 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBAS: A Decision-Theoretic Approach to Evaluating Large Language Model Confidence
Apr 03, 2026Large language models (LLMs) often produce confident but incorrect answers in settings where abstention would be safer. Standard evaluation protocols, however, require a response and do not account for how confidence should guide decisions under different risk preferences. To address this gap, we introduce the Behavioral Alignment Score (BAS), a decision-theoretic metric for evaluating how well LLM confidence supports abstention-aware decision making. BAS is derived from an explicit answer-or-abstain utility model and aggregates realized utility across a continuum of risk thresholds, yielding a measure of decision-level reliability that depends on both the magnitude and ordering of confidence. We show theoretically that truthful confidence estimates uniquely maximize expected BAS utility, linking calibration to decision-optimal behavior. BAS is related to proper scoring rules such as log loss, but differs structurally: log loss penalizes underconfidence and overconfidence symmetrically, whereas BAS imposes an asymmetric penalty that strongly prioritizes avoiding overconfident errors. Using BAS alongside widely used metrics such as ECE and AURC, we then construct a benchmark of self-reported confidence reliability across multiple LLMs and tasks. Our results reveal substantial variation in decision-useful confidence, and while larger and more accurate models tend to achieve higher BAS, even frontier models remain prone to severe overconfidence. Importantly, models with similar ECE or AURC can exhibit very different BAS due to highly overconfident errors, highlighting limitations of standard metrics. We further show that simple interventions, such as top-$k$ confidence elicitation and post-hoc calibration, can meaningfully improve confidence reliability. Overall, our work provides both a principled metric and a comprehensive benchmark for evaluating LLM confidence reliability.
Semantic Self-Distillation for Language Model Uncertainty
Feb 04, 2026Large language models present challenges for principled uncertainty quantification, in part due to their complexity and the diversity of their outputs. Semantic dispersion, or the variance in the meaning of sampled answers, has been proposed as a useful proxy for model uncertainty, but the associated computational cost prohibits its use in latency-critical applications. We show that sampled semantic distributions can be distilled into lightweight student models which estimate a prompt-conditioned uncertainty before the language model generates an answer token. The student model predicts a semantic distribution over possible answers; the entropy of this distribution provides an effective uncertainty signal for hallucination prediction, and the probability density allows candidate answers to be evaluated for reliability. On TriviaQA, our student models match or outperform finite-sample semantic dispersion for hallucination prediction and provide a strong signal for out-of-domain answer detection. We term this technique Semantic Self-Distillation (SSD), which we suggest provides a general framework for distilling predictive uncertainty in complex output spaces beyond language.
Optimization-Inspired Few-Shot Adaptation for Large Language Models
May 25, 2025Large Language Models (LLMs) have demonstrated remarkable performance in real-world applications. However, adapting LLMs to novel tasks via fine-tuning often requires substantial training data and computational resources that are impractical in few-shot scenarios. Existing approaches, such as in-context learning and Parameter-Efficient Fine-Tuning (PEFT), face key limitations: in-context learning introduces additional inference computational overhead with limited performance gains, while PEFT models are prone to overfitting on the few demonstration examples. In this work, we reinterpret the forward pass of LLMs as an optimization process, a sequence of preconditioned gradient descent steps refining internal representations. Based on this connection, we propose Optimization-Inspired Few-Shot Adaptation (OFA), integrating a parameterization that learns preconditioners without introducing additional trainable parameters, and an objective that improves optimization efficiency by learning preconditioners based on a convergence bound, while simultaneously steering the optimization path toward the flat local minimum. Our method overcomes both issues of ICL-based and PEFT-based methods, and demonstrates superior performance over the existing methods on a variety of few-shot adaptation tasks in experiments.
From Gaze to Insight: Bridging Human Visual Attention and Vision Language Model Explanation for Weakly-Supervised Medical Image Segmentation
Apr 15, 2025Medical image segmentation remains challenging due to the high cost of pixel-level annotations for training. In the context of weak supervision, clinician gaze data captures regions of diagnostic interest; however, its sparsity limits its use for segmentation. In contrast, vision-language models (VLMs) provide semantic context through textual descriptions but lack the explanation precision required. Recognizing that neither source alone suffices, we propose a teacher-student framework that integrates both gaze and language supervision, leveraging their complementary strengths. Our key insight is that gaze data indicates where clinicians focus during diagnosis, while VLMs explain why those regions are significant. To implement this, the teacher model first learns from gaze points enhanced by VLM-generated descriptions of lesion morphology, establishing a foundation for guiding the student model. The teacher then directs the student through three strategies: (1) Multi-scale feature alignment to fuse visual cues with textual semantics; (2) Confidence-weighted consistency constraints to focus on reliable predictions; (3) Adaptive masking to limit error propagation in uncertain areas. Experiments on the Kvasir-SEG, NCI-ISBI, and ISIC datasets show that our method achieves Dice scores of 80.78%, 80.53%, and 84.22%, respectively-improving 3-5% over gaze baselines without increasing the annotation burden. By preserving correlations among predictions, gaze data, and lesion descriptions, our framework also maintains clinical interpretability. This work illustrates how integrating human visual attention with AI-generated semantic context can effectively overcome the limitations of individual weak supervision signals, thereby advancing the development of deployable, annotation-efficient medical AI systems. Code is available at: https://github.com/jingkunchen/FGI.git.
Is Temporal Prompting All We Need For Limited Labeled Action Recognition?
Apr 02, 2025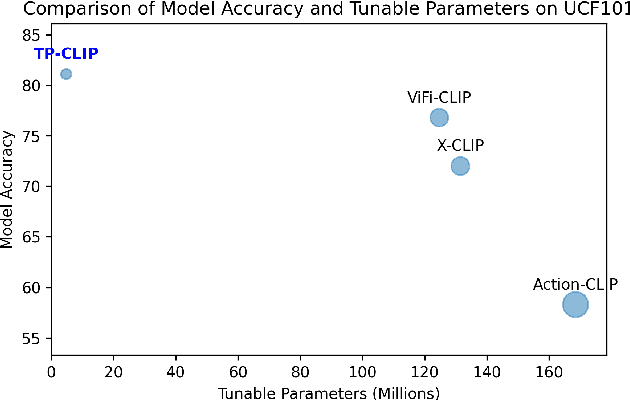
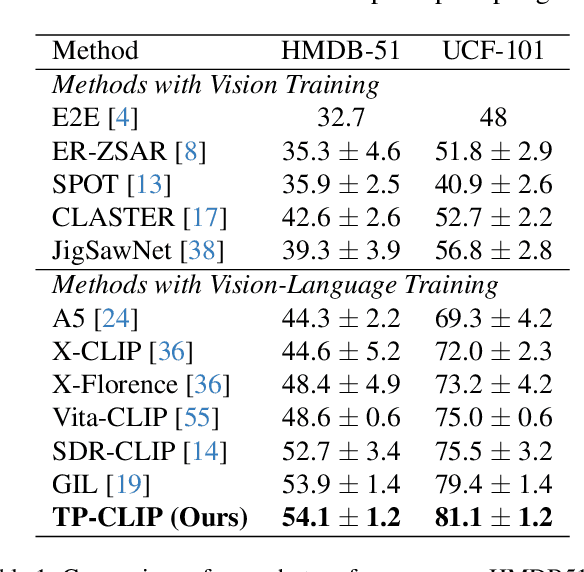
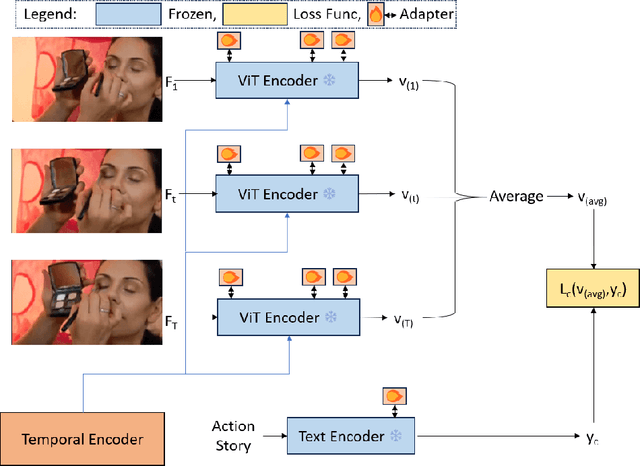
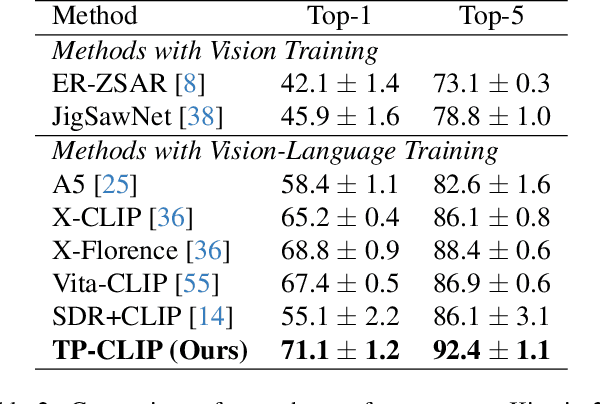
Video understanding has shown remarkable improvements in recent years, largely dependent on the availability of large scaled labeled datasets. Recent advancements in visual-language models, especially based on contrastive pretraining, have shown remarkable generalization in zero-shot tasks, helping to overcome this dependence on labeled datasets. Adaptations of such models for videos, typically involve modifying the architecture of vision-language models to cater to video data. However, this is not trivial, since such adaptations are mostly computationally intensive and struggle with temporal modeling. We present TP-CLIP, an adaptation of CLIP that leverages temporal visual prompting for temporal adaptation without modifying the core CLIP architecture. This preserves its generalization abilities. TP-CLIP efficiently integrates into the CLIP architecture, leveraging its pre-trained capabilities for video data. Extensive experiments across various datasets demonstrate its efficacy in zero-shot and few-shot learning, outperforming existing approaches with fewer parameters and computational efficiency. In particular, we use just 1/3 the GFLOPs and 1/28 the number of tuneable parameters in comparison to recent state-of-the-art and still outperform it by up to 15.8% depending on the task and dataset.
EfficientLLM: Scalable Pruning-Aware Pretraining for Architecture-Agnostic Edge Language Models
Feb 10, 2025Modern large language models (LLMs) driven by scaling laws, achieve intelligence emergency in large model sizes. Recently, the increasing concerns about cloud costs, latency, and privacy make it an urgent requirement to develop compact edge language models. Distinguished from direct pretraining that bounded by the scaling law, this work proposes the pruning-aware pretraining, focusing on retaining performance of much larger optimized models. It features following characteristics: 1) Data-scalable: we introduce minimal parameter groups in LLM and continuously optimize structural pruning, extending post-training pruning methods like LLM-Pruner and SparseGPT into the pretraining phase. 2) Architecture-agnostic: the LLM architecture is auto-designed using saliency-driven pruning, which is the first time to exceed SoTA human-designed LLMs in modern pretraining. We reveal that it achieves top-quality edge language models, termed EfficientLLM, by scaling up LLM compression and extending its boundary. EfficientLLM significantly outperforms SoTA baselines with $100M \sim 1B$ parameters, such as MobileLLM, SmolLM, Qwen2.5-0.5B, OLMo-1B, Llama3.2-1B in common sense benchmarks. As the first attempt, EfficientLLM bridges the performance gap between traditional LLM compression and direct pretraining methods, and we will fully open source at https://github.com/Xingrun-Xing2/EfficientLLM.
Exploring the latent space of diffusion models directly through singular value decomposition
Feb 04, 2025Despite the groundbreaking success of diffusion models in generating high-fidelity images, their latent space remains relatively under-explored, even though it holds significant promise for enabling versatile and interpretable image editing capabilities. The complicated denoising trajectory and high dimensionality of the latent space make it extremely challenging to interpret. Existing methods mainly explore the feature space of U-Net in Diffusion Models (DMs) instead of the latent space itself. In contrast, we directly investigate the latent space via Singular Value Decomposition (SVD) and discover three useful properties that can be used to control generation results without the requirements of data collection and maintain identity fidelity generated images. Based on these properties, we propose a novel image editing framework that is capable of learning arbitrary attributes from one pair of latent codes destined by text prompts in Stable Diffusion Models. To validate our approach, extensive experiments are conducted to demonstrate its effectiveness and flexibility in image editing. We will release our codes soon to foster further research and applications in this area.
Enhancing Generalization via Sharpness-Aware Trajectory Matching for Dataset Condensation
Feb 03, 2025



Dataset condensation aims to synthesize datasets with a few representative samples that can effectively represent the original datasets. This enables efficient training and produces models with performance close to those trained on the original sets. Most existing dataset condensation methods conduct dataset learning under the bilevel (inner- and outer-loop) based optimization. However, the preceding methods perform with limited dataset generalization due to the notoriously complicated loss landscape and expensive time-space complexity of the inner-loop unrolling of bilevel optimization. These issues deteriorate when the datasets are learned via matching the trajectories of networks trained on the real and synthetic datasets with a long horizon inner-loop. To address these issues, we introduce Sharpness-Aware Trajectory Matching (SATM), which enhances the generalization capability of learned synthetic datasets by optimising the sharpness of the loss landscape and objective simultaneously. Moreover, our approach is coupled with an efficient hypergradient approximation that is mathematically well-supported and straightforward to implement along with controllable computational overhead. Empirical evaluations of SATM demonstrate its effectiveness across various applications, including in-domain benchmarks and out-of-domain settings. Moreover, its easy-to-implement properties afford flexibility, allowing it to integrate with other advanced sharpness-aware minimizers. Our code will be released.
Cognition Chain for Explainable Psychological Stress Detection on Social Media
Dec 18, 2024



Stress is a pervasive global health issue that can lead to severe mental health problems. Early detection offers timely intervention and prevention of stress-related disorders. The current early detection models perform "black box" inference suffering from limited explainability and trust which blocks the real-world clinical application. Thanks to the generative properties introduced by the Large Language Models (LLMs), the decision and the prediction from such models are semi-interpretable through the corresponding description. However, the existing LLMs are mostly trained for general purposes without the guidance of psychological cognitive theory. To this end, we first highlight the importance of prior theory with the observation of performance boosted by the chain-of-thoughts tailored for stress detection. This method termed Cognition Chain explicates the generation of stress through a step-by-step cognitive perspective based on cognitive appraisal theory with a progress pipeline: Stimulus $\rightarrow$ Evaluation $\rightarrow$ Reaction $\rightarrow$ Stress State, guiding LLMs to provide comprehensive reasoning explanations. We further study the benefits brought by the proposed Cognition Chain format by utilising it as a synthetic dataset generation template for LLMs instruction-tuning and introduce CogInstruct, an instruction-tuning dataset for stress detection. This dataset is developed using a three-stage self-reflective annotation pipeline that enables LLMs to autonomously generate and refine instructional data. By instruction-tuning Llama3 with CogInstruct, we develop CogLLM, an explainable stress detection model. Evaluations demonstrate that CogLLM achieves outstanding performance while enhancing explainability. Our work contributes a novel approach by integrating cognitive theories into LLM reasoning processes, offering a promising direction for future explainable AI research.
AnchorInv: Few-Shot Class-Incremental Learning of Physiological Signals via Representation Space Guided Inversion
Dec 18, 2024



Deep learning models have demonstrated exceptional performance in a variety of real-world applications. These successes are often attributed to strong base models that can generalize to novel tasks with limited supporting data while keeping prior knowledge intact. However, these impressive results are based on the availability of a large amount of high-quality data, which is often lacking in specialized biomedical applications. In such fields, models are usually developed with limited data that arrive incrementally with novel categories. This requires the model to adapt to new information while preserving existing knowledge. Few-Shot Class-Incremental Learning (FSCIL) methods offer a promising approach to addressing these challenges, but they also depend on strong base models that face the same aforementioned limitations. To overcome these constraints, we propose AnchorInv following the straightforward and efficient buffer-replay strategy. Instead of selecting and storing raw data, AnchorInv generates synthetic samples guided by anchor points in the feature space. This approach protects privacy and regularizes the model for adaptation. When evaluated on three public physiological time series datasets, AnchorInv exhibits efficient knowledge forgetting prevention and improved adaptation to novel classes, surpassing state-of-the-art baselines.