 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViMo: Generating Motions from Casual Videos
Aug 13, 2024
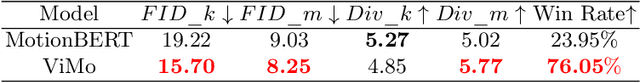
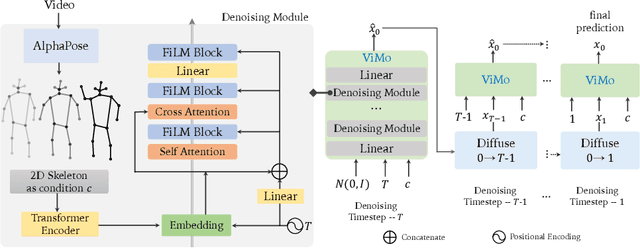

Although humans have the innate ability to imagine multiple possible actions from videos, it remains an extraordinary challenge for computers due to the intricate camera movements and montages. Most existing motion generation methods predominantly rely on manually collected motion datasets, usually tediously sourced from motion capture (Mocap) systems or Multi-View cameras, unavoidably resulting in a limited size that severely undermines their generalizability. Inspired by recent advance of diffusion models, we probe a simple and effective way to capture motions from videos and propose a novel Video-to-Motion-Generation framework (ViMo) which could leverage the immense trove of untapped video content to produce abundant and diverse 3D human motions. Distinct from prior work, our videos could be more causal, including complicated camera movements and occlusions. Striking experimental results demonstrate the proposed model could generate natural motions even for videos where rapid movements, varying perspectives, or frequent occlusions might exist. We also show this work could enable three important downstream applications, such as generating dancing motions according to arbitrary music and source video style. Extensive experimental results prove that our model offers an effective and scalable way to generate diversity and realistic motions. Code and demos will be public soon.
ToDER: Towards Colonoscopy Depth Estimation and Reconstruction with Geometry Constraint Adaptation
Jul 23, 2024



Visualizing colonoscopy is crucial for medical auxiliary diagnosis to prevent undetected polyps in areas that are not fully observed. Traditional feature-based and depth-based reconstruction approaches usually end up with undesirable results due to incorrect point matching or imprecise depth estimation in realistic colonoscopy videos. Modern deep-based methods often require a sufficient number of ground truth samples, which are generally hard to obtain in optical colonoscopy. To address this issue, self-supervised and domain adaptation methods have been explored. However, these methods neglect geometry constraints and exhibit lower accuracy in predicting detailed depth. We thus propose a novel reconstruction pipeline with a bi-directional adaptation architecture named ToDER to get precise depth estimations. Furthermore, we carefully design a TNet module in our adaptation architecture to yield geometry constraints and obtain better depth quality. Estimated depth is finally utilized to reconstruct a reliable colon model for visualization. Experimental results demonstrate that our approach can precisely predict depth maps in both realistic and synthetic colonoscopy videos compared with other self-supervised and domain adaptation methods. Our method on realistic colonoscopy also shows the great potential for visualizing unobserved regions and preventing misdiagnoses.
RaBit: Parametric Modeling of 3D Biped Cartoon Characters with a Topological-consistent Dataset
Mar 24, 2023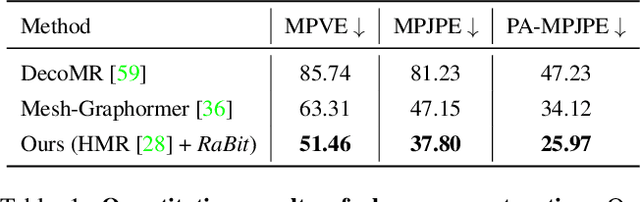


Assisting people in efficiently producing visually plausible 3D characters has always been a fundamental research topic in computer vision and computer graphics. Recent learning-based approaches have achieved unprecedented accuracy and efficiency in the area of 3D real human digitization. However, none of the prior works focus on modeling 3D biped cartoon characters, which are also in great demand in gaming and filming. In this paper, we introduce 3DBiCar, the first large-scale dataset of 3D biped cartoon characters, and RaBit, the corresponding parametric model. Our dataset contains 1,500 topologically consistent high-quality 3D textured models which are manually crafted by professional artists. Built upon the data, RaBit is thus designed with a SMPL-like linear blend shape model and a StyleGAN-based neural UV-texture generator, simultaneously expressing the shape, pose, and texture. To demonstrate the practicality of 3DBiCar and RaBit, various applications are conducted, including single-view reconstruction, sketch-based modeling, and 3D cartoon animation. For the single-view reconstruction setting, we find a straightforward global mapping from input images to the output UV-based texture maps tends to lose detailed appearances of some local parts (e.g., nose, ears). Thus, a part-sensitive texture reasoner is adopted to make all important local areas perceived. Experiments further demonstrate the effectiveness of our method both qualitatively and quantitatively. 3DBiCar and RaBit are available at gaplab.cuhk.edu.cn/projects/RaBit.
DArch: Dental Arch Prior-assisted 3D Tooth Instance Segmentation
Apr 25, 2022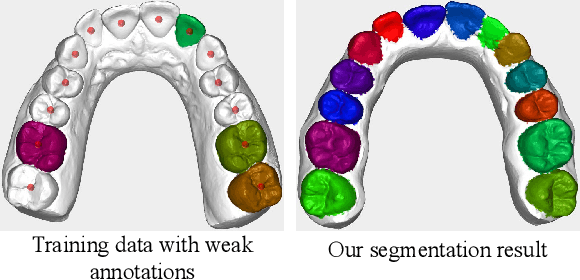
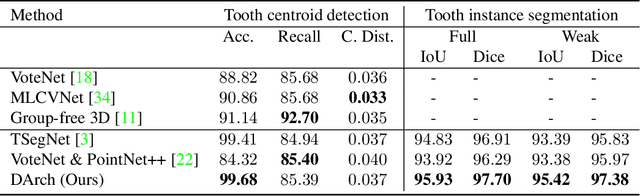
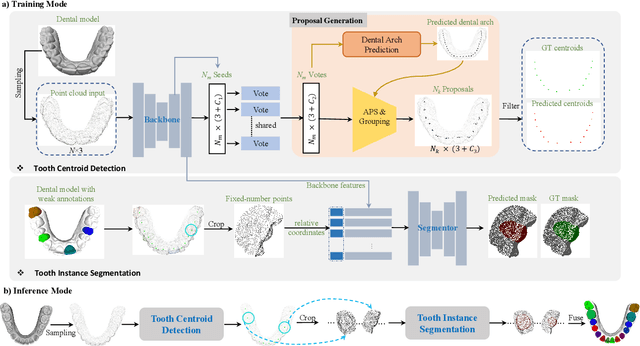
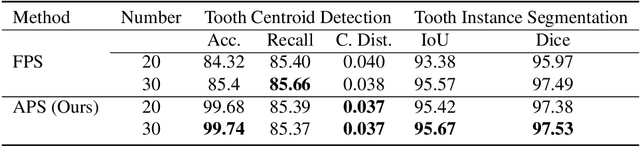
Automatic tooth instance segmentation on 3D dental models is a fundamental task for computer-aided orthodontic treatments. Existing learning-based methods rely heavily on expensive point-wise annotations. To alleviate this problem, we are the first to explore a low-cost annotation way for 3D tooth instance segmentation, i.e., labeling all tooth centroids and only a few teeth for each dental model. Regarding the challenge when only weak annotation is provided, we present a dental arch prior-assisted 3D tooth segmentation method, namely DArch. Our DArch consists of two stages, including tooth centroid detection and tooth instance segmentation. Accurately detecting the tooth centroids can help locate the individual tooth, thus benefiting the segmentation. Thus, our DArch proposes to leverage the dental arch prior to assist the detection. Specifically, we firstly propose a coarse-to-fine method to estimate the dental arch, in which the dental arch is initially generated by Bezier curve regression, and then a graph-based convolutional network (GCN) is trained to refine it. With the estimated dental arch, we then propose a novel Arch-aware Point Sampling (APS) method to assist the tooth centroid proposal generation. Meantime, a segmentor is independently trained using a patch-based training strategy, aiming to segment a tooth instance from a 3D patch centered at the tooth centroid. Experimental results on $4,773$ dental models have shown our DArch can accurately segment each tooth of a dental model, and its performance is superior to the state-of-the-art methods.
SharpContour: A Contour-based Boundary Refinement Approach for Efficient and Accurate Instance Segmentation
Mar 24, 2022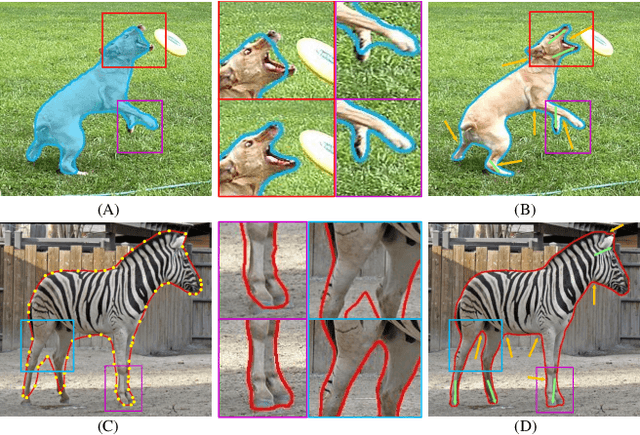
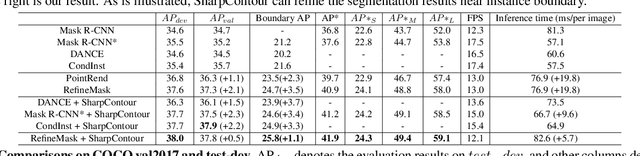
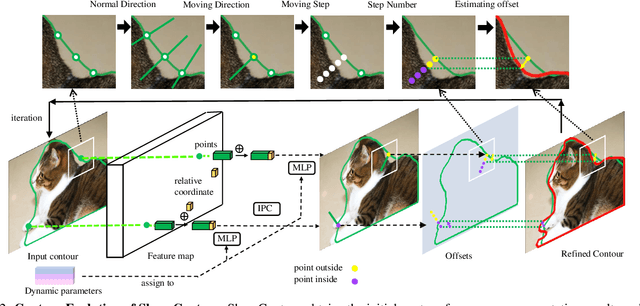
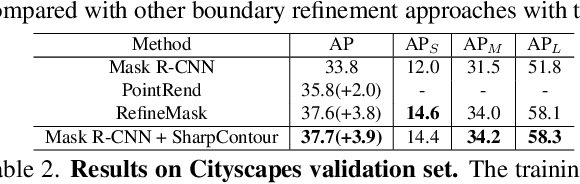
Excellent performance has been achieved on instance segmentation but the quality on the boundary area remains unsatisfactory, which leads to a rising attention on boundary refinement. For practical use, an ideal post-processing refinement scheme are required to be accurate, generic and efficient. However, most of existing approaches propose pixel-wise refinement, which either introduce a massive computation cost or design specifically for different backbone models. Contour-based models are efficient and generic to be incorporated with any existing segmentation methods, but they often generate over-smoothed contour and tend to fail on corner areas. In this paper, we propose an efficient contour-based boundary refinement approach, named SharpContour, to tackle the segmentation of boundary area. We design a novel contour evolution process together with an Instance-aware Point Classifier. Our method deforms the contour iteratively by updating offsets in a discrete manner. Differing from existing contour evolution methods, SharpContour estimates each offset more independently so that it predicts much sharper and accurate contours. Notably, our method is generic to seamlessly work with diverse existing models with a small computational cost. Experiments show that SharpContour achieves competitive gains whilst preserving high efficiency