding tasks. To advance this field, we construct MedSG-188K, a large-scale instruction-tuning dataset tailored for sequential visual grounding, and further develop MedSeq-Grounder, an MLLM designed to facilitate future research on fine-grained understanding across medical sequential images. The benchmark, dataset, and model are available at https://huggingface.co/MedSG-Bench
Turing Machine Evaluation for Large Language Model
Apr 29, 2025



With the rapid development and widespread application of Large Language Models (LLMs), rigorous evaluation has become particularly crucial. This research adopts a novel perspective, focusing on evaluating the core computational reasoning ability of LLMs, defined as the capacity of model to accurately understand rules, and execute logically computing operations. This capability assesses the reliability of LLMs as precise executors, and is critical to advanced tasks such as complex code generation and multi-step problem-solving. We propose an evaluation framework based on Universal Turing Machine (UTM) simulation. This framework requires LLMs to strictly follow instructions and track dynamic states, such as tape content and read/write head position, during multi-step computations. To enable standardized evaluation, we developed TMBench, a benchmark for systematically studying the computational reasoning capabilities of LLMs. TMBench provides several key advantages, including knowledge-agnostic evaluation, adjustable difficulty, foundational coverage through Turing machine encoding, and unlimited capacity for instance generation, ensuring scalability as models continue to evolve. We find that model performance on TMBench correlates strongly with performance on other recognized reasoning benchmarks (Pearson correlation coefficient is 0.73), clearly demonstrating that computational reasoning is a significant dimension for measuring the deep capabilities of LLMs. Code and data are available at https://github.com/HaitaoWuTJU/Turing-Machine-Bench.
DOTA: Distributional Test-Time Adaptation of Vision-Language Models
Sep 28, 2024



Vision-language foundation models (e.g., CLIP) have shown remarkable performance across a wide range of tasks. However, deploying these models may be unreliable when significant distribution gaps exist between the training and test data. The training-free test-time dynamic adapter (TDA) is a promising approach to address this issue by storing representative test samples to guide the classification of subsequent ones. However, TDA only naively maintains a limited number of reference samples in the cache, leading to severe test-time catastrophic forgetting when the cache is updated by dropping samples. In this paper, we propose a simple yet effective method for DistributiOnal Test-time Adaptation (Dota). Instead of naively memorizing representative test samples, Dota continually estimates the distributions of test samples, allowing the model to continually adapt to the deployment environment. The test-time posterior probabilities are then computed using the estimated distributions based on Bayes' theorem for adaptation purposes. To further enhance the adaptability on the uncertain samples, we introduce a new human-in-the-loop paradigm which identifies uncertain samples, collects human-feedback, and incorporates it into the Dota framework. Extensive experiments validate that Dota enables CLIP to continually learn, resulting in a significant improvement compared to current state-of-the-art methods.
Confidence-aware multi-modality learning for eye disease screening
May 28, 2024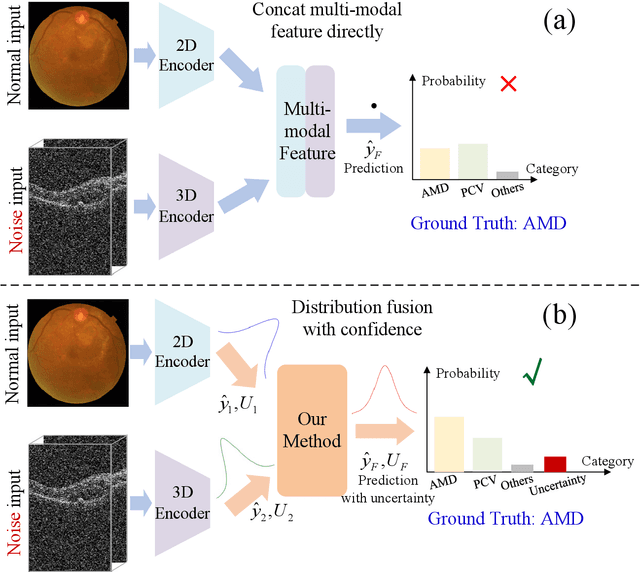
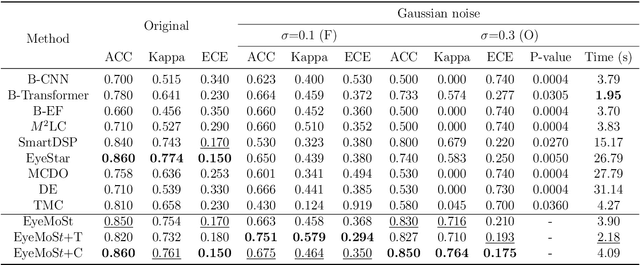
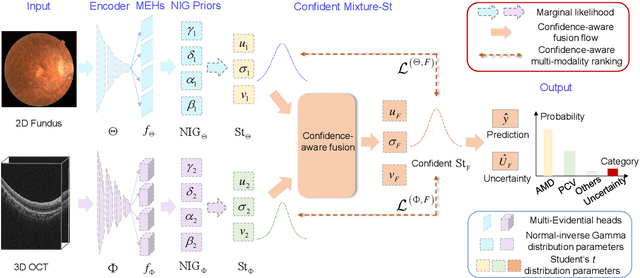
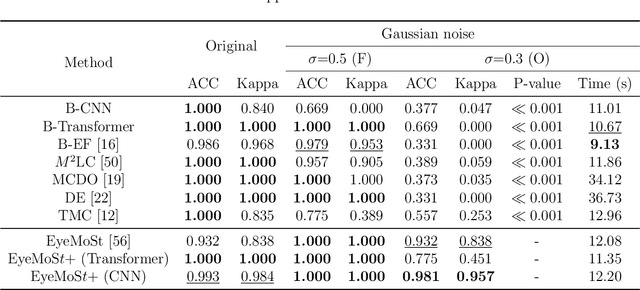
Multi-modal ophthalmic image classification plays a key role in diagnosing eye diseases, as it integrates information from different sources to complement their respective performances. However, recent improvements have mainly focused on accuracy, often neglecting the importance of confidence and robustness in predictions for diverse modalities. In this study, we propose a novel multi-modality evidential fusion pipeline for eye disease screening. It provides a measure of confidence for each modality and elegantly integrates the multi-modality information using a multi-distribution fusion perspective. Specifically, our method first utilizes normal inverse gamma prior distributions over pre-trained models to learn both aleatoric and epistemic uncertainty for uni-modality. Then, the normal inverse gamma distribution is analyzed as the Student's t distribution. Furthermore, within a confidence-aware fusion framework, we propose a mixture of Student's t distributions to effectively integrate different modalities, imparting the model with heavy-tailed properties and enhancing its robustness and reliability. More importantly, the confidence-aware multi-modality ranking regularization term induces the model to more reasonably rank the noisy single-modal and fused-modal confidence, leading to improved reliability and accuracy. Experimental results on both public and internal datasets demonstrate that our model excels in robustness, particularly in challenging scenarios involving Gaussian noise and modality missing conditions. Moreover, our model exhibits strong generalization capabilities to out-of-distribution data, underscoring its potential as a promising solution for multimodal eye disease screening.
Hallucination of Multimodal Large Language Models: A Survey
Apr 29, 2024



This survey presents a comprehensive analysis of the phenomenon of hallucination in multimodal large language models (MLLMs), also known as Large Vision-Language Models (LVLMs), which have demonstrated significant advancements and remarkable abilities in multimodal tasks. Despite these promising developments, MLLMs often generate outputs that are inconsistent with the visual content, a challenge known as hallucination, which poses substantial obstacles to their practical deployment and raises concerns regarding their reliability in real-world applications. This problem has attracted increasing attention, prompting efforts to detect and mitigate such inaccuracies. We review recent advances in identifying, evaluating, and mitigating these hallucinations, offering a detailed overview of the underlying causes, evaluation benchmarks, metrics, and strategies developed to address this issue. Additionally, we analyze the current challenges and limitations, formulating open questions that delineate potential pathways for future research. By drawing the granular classification and landscapes of hallucination causes, evaluation benchmarks, and mitigation methods, this survey aims to deepen the understanding of hallucinations in MLLMs and inspire further advancements in the field. Through our thorough and in-depth review, we contribute to the ongoing dialogue on enhancing the robustness and reliability of MLLMs, providing valuable insights and resources for researchers and practitioners alike. Resources are available at: https://github.com/showlab/Awesome-MLLM-Hallucination.
Multimodal Fusion on Low-quality Data: A Comprehensive Survey
Apr 27, 2024



Multimodal fusion focuses on integrating information from multiple modalities with the goal of more accurate prediction, which has achieved remarkable progress in a wide range of scenarios, including autonomous driving and medical diagnosis. However, the reliability of multimodal fusion remains largely unexplored especially under low-quality data settings. This paper surveys the common challenges and recent advances of multimodal fusion in the wild and presents them in a comprehensive taxonomy. From a data-centric view, we identify four main challenges that are faced by multimodal fusion on low-quality data, namely (1) noisy multimodal data that are contaminated with heterogeneous noises, (2) incomplete multimodal data that some modalities are missing, (3) imbalanced multimodal data that the qualities or properties of different modalities are significantly different and (4) quality-varying multimodal data that the quality of each modality dynamically changes with respect to different samples. This new taxonomy will enable researchers to understand the state of the field and identify several potential directions. We also provide discussion for the open problems in this field together with interesting future research directions.
Selective Learning: Towards Robust Calibration with Dynamic Regularization
Feb 13, 2024



Miscalibration in deep learning refers to there is a discrepancy between the predicted confidence and performance. This problem usually arises due to the overfitting problem, which is characterized by learning everything presented in the training set, resulting in overconfident predictions during testing. Existing methods typically address overfitting and mitigate the miscalibration by adding a maximum-entropy regularizer to the objective function. The objective can be understood as seeking a model that fits the ground-truth labels by increasing the confidence while also maximizing the entropy of predicted probabilities by decreasing the confidence. However, previous methods lack clear guidance on confidence adjustment, leading to conflicting objectives (increasing but also decreasing confidence). Therefore, we introduce a method called Dynamic Regularization (DReg), which aims to learn what should be learned during training thereby circumventing the confidence adjusting trade-off. At a high level, DReg aims to obtain a more reliable model capable of acknowledging what it knows and does not know. Specifically, DReg effectively fits the labels for in-distribution samples (samples that should be learned) while applying regularization dynamically to samples beyond model capabilities (e.g., outliers), thereby obtaining a robust calibrated model especially on the samples beyond model capabilities. Both theoretical and empirical analyses sufficiently demonstrate the superiority of DReg compared with previous methods.
Skip : A Simple Method to Reduce Hallucination in Large Vision-Language Models
Feb 12, 2024Recent advancements in large vision-language models (LVLMs) have demonstrated impressive capability in visual information understanding with human language. Despite these advances, LVLMs still face challenges with multimodal hallucination, such as generating text descriptions of objects that are not present in the visual information. However, the underlying fundamental reasons of multimodal hallucinations remain poorly explored. In this paper, we propose a new perspective, suggesting that the inherent biases in LVLMs might be a key factor in hallucinations. Specifically, we systematically identify a semantic shift bias related to paragraph breaks (\n\n), where the content before and after '\n\n' in the training data frequently exhibit significant semantic changes. This pattern leads the model to infer that the contents following '\n\n' should be obviously different from the preceding contents with less hallucinatory descriptions, thereby increasing the probability of hallucinatory descriptions subsequent to the '\n\n'. We have validated this hypothesis on multiple publicly available LVLMs. Besides, we find that deliberately inserting '\n\n' at the generated description can induce more hallucinations. A simple method is proposed to effectively mitigate the hallucination of LVLMs by skipping the output of '\n'.
ID-like Prompt Learning for Few-Shot Out-of-Distribution Detection
Nov 28, 2023Out-of-distribution (OOD) detection methods often exploit auxiliary outliers to train model identifying OOD samples, especially discovering challenging outliers from auxiliary outliers dataset to improve OOD detection. However, they may still face limitations in effectively distinguishing between the most challenging OOD samples that are much like in-distribution (ID) data, i.e., ID-like samples. To this end, we propose a novel OOD detection framework that discovers ID-like outliers using CLIP from the vicinity space of the ID samples, thus helping to identify these most challenging OOD samples. Then a prompt learning framework is proposed that utilizes the identified ID-like outliers to further leverage the capabilities of CLIP for OOD detection. Benefiting from the powerful CLIP, we only need a small number of ID samples to learn the prompts of the model without exposing other auxiliary outlier datasets. By focusing on the most challenging ID-like OOD samples and elegantly exploiting the capabilities of CLIP, our method achieves superior few-shot learning performance on various real-world image datasets (e.g., in 4-shot OOD detection on the ImageNet-1k dataset, our method reduces the average FPR95 by 12.16% and improves the average AUROC by 2.76%, compared to state-of-the-art methods).