 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViMo: Generating Motions from Casual Videos
Paper and Code
Aug 13, 2024
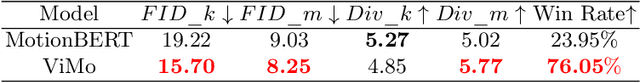
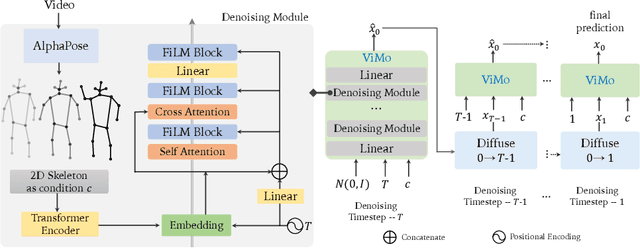

Although humans have the innate ability to imagine multiple possible actions from videos, it remains an extraordinary challenge for computers due to the intricate camera movements and montages. Most existing motion generation methods predominantly rely on manually collected motion datasets, usually tediously sourced from motion capture (Mocap) systems or Multi-View cameras, unavoidably resulting in a limited size that severely undermines their generalizability. Inspired by recent advance of diffusion models, we probe a simple and effective way to capture motions from videos and propose a novel Video-to-Motion-Generation framework (ViMo) which could leverage the immense trove of untapped video content to produce abundant and diverse 3D human motions. Distinct from prior work, our videos could be more causal, including complicated camera movements and occlusions. Striking experimental results demonstrate the proposed model could generate natural motions even for videos where rapid movements, varying perspectives, or frequent occlusions might exist. We also show this work could enable three important downstream applications, such as generating dancing motions according to arbitrary music and source video style. Extensive experimental results prove that our model offers an effective and scalable way to generate diversity and realistic motions. Code and demos will be public soon.