 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimization-Inspired Few-Shot Adaptation for Large Language Models
May 25, 2025Large Language Models (LLMs) have demonstrated remarkable performance in real-world applications. However, adapting LLMs to novel tasks via fine-tuning often requires substantial training data and computational resources that are impractical in few-shot scenarios. Existing approaches, such as in-context learning and Parameter-Efficient Fine-Tuning (PEFT), face key limitations: in-context learning introduces additional inference computational overhead with limited performance gains, while PEFT models are prone to overfitting on the few demonstration examples. In this work, we reinterpret the forward pass of LLMs as an optimization process, a sequence of preconditioned gradient descent steps refining internal representations. Based on this connection, we propose Optimization-Inspired Few-Shot Adaptation (OFA), integrating a parameterization that learns preconditioners without introducing additional trainable parameters, and an objective that improves optimization efficiency by learning preconditioners based on a convergence bound, while simultaneously steering the optimization path toward the flat local minimum. Our method overcomes both issues of ICL-based and PEFT-based methods, and demonstrates superior performance over the existing methods on a variety of few-shot adaptation tasks in experiments.
LENS: Multi-level Evaluation of Multimodal Reasoning with Large Language Models
May 21, 2025Multimodal Large Language Models (MLLMs) have achieved significant advances in integrating visual and linguistic information, yet their ability to reason about complex and real-world scenarios remains limited. The existing benchmarks are usually constructed in the task-oriented manner without guarantee that different task samples come from the same data distribution, thus they often fall short in evaluating the synergistic effects of lower-level perceptual capabilities on higher-order reasoning. To lift this limitation, we contribute Lens, a multi-level benchmark with 3.4K contemporary images and 60K+ human-authored questions covering eight tasks and 12 daily scenarios, forming three progressive task tiers, i.e., perception, understanding, and reasoning. One feature is that each image is equipped with rich annotations for all tasks. Thus, this dataset intrinsically supports to evaluate MLLMs to handle image-invariable prompts, from basic perception to compositional reasoning. In addition, our images are manully collected from the social media, in which 53% were published later than Jan. 2025. We evaluate 15+ frontier MLLMs such as Qwen2.5-VL-72B, InternVL3-78B, GPT-4o and two reasoning models QVQ-72B-preview and Kimi-VL. These models are released later than Dec. 2024, and none of them achieve an accuracy greater than 60% in the reasoning tasks. Project page: https://github.com/Lens4MLLMs/lens. ICCV 2025 workshop page: https://lens4mllms.github.io/mars2-workshop-iccv2025/
MISE: Meta-knowledge Inheritance for Social Media-Based Stressor Estimation
May 03, 2025Stress haunts people in modern society, which may cause severe health issues if left unattended. With social media becoming an integral part of daily life, leveraging social media to detect stress has gained increasing attention. While the majority of the work focuses on classifying stress states and stress categories, this study introduce a new task aimed at estimating more specific stressors (like exam, writing paper, etc.) through users' posts on social media. Unfortunately, the diversity of stressors with many different classes but a few examples per class, combined with the consistent arising of new stressors over time, hinders the machine understanding of stressors. To this end, we cast the stressor estimation problem within a practical scenario few-shot learning setting, and propose a novel meta-learning based stressor estimation framework that is enhanced by a meta-knowledge inheritance mechanism. This model can not only learn generic stressor context through meta-learning, but also has a good generalization ability to estimate new stressors with little labeled data. A fundamental breakthrough in our approach lies in the inclusion of the meta-knowledge inheritance mechanism, which equips our model with the ability to prevent catastrophic forgetting when adapting to new stressors. The experimental results show that our model achieves state-of-the-art performance compared with the baselines. Additionally, we construct a social media-based stressor estimation dataset that can help train artificial intelligence models to facilitate human well-being. The dataset is now public at \href{https://www.kaggle.com/datasets/xinwangcs/stressor-cause-of-mental-health-problem-dataset}{\underline{Kaggle}} and \href{https://huggingface.co/datasets/XinWangcs/Stressor}{\underline{Hugging Face}}.
Bridging the Generalisation Gap: Synthetic Data Generation for Multi-Site Clinical Model Validation
Apr 29, 2025



Ensuring the generalisability of clinical machine learning (ML) models across diverse healthcare settings remains a significant challenge due to variability in patient demographics, disease prevalence, and institutional practices. Existing model evaluation approaches often rely on real-world datasets, which are limited in availability, embed confounding biases, and lack the flexibility needed for systematic experimentation. Furthermore, while generative models aim for statistical realism, they often lack transparency and explicit control over factors driving distributional shifts. In this work, we propose a novel structured synthetic data framework designed for the controlled benchmarking of model robustness, fairness, and generalisability. Unlike approaches focused solely on mimicking observed data, our framework provides explicit control over the data generating process, including site-specific prevalence variations, hierarchical subgroup effects, and structured feature interactions. This enables targeted investigation into how models respond to specific distributional shifts and potential biases. Through controlled experiments, we demonstrate the framework's ability to isolate the impact of site variations, support fairness-aware audits, and reveal generalisation failures, particularly highlighting how model complexity interacts with site-specific effects. This work contributes a reproducible, interpretable, and configurable tool designed to advance the reliable deployment of ML in clinical settings.
Deep Learning in Concealed Dense Prediction
Apr 15, 2025Deep learning is developing rapidly and handling common computer vision tasks well. It is time to pay attention to more complex vision tasks, as model size, knowledge, and reasoning capabilities continue to improve. In this paper, we introduce and review a family of complex tasks, termed Concealed Dense Prediction (CDP), which has great value in agriculture, industry, etc. CDP's intrinsic trait is that the targets are concealed in their surroundings, thus fully perceiving them requires fine-grained representations, prior knowledge, auxiliary reasoning, etc. The contributions of this review are three-fold: (i) We introduce the scope, characteristics, and challenges specific to CDP tasks and emphasize their essential differences from generic vision tasks. (ii) We develop a taxonomy based on concealment counteracting to summarize deep learning efforts in CDP through experiments on three tasks. We compare 25 state-of-the-art methods across 12 widely used concealed datasets. (iii) We discuss the potential applications of CDP in the large model era and summarize 6 potential research directions. We offer perspectives for the future development of CDP by constructing a large-scale multimodal instruction fine-tuning dataset, CvpINST, and a concealed visual perception agent, CvpAgent.
Cognition Chain for Explainable Psychological Stress Detection on Social Media
Dec 18, 2024



Stress is a pervasive global health issue that can lead to severe mental health problems. Early detection offers timely intervention and prevention of stress-related disorders. The current early detection models perform "black box" inference suffering from limited explainability and trust which blocks the real-world clinical application. Thanks to the generative properties introduced by the Large Language Models (LLMs), the decision and the prediction from such models are semi-interpretable through the corresponding description. However, the existing LLMs are mostly trained for general purposes without the guidance of psychological cognitive theory. To this end, we first highlight the importance of prior theory with the observation of performance boosted by the chain-of-thoughts tailored for stress detection. This method termed Cognition Chain explicates the generation of stress through a step-by-step cognitive perspective based on cognitive appraisal theory with a progress pipeline: Stimulus $\rightarrow$ Evaluation $\rightarrow$ Reaction $\rightarrow$ Stress State, guiding LLMs to provide comprehensive reasoning explanations. We further study the benefits brought by the proposed Cognition Chain format by utilising it as a synthetic dataset generation template for LLMs instruction-tuning and introduce CogInstruct, an instruction-tuning dataset for stress detection. This dataset is developed using a three-stage self-reflective annotation pipeline that enables LLMs to autonomously generate and refine instructional data. By instruction-tuning Llama3 with CogInstruct, we develop CogLLM, an explainable stress detection model. Evaluations demonstrate that CogLLM achieves outstanding performance while enhancing explainability. Our work contributes a novel approach by integrating cognitive theories into LLM reasoning processes, offering a promising direction for future explainable AI research.
F$^3$OCUS -- Federated Finetuning of Vision-Language Foundation Models with Optimal Client Layer Updating Strategy via Multi-objective Meta-Heuristics
Nov 17, 2024



Effective training of large Vision-Language Models (VLMs) on resource-constrained client devices in Federated Learning (FL) requires the usage of parameter-efficient fine-tuning (PEFT) strategies. To this end, we demonstrate the impact of two factors \textit{viz.}, client-specific layer importance score that selects the most important VLM layers for fine-tuning and inter-client layer diversity score that encourages diverse layer selection across clients for optimal VLM layer selection. We first theoretically motivate and leverage the principal eigenvalue magnitude of layerwise Neural Tangent Kernels and show its effectiveness as client-specific layer importance score. Next, we propose a novel layer updating strategy dubbed F$^3$OCUS that jointly optimizes the layer importance and diversity factors by employing a data-free, multi-objective, meta-heuristic optimization on the server. We explore 5 different meta-heuristic algorithms and compare their effectiveness for selecting model layers and adapter layers towards PEFT-FL. Furthermore, we release a new MedVQA-FL dataset involving overall 707,962 VQA triplets and 9 modality-specific clients and utilize it to train and evaluate our method. Overall, we conduct more than 10,000 client-level experiments on 6 Vision-Language FL task settings involving 58 medical image datasets and 4 different VLM architectures of varying sizes to demonstrate the effectiveness of the proposed method.
Applying and Evaluating Large Language Models in Mental Health Care: A Scoping Review of Human-Assessed Generative Tasks
Aug 21, 2024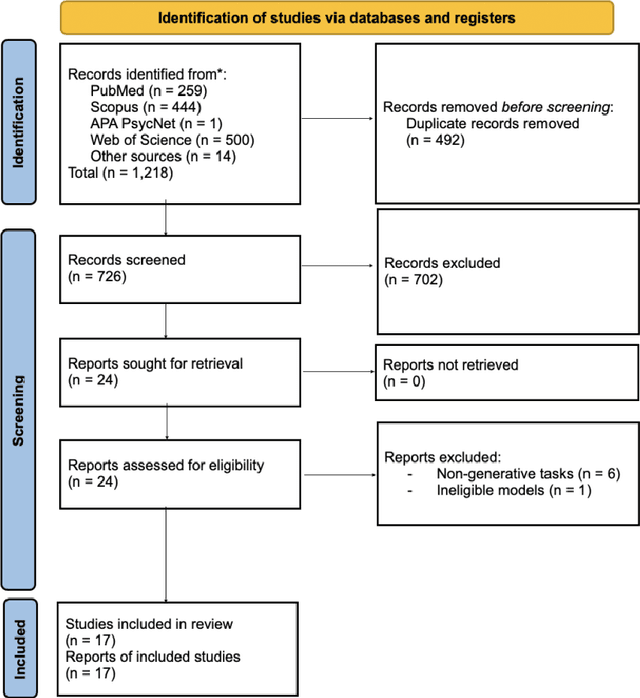


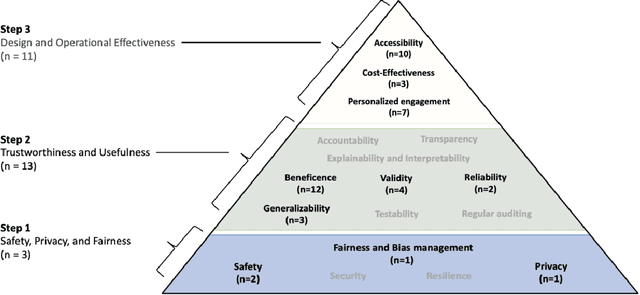
Large language models (LLMs) are emerging as promising tools for mental health care, offering scalable support through their ability to generate human-like responses. However, the effectiveness of these models in clinical settings remains unclear. This scoping review aimed to assess the current generative applications of LLMs in mental health care, focusing on studies where these models were tested with human participants in real-world scenarios. A systematic search across APA PsycNet, Scopus, PubMed, and Web of Science identified 726 unique articles, of which 17 met the inclusion criteria. These studies encompassed applications such as clinical assistance, counseling, therapy, and emotional support. However, the evaluation methods were often non-standardized, with most studies relying on ad hoc scales that limit comparability and robustness. Privacy, safety, and fairness were also frequently underexplored. Moreover, reliance on proprietary models, such as OpenAI's GPT series, raises concerns about transparency and reproducibility. While LLMs show potential in expanding mental health care access, especially in underserved areas, the current evidence does not fully support their use as standalone interventions. More rigorous, standardized evaluations and ethical oversight are needed to ensure these tools can be safely and effectively integrated into clinical practice.
Voice EHR: Introducing Multimodal Audio Data for Health
Apr 02, 2024
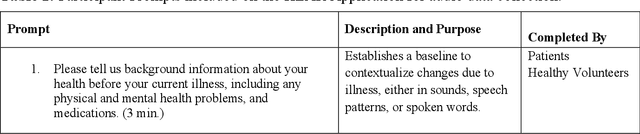

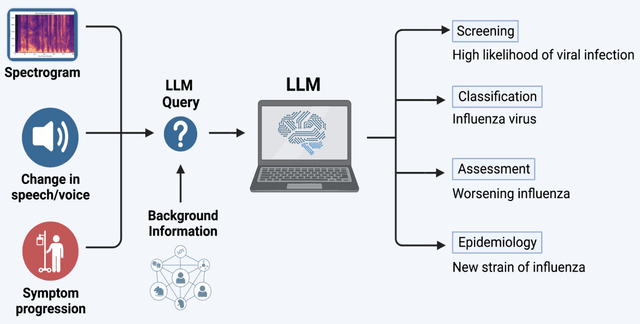
Large AI models trained on audio data may have the potential to rapidly classify patients, enhancing medical decision-making and potentially improving outcomes through early detection. Existing technologies depend on limited datasets using expensive recording equipment in high-income, English-speaking countries. This challenges deployment in resource-constrained, high-volume settings where audio data may have a profound impact. This report introduces a novel data type and a corresponding collection system that captures health data through guided questions using only a mobile/web application. This application ultimately results in an audio electronic health record (voice EHR) which may contain complex biomarkers of health from conventional voice/respiratory features, speech patterns, and language with semantic meaning - compensating for the typical limitations of unimodal clinical datasets. This report introduces a consortium of partners for global work, presents the application used for data collection, and showcases the potential of informative voice EHR to advance the scalability and diversity of audio AI.
Efficiency at Scale: Investigating the Performance of Diminutive Language Models in Clinical Tasks
Feb 16, 2024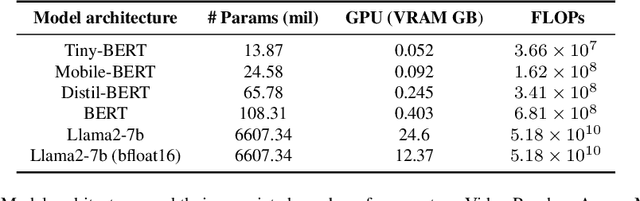
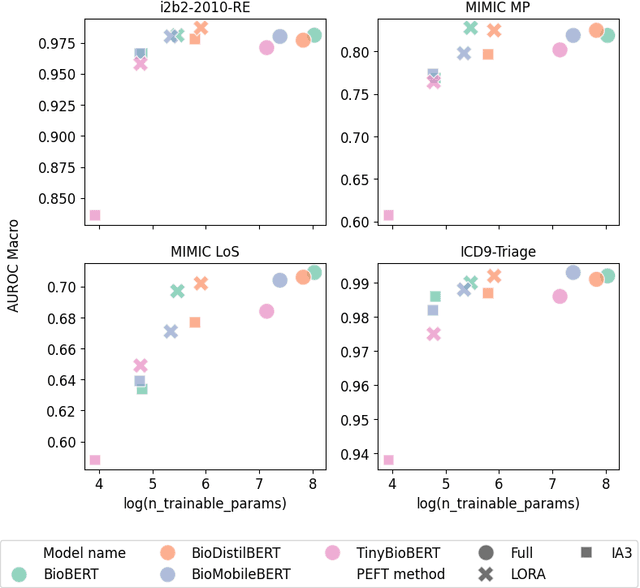
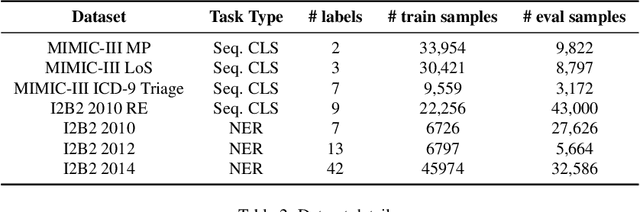
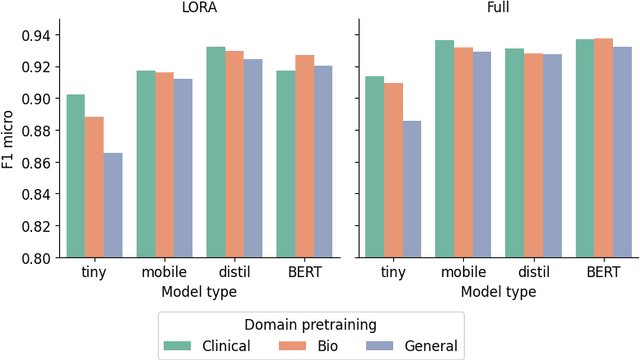
The entry of large language models (LLMs) into research and commercial spaces has led to a trend of ever-larger models, with initial promises of generalisability, followed by a widespread desire to downsize and create specialised models without the need for complete fine-tuning, using Parameter Efficient Fine-tuning (PEFT) methods. We present an investigation into the suitability of different PEFT methods to clinical decision-making tasks, across a range of model sizes, including extremely small models with as few as $25$ million parameters. Our analysis shows that the performance of most PEFT approaches varies significantly from one task to another, with the exception of LoRA, which maintains relatively high performance across all model sizes and tasks, typically approaching or matching full fine-tuned performance. The effectiveness of PEFT methods in the clinical domain is evident, particularly for specialised models which can operate on low-cost, in-house computing infrastructure. The advantages of these models, in terms of speed and reduced training costs, dramatically outweighs any performance gain from large foundation LLMs. Furthermore, we highlight how domain-specific pre-training interacts with PEFT methods and model size, and discuss how these factors interplay to provide the best efficiency-performance trade-off. Full code available at: tbd.