 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the latent space of diffusion models directly through singular value decomposition
Feb 04, 2025Despite the groundbreaking success of diffusion models in generating high-fidelity images, their latent space remains relatively under-explored, even though it holds significant promise for enabling versatile and interpretable image editing capabilities. The complicated denoising trajectory and high dimensionality of the latent space make it extremely challenging to interpret. Existing methods mainly explore the feature space of U-Net in Diffusion Models (DMs) instead of the latent space itself. In contrast, we directly investigate the latent space via Singular Value Decomposition (SVD) and discover three useful properties that can be used to control generation results without the requirements of data collection and maintain identity fidelity generated images. Based on these properties, we propose a novel image editing framework that is capable of learning arbitrary attributes from one pair of latent codes destined by text prompts in Stable Diffusion Models. To validate our approach, extensive experiments are conducted to demonstrate its effectiveness and flexibility in image editing. We will release our codes soon to foster further research and applications in this area.
ViMo: Generating Motions from Casual Videos
Aug 13, 2024
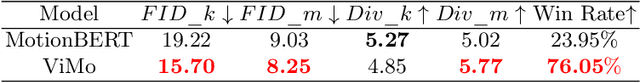
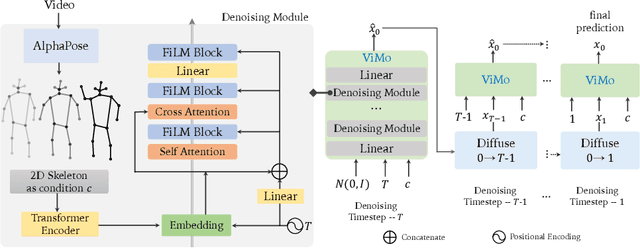

Although humans have the innate ability to imagine multiple possible actions from videos, it remains an extraordinary challenge for computers due to the intricate camera movements and montages. Most existing motion generation methods predominantly rely on manually collected motion datasets, usually tediously sourced from motion capture (Mocap) systems or Multi-View cameras, unavoidably resulting in a limited size that severely undermines their generalizability. Inspired by recent advance of diffusion models, we probe a simple and effective way to capture motions from videos and propose a novel Video-to-Motion-Generation framework (ViMo) which could leverage the immense trove of untapped video content to produce abundant and diverse 3D human motions. Distinct from prior work, our videos could be more causal, including complicated camera movements and occlusions. Striking experimental results demonstrate the proposed model could generate natural motions even for videos where rapid movements, varying perspectives, or frequent occlusions might exist. We also show this work could enable three important downstream applications, such as generating dancing motions according to arbitrary music and source video style. Extensive experimental results prove that our model offers an effective and scalable way to generate diversity and realistic motions. Code and demos will be public soon.
Towards a Client-Centered Assessment of LLM Therapists by Client Simulation
Jun 18, 2024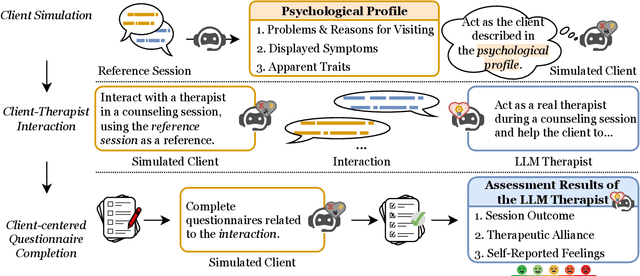

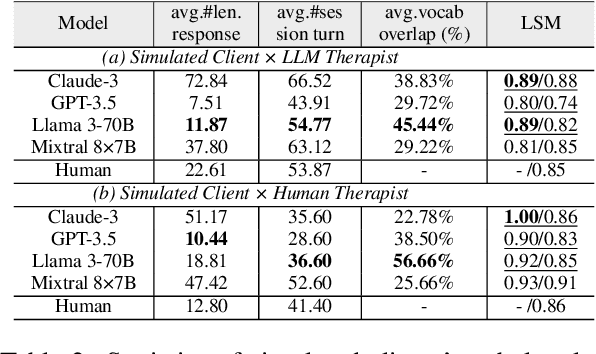
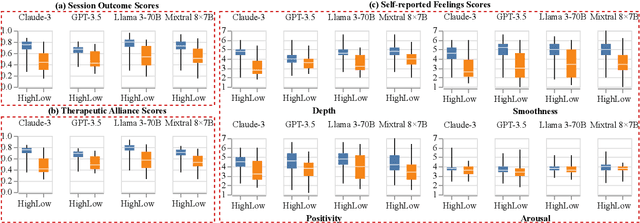
Although there is a growing belief that LLMs can be used as therapists, exploring LLMs' capabilities and inefficacy, particularly from the client's perspective, is limited. This work focuses on a client-centered assessment of LLM therapists with the involvement of simulated clients, a standard approach in clinical medical education. However, there are two challenges when applying the approach to assess LLM therapists at scale. Ethically, asking humans to frequently mimic clients and exposing them to potentially harmful LLM outputs can be risky and unsafe. Technically, it can be difficult to consistently compare the performances of different LLM therapists interacting with the same client. To this end, we adopt LLMs to simulate clients and propose ClientCAST, a client-centered approach to assessing LLM therapists by client simulation. Specifically, the simulated client is utilized to interact with LLM therapists and complete questionnaires related to the interaction. Based on the questionnaire results, we assess LLM therapists from three client-centered aspects: session outcome, therapeutic alliance, and self-reported feelings. We conduct experiments to examine the reliability of ClientCAST and use it to evaluate LLMs therapists implemented by Claude-3, GPT-3.5, LLaMA3-70B, and Mixtral 8*7B. Codes are released at https://github.com/wangjs9/ClientCAST.
Multi-level Contrastive Learning for Script-based Character Understanding
Oct 20, 2023In this work, we tackle the scenario of understanding characters in scripts, which aims to learn the characters' personalities and identities from their utterances. We begin by analyzing several challenges in this scenario, and then propose a multi-level contrastive learning framework to capture characters' global information in a fine-grained manner. To validate the proposed framework, we conduct extensive experiments on three character understanding sub-tasks by comparing with strong pre-trained language models, including SpanBERT, Longformer, BigBird and ChatGPT-3.5. Experimental results demonstrate that our method improves the performances by a considerable margin. Through further in-depth analysis, we show the effectiveness of our method in addressing the challenges and provide more hints on the scenario of character understanding. We will open-source our work on github at https://github.com/David-Li0406/Script-based-Character-Understanding.
NarrativePlay: Interactive Narrative Understanding
Oct 02, 2023

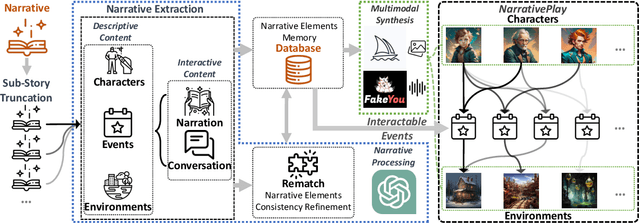
In this paper, we introduce NarrativePlay, a novel system that allows users to role-play a fictional character and interact with other characters in narratives such as novels in an immersive environment. We leverage Large Language Models (LLMs) to generate human-like responses, guided by personality traits extracted from narratives. The system incorporates auto-generated visual display of narrative settings, character portraits, and character speech, greatly enhancing user experience. Our approach eschews predefined sandboxes, focusing instead on main storyline events extracted from narratives from the perspective of a user-selected character. NarrativePlay has been evaluated on two types of narratives, detective and adventure stories, where users can either explore the world or improve their favorability with the narrative characters through conversations.
CharacterChat: Learning towards Conversational AI with Personalized Social Support
Aug 20, 2023In our modern, fast-paced, and interconnected world, the importance of mental well-being has grown into a matter of great urgency. However, traditional methods such as Emotional Support Conversations (ESC) face challenges in effectively addressing a diverse range of individual personalities. In response, we introduce the Social Support Conversation (S2Conv) framework. It comprises a series of support agents and the interpersonal matching mechanism, linking individuals with persona-compatible virtual supporters. Utilizing persona decomposition based on the MBTI (Myers-Briggs Type Indicator), we have created the MBTI-1024 Bank, a group that of virtual characters with distinct profiles. Through improved role-playing prompts with behavior preset and dynamic memory, we facilitate the development of the MBTI-S2Conv dataset, which contains conversations between the characters in the MBTI-1024 Bank. Building upon these foundations, we present CharacterChat, a comprehensive S2Conv system, which includes a conversational model driven by personas and memories, along with an interpersonal matching plugin model that dispatches the optimal supporters from the MBTI-1024 Bank for individuals with specific personas. Empirical results indicate the remarkable efficacy of CharacterChat in providing personalized social support and highlight the substantial advantages derived from interpersonal matching. The source code is available in \url{https://github.com/morecry/CharacterChat}.
Assisting Language Learners: Automated Trans-Lingual Definition Generation via Contrastive Prompt Learning
Jun 09, 2023The standard definition generation task requires to automatically produce mono-lingual definitions (e.g., English definitions for English words), but ignores that the generated definitions may also consist of unfamiliar words for language learners. In this work, we propose a novel task of Trans-Lingual Definition Generation (TLDG), which aims to generate definitions in another language, i.e., the native speaker's language. Initially, we explore the unsupervised manner of this task and build up a simple implementation of fine-tuning the multi-lingual machine translation model. Then, we develop two novel methods, Prompt Combination and Contrastive Prompt Learning, for further enhancing the quality of the generation. Our methods are evaluated against the baseline Pipeline method in both rich- and low-resource settings, and we empirically establish its superiority in generating higher-quality trans-lingual definitions.
Distinguishability Calibration to In-Context Learning
Feb 13, 2023Recent years have witnessed increasing interests in prompt-based learning in which models can be trained on only a few annotated instances, making them suitable in low-resource settings. When using prompt-based learning for text classification, the goal is to use a pre-trained language model (PLM) to predict a missing token in a pre-defined template given an input text, which can be mapped to a class label. However, PLMs built on the transformer architecture tend to generate similar output embeddings, making it difficult to discriminate between different class labels. The problem is further exacerbated when dealing with classification tasks involving many fine-grained class labels. In this work, we alleviate this information diffusion issue, i.e., different tokens share a large proportion of similar information after going through stacked multiple self-attention layers in a transformer, by proposing a calibration method built on feature transformations through rotation and scaling to map a PLM-encoded embedding into a new metric space to guarantee the distinguishability of the resulting embeddings. Furthermore, we take the advantage of hyperbolic embeddings to capture the hierarchical relations among fine-grained class-associated token embedding by a coarse-to-fine metric learning strategy to enhance the distinguishability of the learned output embeddings. Extensive experiments on the three datasets under various settings demonstrate the effectiveness of our approach. Our code can be found at https://github.com/donttal/TARA.
BERT-ERC: Fine-tuning BERT is Enough for Emotion Recognition in Conversation
Jan 17, 2023



Previous works on emotion recognition in conversation (ERC) follow a two-step paradigm, which can be summarized as first producing context-independent features via fine-tuning pretrained language models (PLMs) and then analyzing contextual information and dialogue structure information among the extracted features. However, we discover that this paradigm has several limitations. Accordingly, we propose a novel paradigm, i.e., exploring contextual information and dialogue structure information in the fine-tuning step, and adapting the PLM to the ERC task in terms of input text, classification structure, and training strategy. Furthermore, we develop our model BERT-ERC according to the proposed paradigm, which improves ERC performance in three aspects, namely suggestive text, fine-grained classification module, and two-stage training. Compared to existing methods, BERT-ERC achieves substantial improvement on four datasets, indicating its effectiveness and generalization capability. Besides, we also set up the limited resources scenario and the online prediction scenario to approximate real-world scenarios. Extensive experiments demonstrate that the proposed paradigm significantly outperforms the previous one and can be adapted to various scenes.
Predicting Ejection Fraction from Chest X-rays Using Computer Vision for Diagnosing Heart Failure
Dec 19, 2022



Heart failure remains a major public health challenge with growing costs. Ejection fraction (EF) is a key metric for the diagnosis and management of heart failure however estimation of EF using echocardiography remains expensive for the healthcare system and subject to intra/inter operator variability. While chest x-rays (CXR) are quick, inexpensive, and require less expertise, they do not provide sufficient information to the human eye to estimate EF. This work explores the efficacy of computer vision techniques to predict reduced EF solely from CXRs. We studied a dataset of 3488 CXRs from the MIMIC CXR-jpg (MCR) dataset. Our work establishes benchmarks using multiple state-of-the-art convolutional neural network architectures. The subsequent analysis shows increasing model sizes from 8M to 23M parameters improved classification performance without overfitting the dataset. We further show how data augmentation techniques such as CXR rotation and random cropping further improves model performance another ~5%. Finally, we conduct an error analysis using saliency maps and Grad-CAMs to better understand the failure modes of convolutional models on this task.