 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel Unbalance in High-frequency Trading
Mar 13, 2025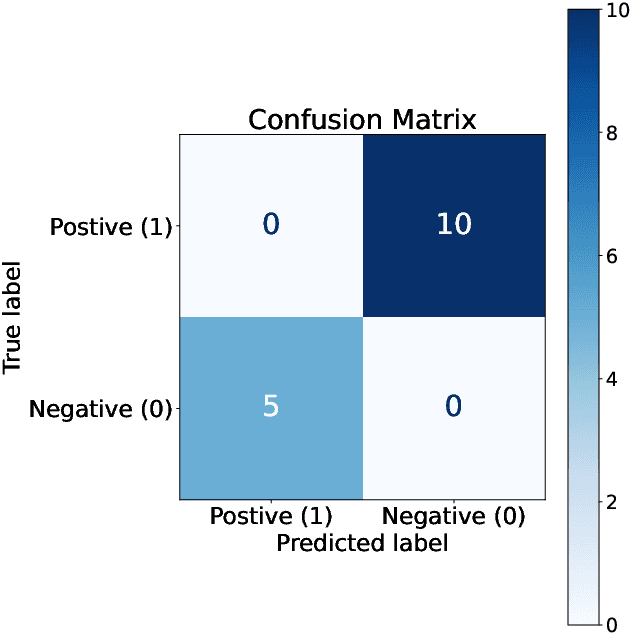
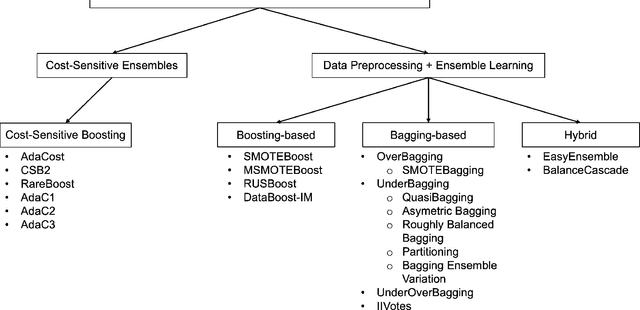
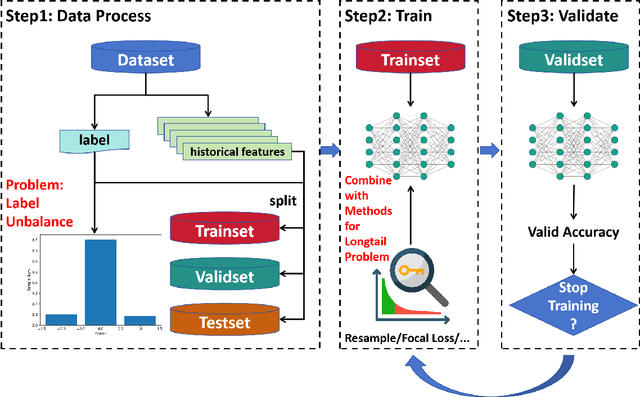
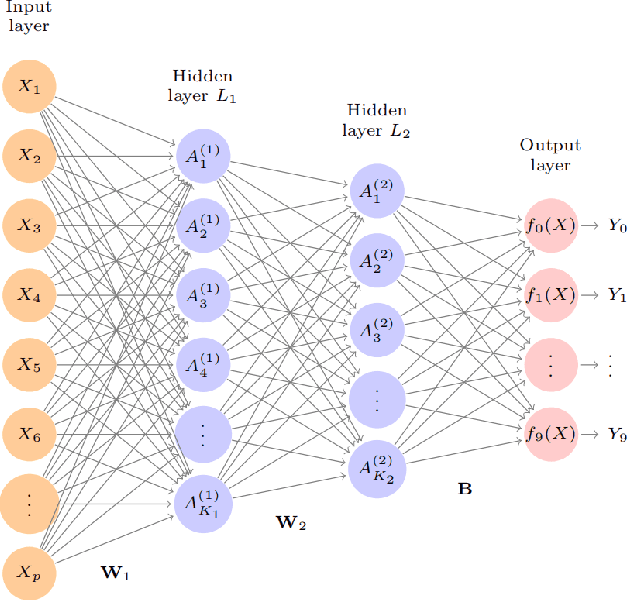
In financial trading, return prediction is one of the foundation for a successful trading system. By the fast development of the deep learning in various areas such as graphical processing, natural language, it has also demonstrate significant edge in handling with financial data. While the success of the deep learning relies on huge amount of labeled sample, labeling each time/event as profitable or unprofitable, under the transaction cost, especially in the high-frequency trading world, suffers from serious label imbalance issue.In this paper, we adopts rigurious end-to-end deep learning framework with comprehensive label imbalance adjustment methods and succeed in predicting in high-frequency return in the Chinese future market. The code for our method is publicly available at https://github.com/RS2002/Label-Unbalance-in-High-Frequency-Trading .
Are LLMs Rigorous Logical Reasoner? Empowering Natural Language Proof Generation with Contrastive Stepwise Decoding
Nov 12, 2023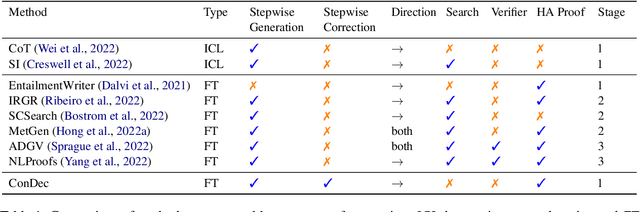
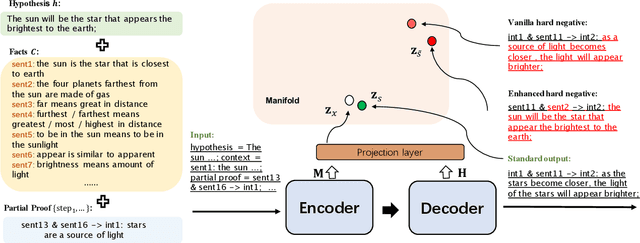
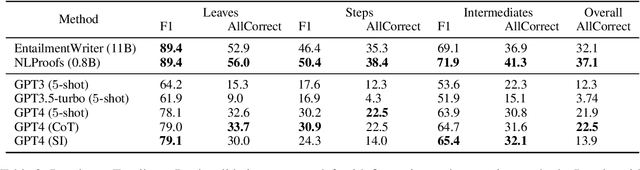
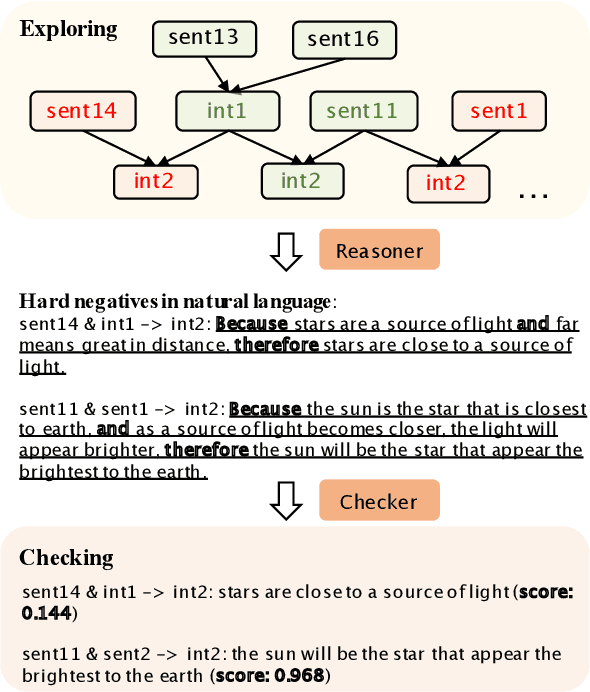
Logical reasoning remains a pivotal component within the realm of artificial intelligence. The recent evolution of large language models (LLMs) has marked significant progress in this domain. The adoption of strategies like chain-of-thought (CoT) has enhanced the performance of LLMs across diverse reasoning tasks. Nonetheless, logical reasoning that involves proof planning, specifically those that necessitate the validation of explanation accuracy, continues to present stumbling blocks. In this study, we first evaluate the efficacy of LLMs with advanced CoT strategies concerning such tasks. Our analysis reveals that LLMs still struggle to navigate complex reasoning chains, which demand the meticulous linkage of premises to derive a cogent conclusion. To address this issue, we finetune a smaller-scale language model, equipping it to decompose proof objectives into more manageable subgoals. We also introduce contrastive decoding to stepwise proof generation, making use of negative reasoning paths to strengthen the model's capacity for logical deduction. Experiments on EntailmentBank underscore the success of our method in augmenting the proof planning abilities of language models.
Distributionally Robust Offline Reinforcement Learning with Linear Function Approximation
Sep 29, 2022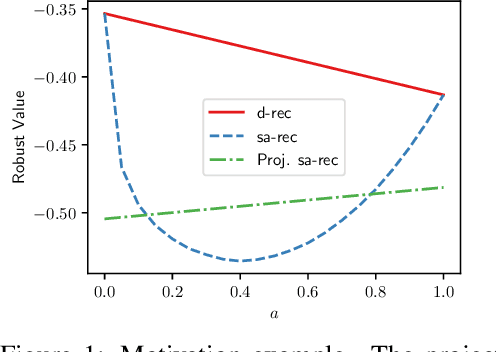
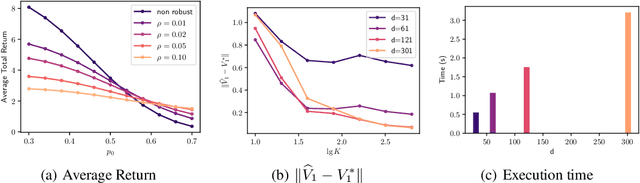
Among the reasons hindering reinforcement learning (RL) applications to real-world problems, two factors are critical: limited data and the mismatch between the testing environment (real environment in which the policy is deployed) and the training environment (e.g., a simulator). This paper attempts to address these issues simultaneously with distributionally robust offline RL, where we learn a distributionally robust policy using historical data obtained from the source environment by optimizing against a worst-case perturbation thereof. In particular, we move beyond tabular settings and consider linear function approximation. More specifically, we consider two settings, one where the dataset is well-explored and the other where the dataset has sufficient coverage. We propose two algorithms -- one for each of the two settings -- that achieve error bounds $\tilde{O}(d^{1/2}/N^{1/2})$ and $\tilde{O}(d^{3/2}/N^{1/2})$ respectively, where $d$ is the dimension in the linear function approximation and $N$ is the number of trajectories in the dataset. To the best of our knowledge, they provide the first non-asymptotic results of the sample complexity in this setting. Diverse experiments are conducted to demonstrate our theoretical findings, showing the superiority of our algorithm against the non-robust one.
Stock Market Trend Analysis Using Hidden Markov Model and Long Short Term Memory
Apr 20, 2021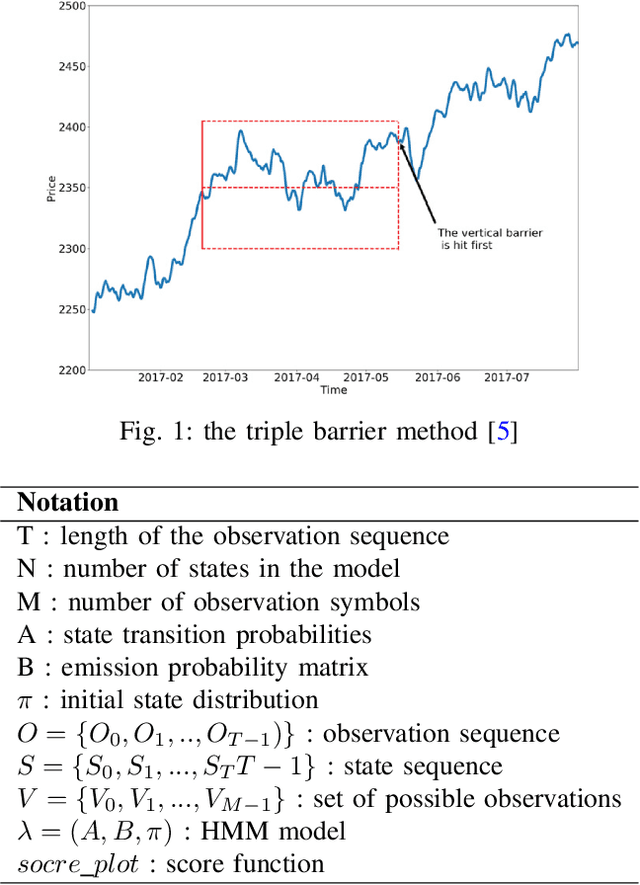



This paper intends to apply the Hidden Markov Model into stock market and and make predictions. Moreover, four different methods of improvement, which are GMM-HMM, XGB-HMM, GMM-HMM+LSTM and XGB-HMM+LSTM, will be discussed later with the results of experiment respectively. After that we will analyze the pros and cons of different models. And finally, one of the best will be used into stock market for timing strategy.