 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMARS2 2025 Challenge on Multimodal Reasoning: Datasets, Methods, Results, Discussion, and Outlook
Sep 17, 2025



This paper reviews the MARS2 2025 Challenge on Multimodal Reasoning. We aim to bring together different approaches in multimodal machine learning and LLMs via a large benchmark. We hope it better allows researchers to follow the state-of-the-art in this very dynamic area. Meanwhile, a growing number of testbeds have boosted the evolution of general-purpose large language models. Thus, this year's MARS2 focuses on real-world and specialized scenarios to broaden the multimodal reasoning applications of MLLMs. Our organizing team released two tailored datasets Lens and AdsQA as test sets, which support general reasoning in 12 daily scenarios and domain-specific reasoning in advertisement videos, respectively. We evaluated 40+ baselines that include both generalist MLLMs and task-specific models, and opened up three competition tracks, i.e., Visual Grounding in Real-world Scenarios (VG-RS), Visual Question Answering with Spatial Awareness (VQA-SA), and Visual Reasoning in Creative Advertisement Videos (VR-Ads). Finally, 76 teams from the renowned academic and industrial institutions have registered and 40+ valid submissions (out of 1200+) have been included in our ranking lists. Our datasets, code sets (40+ baselines and 15+ participants' methods), and rankings are publicly available on the MARS2 workshop website and our GitHub organization page https://github.com/mars2workshop/, where our updates and announcements of upcoming events will be continuously provided.
LENS: Multi-level Evaluation of Multimodal Reasoning with Large Language Models
May 21, 2025Multimodal Large Language Models (MLLMs) have achieved significant advances in integrating visual and linguistic information, yet their ability to reason about complex and real-world scenarios remains limited. The existing benchmarks are usually constructed in the task-oriented manner without guarantee that different task samples come from the same data distribution, thus they often fall short in evaluating the synergistic effects of lower-level perceptual capabilities on higher-order reasoning. To lift this limitation, we contribute Lens, a multi-level benchmark with 3.4K contemporary images and 60K+ human-authored questions covering eight tasks and 12 daily scenarios, forming three progressive task tiers, i.e., perception, understanding, and reasoning. One feature is that each image is equipped with rich annotations for all tasks. Thus, this dataset intrinsically supports to evaluate MLLMs to handle image-invariable prompts, from basic perception to compositional reasoning. In addition, our images are manully collected from the social media, in which 53% were published later than Jan. 2025. We evaluate 15+ frontier MLLMs such as Qwen2.5-VL-72B, InternVL3-78B, GPT-4o and two reasoning models QVQ-72B-preview and Kimi-VL. These models are released later than Dec. 2024, and none of them achieve an accuracy greater than 60% in the reasoning tasks. Project page: https://github.com/Lens4MLLMs/lens. ICCV 2025 workshop page: https://lens4mllms.github.io/mars2-workshop-iccv2025/
Location-Oriented Sound Event Localization and Detection with Spatial Mapping and Regression Localization
Apr 11, 2025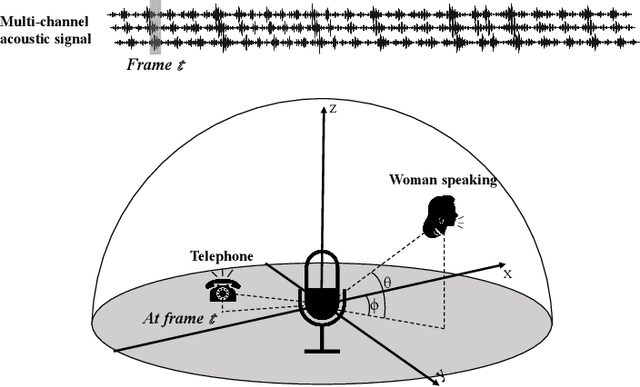
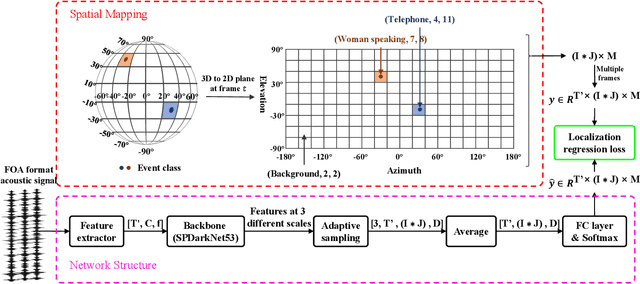
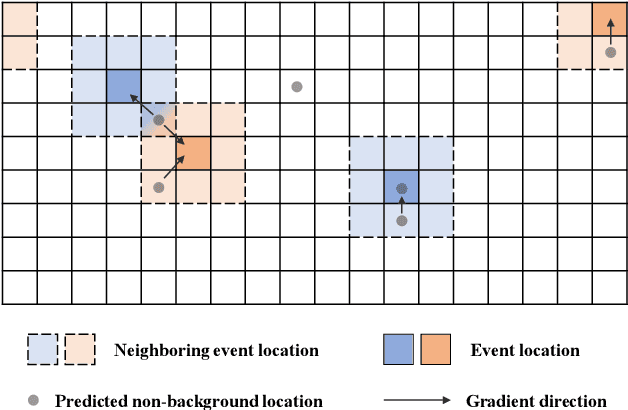

Sound Event Localization and Detection (SELD) combines the Sound Event Detection (SED) with the corresponding Direction Of Arrival (DOA). Recently, adopted event oriented multi-track methods affect the generality in polyphonic environments due to the limitation of the number of tracks. To enhance the generality in polyphonic environments, we propose Spatial Mapping and Regression Localization for SELD (SMRL-SELD). SMRL-SELD segments the 3D spatial space, mapping it to a 2D plane, and a new regression localization loss is proposed to help the results converge toward the location of the corresponding event. SMRL-SELD is location-oriented, allowing the model to learn event features based on orientation. Thus, the method enables the model to process polyphonic sounds regardless of the number of overlapping events. We conducted experiments on STARSS23 and STARSS22 datasets and our proposed SMRL-SELD outperforms the existing SELD methods in overall evaluation and polyphony environments.
Visual Grounding with Multi-modal Conditional Adaptation
Sep 08, 2024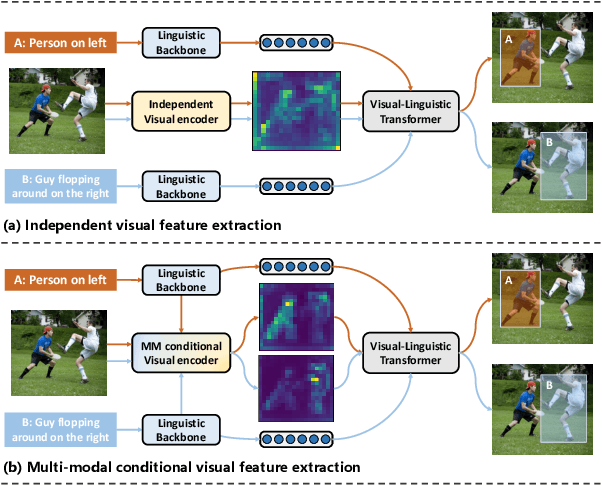
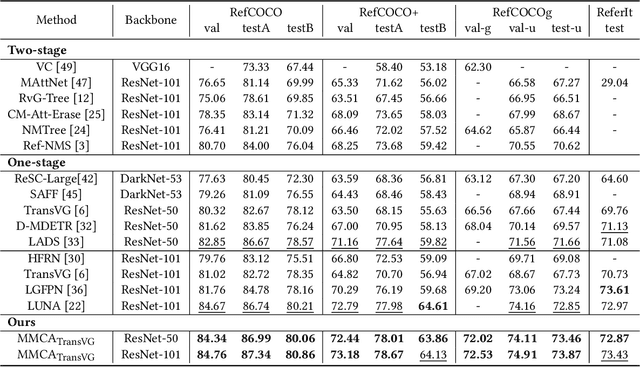
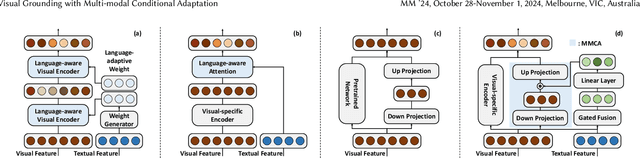
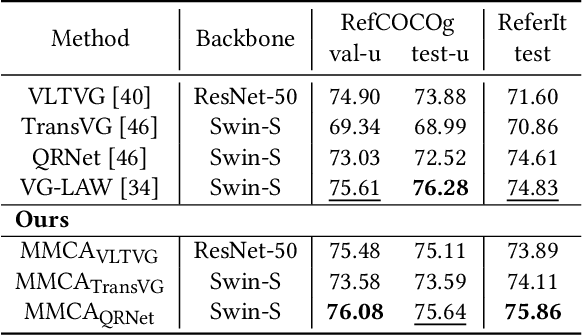
Visual grounding is the task of locating objects specified by natural language expressions. Existing methods extend generic object detection frameworks to tackle this task. They typically extract visual and textual features separately using independent visual and textual encoders, then fuse these features in a multi-modal decoder for final prediction. However, visual grounding presents unique challenges. It often involves locating objects with different text descriptions within the same image. Existing methods struggle with this task because the independent visual encoder produces identical visual features for the same image, limiting detection performance. Some recently approaches propose various language-guided visual encoders to address this issue, but they mostly rely solely on textual information and require sophisticated designs. In this paper, we introduce Multi-modal Conditional Adaptation (MMCA), which enables the visual encoder to adaptively update weights, directing its focus towards text-relevant regions. Specifically, we first integrate information from different modalities to obtain multi-modal embeddings. Then we utilize a set of weighting coefficients, which generated from the multimodal embeddings, to reorganize the weight update matrices and apply them to the visual encoder of the visual grounding model. Extensive experiments on four widely used datasets demonstrate that MMCA achieves significant improvements and state-of-the-art results. Ablation experiments further demonstrate the lightweight and efficiency of our method. Our source code is available at: https://github.com/Mr-Bigworth/MMCA.