 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRFLM: Distributionally Robust Federated Learning with Inter-client Noise via Local Mixup
Paper and Code
Apr 16, 2022
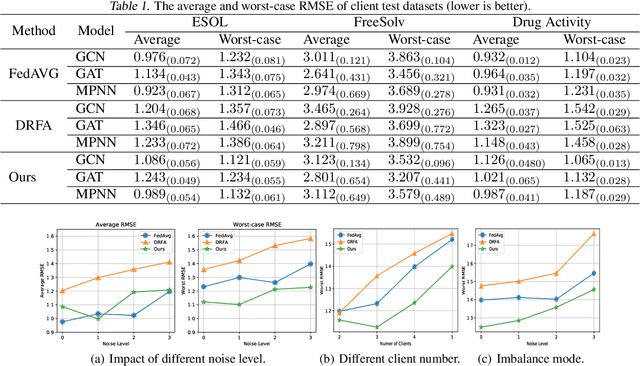


Recently, federated learning has emerged as a promising approach for training a global model using data from multiple organizations without leaking their raw data. Nevertheless, directly applying federated learning to real-world tasks faces two challenges: (1) heterogeneity in the data among different organizations; and (2) data noises inside individual organizations. In this paper, we propose a general framework to solve the above two challenges simultaneously. Specifically, we propose using distributionally robust optimization to mitigate the negative effects caused by data heterogeneity paradigm to sample clients based on a learnable distribution at each iteration. Additionally, we observe that this optimization paradigm is easily affected by data noises inside local clients, which has a significant performance degradation in terms of global model prediction accuracy. To solve this problem, we propose to incorporate mixup techniques into the local training process of federated learning. We further provide comprehensive theoretical analysis including robustness analysis, convergence analysis, and generalization ability. Furthermore, we conduct empirical studies across different drug discovery tasks, such as ADMET property prediction and drug-target affinity prediction.