 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReweighted Mixup for Subpopulation Shift
Apr 09, 2023Subpopulation shift exists widely in many real-world applications, which refers to the training and test distributions that contain the same subpopulation groups but with different subpopulation proportions. Ignoring subpopulation shifts may lead to significant performance degradation and fairness concerns. Importance reweighting is a classical and effective way to handle the subpopulation shift. However, recent studies have recognized that most of these approaches fail to improve the performance especially when applied to over-parameterized neural networks which are capable of fitting any training samples. In this work, we propose a simple yet practical framework, called reweighted mixup (RMIX), to mitigate the overfitting issue in over-parameterized models by conducting importance weighting on the ''mixed'' samples. Benefiting from leveraging reweighting in mixup, RMIX allows the model to explore the vicinal space of minority samples more, thereby obtaining more robust model against subpopulation shift. When the subpopulation memberships are unknown, the training-trajectories-based uncertainty estimation is equipped in the proposed RMIX to flexibly characterize the subpopulation distribution. We also provide insightful theoretical analysis to verify that RMIX achieves better generalization bounds over prior works. Further, we conduct extensive empirical studies across a wide range of tasks to validate the effectiveness of the proposed method.
Single-Trajectory Distributionally Robust Reinforcement Learning
Jan 27, 2023

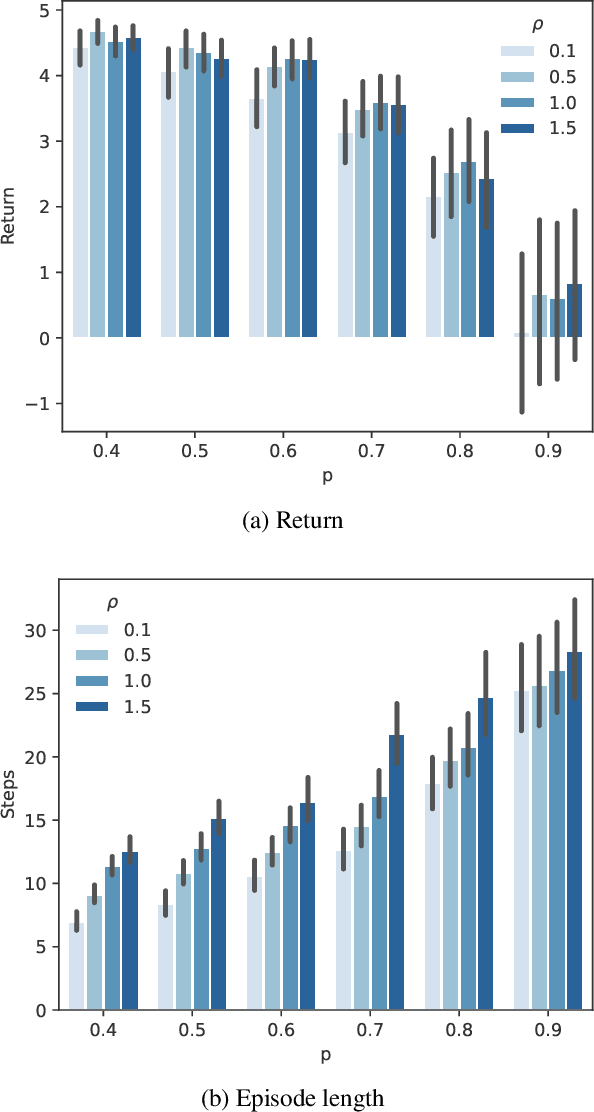

As a framework for sequential decision-making, Reinforcement Learning (RL) has been regarded as an essential component leading to Artificial General Intelligence (AGI). However, RL is often criticized for having the same training environment as the test one, which also hinders its application in the real world. To mitigate this problem, Distributionally Robust RL (DRRL) is proposed to improve the worst performance in a set of environments that may contain the unknown test environment. Due to the nonlinearity of the robustness goal, most of the previous work resort to the model-based approach, learning with either an empirical distribution learned from the data or a simulator that can be sampled infinitely, which limits their applications in simple dynamics environments. In contrast, we attempt to design a DRRL algorithm that can be trained along a single trajectory, i.e., no repeated sampling from a state. Based on the standard Q-learning, we propose distributionally robust Q-learning with the single trajectory (DRQ) and its average-reward variant named differential DRQ. We provide asymptotic convergence guarantees and experiments for both settings, demonstrating their superiority in the perturbed environments against the non-robust ones.
UMIX: Improving Importance Weighting for Subpopulation Shift via Uncertainty-Aware Mixup
Oct 10, 2022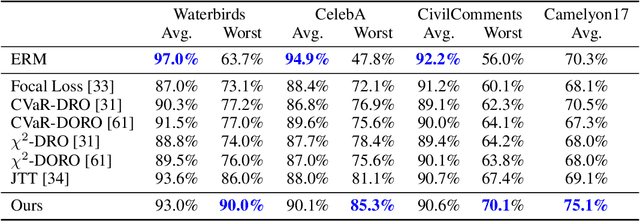
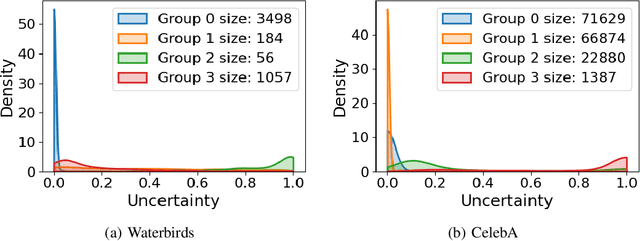
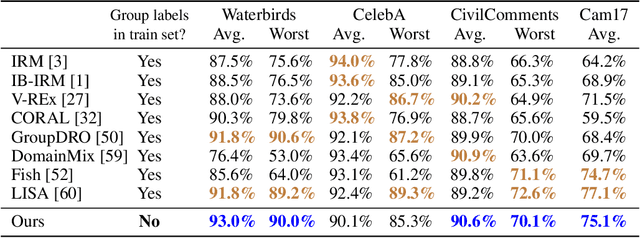
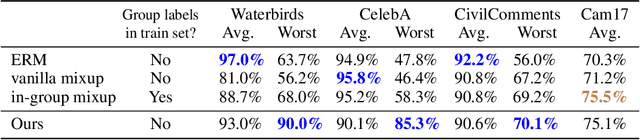
Subpopulation shift widely exists in many real-world machine learning applications, referring to the training and test distributions containing the same subpopulation groups but varying in subpopulation frequencies. Importance reweighting is a normal way to handle the subpopulation shift issue by imposing constant or adaptive sampling weights on each sample in the training dataset. However, some recent studies have recognized that most of these approaches fail to improve the performance over empirical risk minimization especially when applied to over-parameterized neural networks. In this work, we propose a simple yet practical framework, called uncertainty-aware mixup (UMIX), to mitigate the overfitting issue in over-parameterized models by reweighting the ''mixed'' samples according to the sample uncertainty. The training-trajectories-based uncertainty estimation is equipped in the proposed UMIX for each sample to flexibly characterize the subpopulation distribution. We also provide insightful theoretical analysis to verify that UMIX achieves better generalization bounds over prior works. Further, we conduct extensive empirical studies across a wide range of tasks to validate the effectiveness of our method both qualitatively and quantitatively. Code is available at https://github.com/TencentAILabHealthcare/UMIX.
Distributionally Robust Offline Reinforcement Learning with Linear Function Approximation
Sep 29, 2022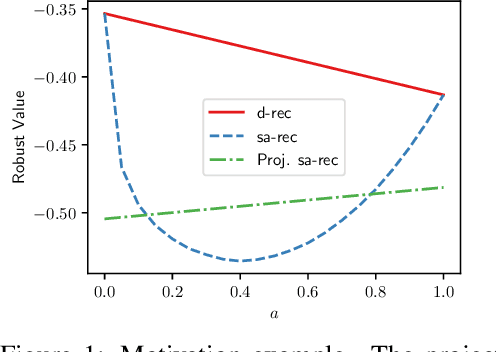
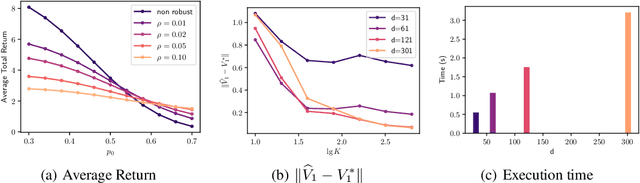
Among the reasons hindering reinforcement learning (RL) applications to real-world problems, two factors are critical: limited data and the mismatch between the testing environment (real environment in which the policy is deployed) and the training environment (e.g., a simulator). This paper attempts to address these issues simultaneously with distributionally robust offline RL, where we learn a distributionally robust policy using historical data obtained from the source environment by optimizing against a worst-case perturbation thereof. In particular, we move beyond tabular settings and consider linear function approximation. More specifically, we consider two settings, one where the dataset is well-explored and the other where the dataset has sufficient coverage. We propose two algorithms -- one for each of the two settings -- that achieve error bounds $\tilde{O}(d^{1/2}/N^{1/2})$ and $\tilde{O}(d^{3/2}/N^{1/2})$ respectively, where $d$ is the dimension in the linear function approximation and $N$ is the number of trajectories in the dataset. To the best of our knowledge, they provide the first non-asymptotic results of the sample complexity in this setting. Diverse experiments are conducted to demonstrate our theoretical findings, showing the superiority of our algorithm against the non-robust one.
On Private Online Convex Optimization: Optimal Algorithms in $\ell_p$-Geometry and High Dimensional Contextual Bandits
Jun 16, 2022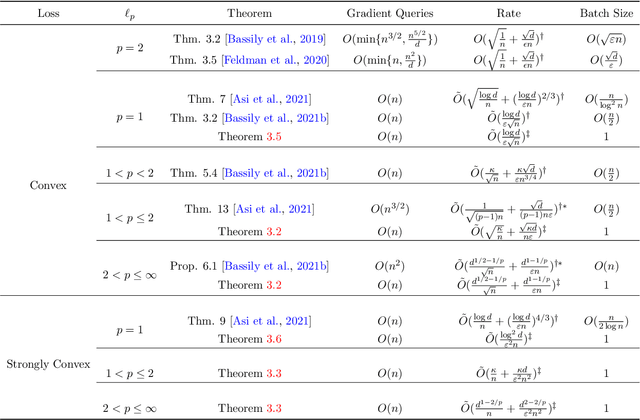

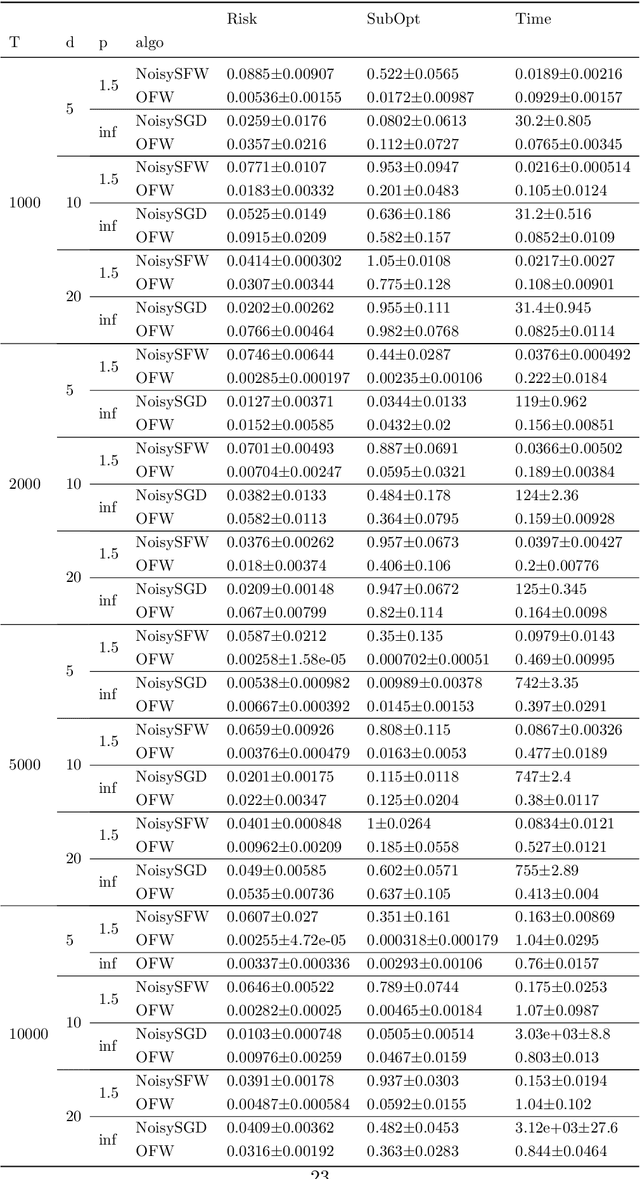
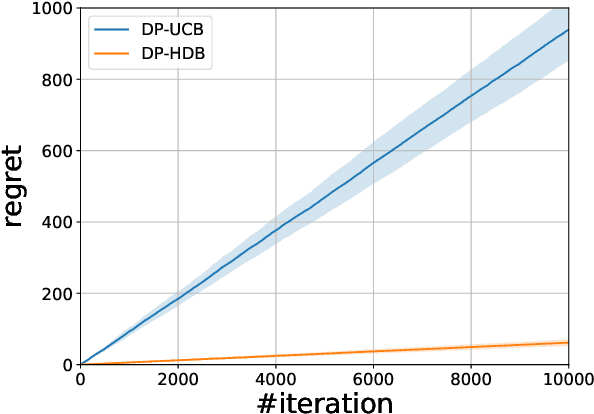
Differentially private (DP) stochastic convex optimization (SCO) is ubiquitous in trustworthy machine learning algorithm design. This paper studies the DP-SCO problem with streaming data sampled from a distribution and arrives sequentially. We also consider the continual release model where parameters related to private information are updated and released upon each new data, often known as the online algorithms. Despite that numerous algorithms have been developed to achieve the optimal excess risks in different $\ell_p$ norm geometries, yet none of the existing ones can be adapted to the streaming and continual release setting. To address such a challenge as the online convex optimization with privacy protection, we propose a private variant of online Frank-Wolfe algorithm with recursive gradients for variance reduction to update and reveal the parameters upon each data. Combined with the adaptive differential privacy analysis, our online algorithm achieves in linear time the optimal excess risk when $1<p\leq 2$ and the state-of-the-art excess risk meeting the non-private lower ones when $2<p\leq\infty$. Our algorithm can also be extended to the case $p=1$ to achieve nearly dimension-independent excess risk. While previous variance reduction results on recursive gradient have theoretical guarantee only in the independent and identically distributed sample setting, we establish such a guarantee in a non-stationary setting. To demonstrate the virtues of our method, we design the first DP algorithm for high-dimensional generalized linear bandits with logarithmic regret. Comparative experiments with a variety of DP-SCO and DP-Bandit algorithms exhibit the efficacy and utility of the proposed algorithms.
DRFLM: Distributionally Robust Federated Learning with Inter-client Noise via Local Mixup
Apr 16, 2022
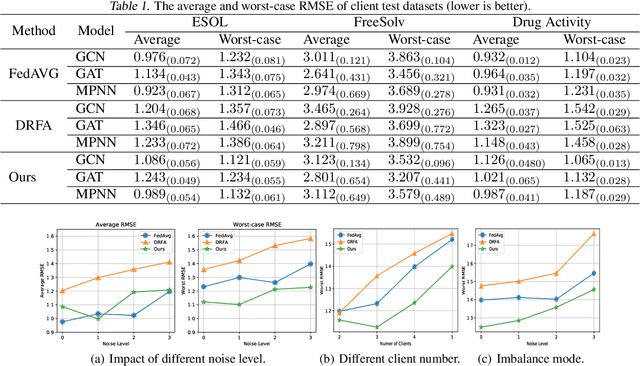


Recently, federated learning has emerged as a promising approach for training a global model using data from multiple organizations without leaking their raw data. Nevertheless, directly applying federated learning to real-world tasks faces two challenges: (1) heterogeneity in the data among different organizations; and (2) data noises inside individual organizations. In this paper, we propose a general framework to solve the above two challenges simultaneously. Specifically, we propose using distributionally robust optimization to mitigate the negative effects caused by data heterogeneity paradigm to sample clients based on a learnable distribution at each iteration. Additionally, we observe that this optimization paradigm is easily affected by data noises inside local clients, which has a significant performance degradation in terms of global model prediction accuracy. To solve this problem, we propose to incorporate mixup techniques into the local training process of federated learning. We further provide comprehensive theoretical analysis including robustness analysis, convergence analysis, and generalization ability. Furthermore, we conduct empirical studies across different drug discovery tasks, such as ADMET property prediction and drug-target affinity prediction.
Generalized Linear Bandits with Local Differential Privacy
Jun 07, 2021
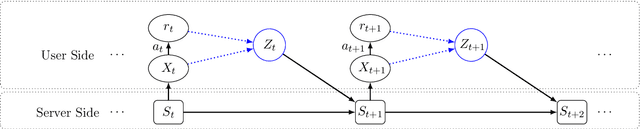

Contextual bandit algorithms are useful in personalized online decision-making. However, many applications such as personalized medicine and online advertising require the utilization of individual-specific information for effective learning, while user's data should remain private from the server due to privacy concerns. This motivates the introduction of local differential privacy (LDP), a stringent notion in privacy, to contextual bandits. In this paper, we design LDP algorithms for stochastic generalized linear bandits to achieve the same regret bound as in non-privacy settings. Our main idea is to develop a stochastic gradient-based estimator and update mechanism to ensure LDP. We then exploit the flexibility of stochastic gradient descent (SGD), whose theoretical guarantee for bandit problems is rarely explored, in dealing with generalized linear bandits. We also develop an estimator and update mechanism based on Ordinary Least Square (OLS) for linear bandits. Finally, we conduct experiments with both simulation and real-world datasets to demonstrate the consistently superb performance of our algorithms under LDP constraints with reasonably small parameters $(\varepsilon, \delta)$ to ensure strong privacy protection.
Deep Reinforcement Learning in Portfolio Management
Nov 01, 2018
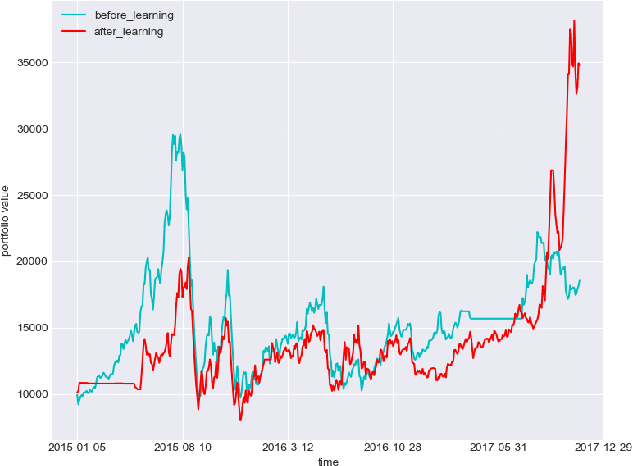

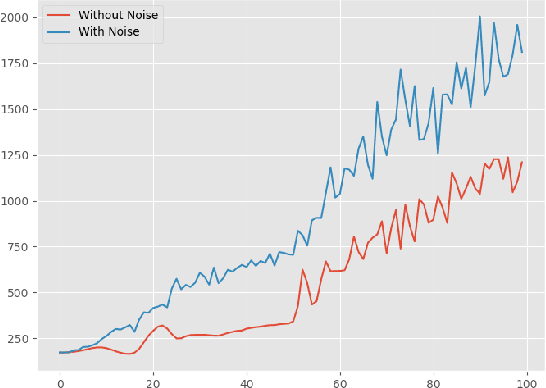
In this paper, we implement two state-of-art continuous reinforcement learning algorithms, Deep Deterministic Policy Gradient (DDPG) and Proximal Policy Optimization (PPO) in portfolio management. Both of them are widely-used in game playing and robot control. What's more, PPO has appealing theoretical propeties which is hopefully potential in portfolio management. We present the performances of them under different settings, including different learning rate, objective function, markets, feature combinations, in order to provide insights for parameter tuning, features selection and data preparation.