 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEI-Part: Explode for Completion and Implode for Refinement
Mar 14, 2026Part-level 3D generation is crucial for various downstream applications, including gaming, film production, and industrial design. However, decomposing a 3D shape into geometrically plausible and meaningful components remains a significant challenge. Previous part-based generation methods often struggle to produce well-constructed parts, exhibiting poor structural coherence, geometric implausibility, inaccuracy, or inefficiency. To address these challenges, we introduce EI-Part, a novel framework specifically designed to generate high-quality 3D shapes with components, characterized by strong structural coherence, geometric plausibility, geometric fidelity, and generation efficiency. We propose utilizing distinct representations at different stages: an Explode state for part completion and an Implode state for geometry refinement. This strategy fully leverages spatial resolution, enabling flexible part completion and fine geometric detail generation. To maintain structural coherence between parts, a self-attention mechanism is incorporated in both exploded and imploded states, facilitating effective information perception and feature fusion among components during generation. Extensive experiments on multiple benchmarks demonstrate that EI-Part efficiently produces semantically meaningful and structurally coherent parts with fine-grained geometric details, achieving state-of-the-art performance in part-level 3D generation. Project page: https://cvhadessun.github.io/EI-Part/
Stable-SCore: A Stable Registration-based Framework for 3D Shape Correspondence
Mar 27, 2025



Establishing character shape correspondence is a critical and fundamental task in computer vision and graphics, with diverse applications including re-topology, attribute transfer, and shape interpolation. Current dominant functional map methods, while effective in controlled scenarios, struggle in real situations with more complex challenges such as non-isometric shape discrepancies. In response, we revisit registration-for-correspondence methods and tap their potential for more stable shape correspondence estimation. To overcome their common issues including unstable deformations and the necessity for careful pre-alignment or high-quality initial 3D correspondences, we introduce Stable-SCore: A Stable Registration-based Framework for 3D Shape Correspondence. We first re-purpose a foundation model for 2D character correspondence that ensures reliable and stable 2D mappings. Crucially, we propose a novel Semantic Flow Guided Registration approach that leverages 2D correspondence to guide mesh deformations. Our framework significantly surpasses existing methods in challenging scenarios, and brings possibilities for a wide array of real applications, as demonstrated in our results.
BAG: Body-Aligned 3D Wearable Asset Generation
Jan 27, 2025



While recent advancements have shown remarkable progress in general 3D shape generation models, the challenge of leveraging these approaches to automatically generate wearable 3D assets remains unexplored. To this end, we present BAG, a Body-aligned Asset Generation method to output 3D wearable asset that can be automatically dressed on given 3D human bodies. This is achived by controlling the 3D generation process using human body shape and pose information. Specifically, we first build a general single-image to consistent multiview image diffusion model, and train it on the large Objaverse dataset to achieve diversity and generalizability. Then we train a Controlnet to guide the multiview generator to produce body-aligned multiview images. The control signal utilizes the multiview 2D projections of the target human body, where pixel values represent the XYZ coordinates of the body surface in a canonical space. The body-conditioned multiview diffusion generates body-aligned multiview images, which are then fed into a native 3D diffusion model to produce the 3D shape of the asset. Finally, by recovering the similarity transformation using multiview silhouette supervision and addressing asset-body penetration with physics simulators, the 3D asset can be accurately fitted onto the target human body. Experimental results demonstrate significant advantages over existing methods in terms of image prompt-following capability, shape diversity, and shape quality. Our project page is available at https://bag-3d.github.io/.
GarVerseLOD: High-Fidelity 3D Garment Reconstruction from a Single In-the-Wild Image using a Dataset with Levels of Details
Nov 05, 2024



Neural implicit functions have brought impressive advances to the state-of-the-art of clothed human digitization from multiple or even single images. However, despite the progress, current arts still have difficulty generalizing to unseen images with complex cloth deformation and body poses. In this work, we present GarVerseLOD, a new dataset and framework that paves the way to achieving unprecedented robustness in high-fidelity 3D garment reconstruction from a single unconstrained image. Inspired by the recent success of large generative models, we believe that one key to addressing the generalization challenge lies in the quantity and quality of 3D garment data. Towards this end, GarVerseLOD collects 6,000 high-quality cloth models with fine-grained geometry details manually created by professional artists. In addition to the scale of training data, we observe that having disentangled granularities of geometry can play an important role in boosting the generalization capability and inference accuracy of the learned model. We hence craft GarVerseLOD as a hierarchical dataset with levels of details (LOD), spanning from detail-free stylized shape to pose-blended garment with pixel-aligned details. This allows us to make this highly under-constrained problem tractable by factorizing the inference into easier tasks, each narrowed down with smaller searching space. To ensure GarVerseLOD can generalize well to in-the-wild images, we propose a novel labeling paradigm based on conditional diffusion models to generate extensive paired images for each garment model with high photorealism. We evaluate our method on a massive amount of in-the-wild images. Experimental results demonstrate that GarVerseLOD can generate standalone garment pieces with significantly better quality than prior approaches. Project page: https://garverselod.github.io/
SketchMetaFace: A Learning-based Sketching Interface for High-fidelity 3D Character Face Modeling
Jul 04, 2023



Modeling 3D avatars benefits various application scenarios such as AR/VR, gaming, and filming. Character faces contribute significant diversity and vividity as a vital component of avatars. However, building 3D character face models usually requires a heavy workload with commercial tools, even for experienced artists. Various existing sketch-based tools fail to support amateurs in modeling diverse facial shapes and rich geometric details. In this paper, we present SketchMetaFace - a sketching system targeting amateur users to model high-fidelity 3D faces in minutes. We carefully design both the user interface and the underlying algorithm. First, curvature-aware strokes are adopted to better support the controllability of carving facial details. Second, considering the key problem of mapping a 2D sketch map to a 3D model, we develop a novel learning-based method termed "Implicit and Depth Guided Mesh Modeling" (IDGMM). It fuses the advantages of mesh, implicit, and depth representations to achieve high-quality results with high efficiency. In addition, to further support usability, we present a coarse-to-fine 2D sketching interface design and a data-driven stroke suggestion tool. User studies demonstrate the superiority of our system over existing modeling tools in terms of the ease to use and visual quality of results. Experimental analyses also show that IDGMM reaches a better trade-off between accuracy and efficiency. SketchMetaFace is available at https://zhongjinluo.github.io/SketchMetaFace/.
RaBit: Parametric Modeling of 3D Biped Cartoon Characters with a Topological-consistent Dataset
Mar 24, 2023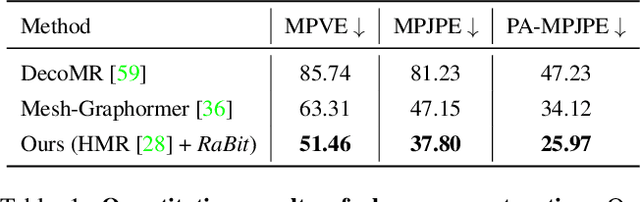


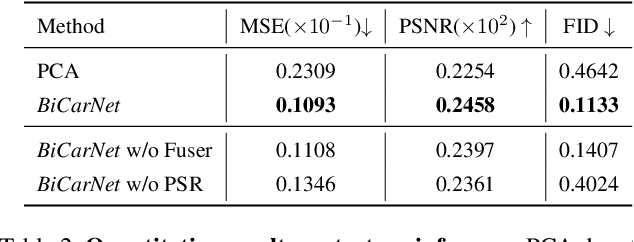
Assisting people in efficiently producing visually plausible 3D characters has always been a fundamental research topic in computer vision and computer graphics. Recent learning-based approaches have achieved unprecedented accuracy and efficiency in the area of 3D real human digitization. However, none of the prior works focus on modeling 3D biped cartoon characters, which are also in great demand in gaming and filming. In this paper, we introduce 3DBiCar, the first large-scale dataset of 3D biped cartoon characters, and RaBit, the corresponding parametric model. Our dataset contains 1,500 topologically consistent high-quality 3D textured models which are manually crafted by professional artists. Built upon the data, RaBit is thus designed with a SMPL-like linear blend shape model and a StyleGAN-based neural UV-texture generator, simultaneously expressing the shape, pose, and texture. To demonstrate the practicality of 3DBiCar and RaBit, various applications are conducted, including single-view reconstruction, sketch-based modeling, and 3D cartoon animation. For the single-view reconstruction setting, we find a straightforward global mapping from input images to the output UV-based texture maps tends to lose detailed appearances of some local parts (e.g., nose, ears). Thus, a part-sensitive texture reasoner is adopted to make all important local areas perceived. Experiments further demonstrate the effectiveness of our method both qualitatively and quantitatively. 3DBiCar and RaBit are available at gaplab.cuhk.edu.cn/projects/RaBit.
Learning Deep Intensity Field for Extremely Sparse-View CBCT Reconstruction
Mar 12, 2023



Sparse-view cone-beam CT (CBCT) reconstruction is an important direction to reduce radiation dose and benefit clinical applications. Previous voxel-based generation methods represent the CT as discrete voxels, resulting in high memory requirements and limited spatial resolution due to the use of 3D decoders. In this paper, we formulate the CT volume as a continuous intensity field and develop a novel DIF-Net to perform high-quality CBCT reconstruction from extremely sparse (fewer than 10) projection views at an ultrafast speed. The intensity field of a CT can be regarded as a continuous function of 3D spatial points. Therefore, the reconstruction can be reformulated as regressing the intensity value of an arbitrary 3D point from given sparse projections. Specifically, for a point, DIF-Net extracts its view-specific features from different 2D projection views. These features are subsequently aggregated by a fusion module for intensity estimation. Notably, thousands of points can be processed in parallel to improve efficiency during training and testing. In practice, we collect a knee CBCT dataset to train and evaluate DIF-Net. Extensive experiments show that our approach can reconstruct CBCT with high image quality and high spatial resolution from extremely sparse views within 1.6 seconds, significantly outperforming state-of-the-art methods. Our code will be available at https://github.com/lyqun/DIF-Net.
SimpModeling: Sketching Implicit Field to Guide Mesh Modeling for 3D Animalmorphic Head Design
Aug 05, 2021


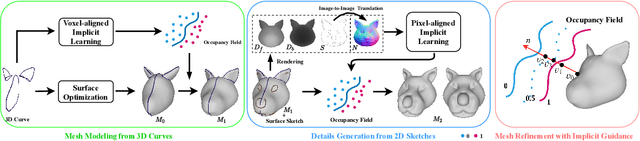
Head shapes play an important role in 3D character design. In this work, we propose SimpModeling, a novel sketch-based system for helping users, especially amateur users, easily model 3D animalmorphic heads - a prevalent kind of heads in character design. Although sketching provides an easy way to depict desired shapes, it is challenging to infer dense geometric information from sparse line drawings. Recently, deepnet-based approaches have been taken to address this challenge and try to produce rich geometric details from very few strokes. However, while such methods reduce users' workload, they would cause less controllability of target shapes. This is mainly due to the uncertainty of the neural prediction. Our system tackles this issue and provides good controllability from three aspects: 1) we separate coarse shape design and geometric detail specification into two stages and respectively provide different sketching means; 2) in coarse shape designing, sketches are used for both shape inference and geometric constraints to determine global geometry, and in geometric detail crafting, sketches are used for carving surface details; 3) in both stages, we use the advanced implicit-based shape inference methods, which have strong ability to handle the domain gap between freehand sketches and synthetic ones used for training. Experimental results confirm the effectiveness of our method and the usability of our interactive system. We also contribute to a dataset of high-quality 3D animal heads, which are manually created by artists.