 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProPL: Universal Semi-Supervised Ultrasound Image Segmentation via Prompt-Guided Pseudo-Labeling
Nov 19, 2025



Existing approaches for the problem of ultrasound image segmentation, whether supervised or semi-supervised, are typically specialized for specific anatomical structures or tasks, limiting their practical utility in clinical settings. In this paper, we pioneer the task of universal semi-supervised ultrasound image segmentation and propose ProPL, a framework that can handle multiple organs and segmentation tasks while leveraging both labeled and unlabeled data. At its core, ProPL employs a shared vision encoder coupled with prompt-guided dual decoders, enabling flexible task adaptation through a prompting-upon-decoding mechanism and reliable self-training via an uncertainty-driven pseudo-label calibration (UPLC) module. To facilitate research in this direction, we introduce a comprehensive ultrasound dataset spanning 5 organs and 8 segmentation tasks. Extensive experiments demonstrate that ProPL outperforms state-of-the-art methods across various metrics, establishing a new benchmark for universal ultrasound image segmentation.
MARS2 2025 Challenge on Multimodal Reasoning: Datasets, Methods, Results, Discussion, and Outlook
Sep 17, 2025



This paper reviews the MARS2 2025 Challenge on Multimodal Reasoning. We aim to bring together different approaches in multimodal machine learning and LLMs via a large benchmark. We hope it better allows researchers to follow the state-of-the-art in this very dynamic area. Meanwhile, a growing number of testbeds have boosted the evolution of general-purpose large language models. Thus, this year's MARS2 focuses on real-world and specialized scenarios to broaden the multimodal reasoning applications of MLLMs. Our organizing team released two tailored datasets Lens and AdsQA as test sets, which support general reasoning in 12 daily scenarios and domain-specific reasoning in advertisement videos, respectively. We evaluated 40+ baselines that include both generalist MLLMs and task-specific models, and opened up three competition tracks, i.e., Visual Grounding in Real-world Scenarios (VG-RS), Visual Question Answering with Spatial Awareness (VQA-SA), and Visual Reasoning in Creative Advertisement Videos (VR-Ads). Finally, 76 teams from the renowned academic and industrial institutions have registered and 40+ valid submissions (out of 1200+) have been included in our ranking lists. Our datasets, code sets (40+ baselines and 15+ participants' methods), and rankings are publicly available on the MARS2 workshop website and our GitHub organization page https://github.com/mars2workshop/, where our updates and announcements of upcoming events will be continuously provided.
LENS: Multi-level Evaluation of Multimodal Reasoning with Large Language Models
May 21, 2025Multimodal Large Language Models (MLLMs) have achieved significant advances in integrating visual and linguistic information, yet their ability to reason about complex and real-world scenarios remains limited. The existing benchmarks are usually constructed in the task-oriented manner without guarantee that different task samples come from the same data distribution, thus they often fall short in evaluating the synergistic effects of lower-level perceptual capabilities on higher-order reasoning. To lift this limitation, we contribute Lens, a multi-level benchmark with 3.4K contemporary images and 60K+ human-authored questions covering eight tasks and 12 daily scenarios, forming three progressive task tiers, i.e., perception, understanding, and reasoning. One feature is that each image is equipped with rich annotations for all tasks. Thus, this dataset intrinsically supports to evaluate MLLMs to handle image-invariable prompts, from basic perception to compositional reasoning. In addition, our images are manully collected from the social media, in which 53% were published later than Jan. 2025. We evaluate 15+ frontier MLLMs such as Qwen2.5-VL-72B, InternVL3-78B, GPT-4o and two reasoning models QVQ-72B-preview and Kimi-VL. These models are released later than Dec. 2024, and none of them achieve an accuracy greater than 60% in the reasoning tasks. Project page: https://github.com/Lens4MLLMs/lens. ICCV 2025 workshop page: https://lens4mllms.github.io/mars2-workshop-iccv2025/
LAMM-ViT: AI Face Detection via Layer-Aware Modulation of Region-Guided Attention
May 12, 2025
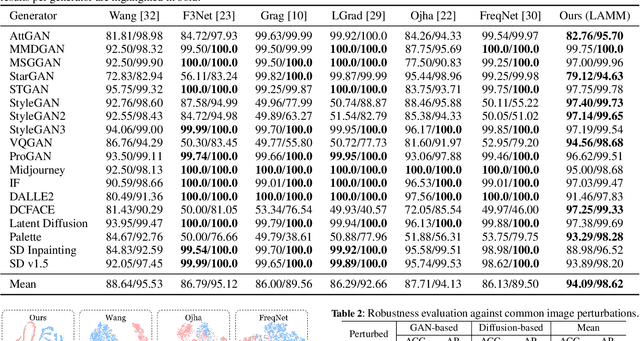
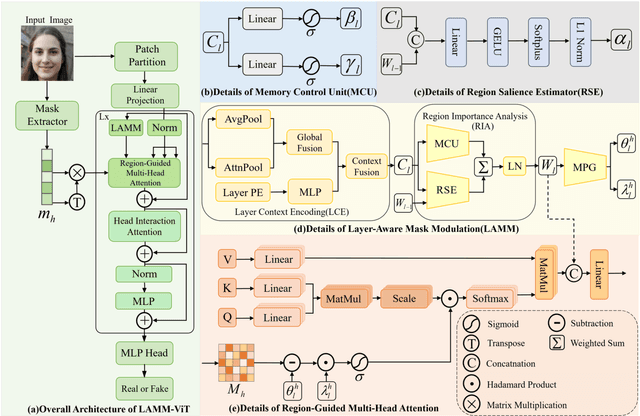
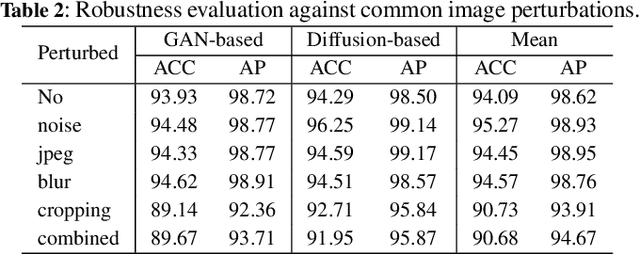
Detecting AI-synthetic faces presents a critical challenge: it is hard to capture consistent structural relationships between facial regions across diverse generation techniques. Current methods, which focus on specific artifacts rather than fundamental inconsistencies, often fail when confronted with novel generative models. To address this limitation, we introduce Layer-aware Mask Modulation Vision Transformer (LAMM-ViT), a Vision Transformer designed for robust facial forgery detection. This model integrates distinct Region-Guided Multi-Head Attention (RG-MHA) and Layer-aware Mask Modulation (LAMM) components within each layer. RG-MHA utilizes facial landmarks to create regional attention masks, guiding the model to scrutinize architectural inconsistencies across different facial areas. Crucially, the separate LAMM module dynamically generates layer-specific parameters, including mask weights and gating values, based on network context. These parameters then modulate the behavior of RG-MHA, enabling adaptive adjustment of regional focus across network depths. This architecture facilitates the capture of subtle, hierarchical forgery cues ubiquitous among diverse generation techniques, such as GANs and Diffusion Models. In cross-model generalization tests, LAMM-ViT demonstrates superior performance, achieving 94.09% mean ACC (a +5.45% improvement over SoTA) and 98.62% mean AP (a +3.09% improvement). These results demonstrate LAMM-ViT's exceptional ability to generalize and its potential for reliable deployment against evolving synthetic media threats.
Location-Oriented Sound Event Localization and Detection with Spatial Mapping and Regression Localization
Apr 11, 2025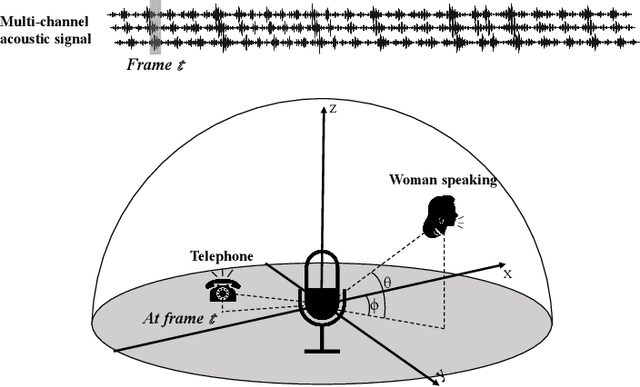
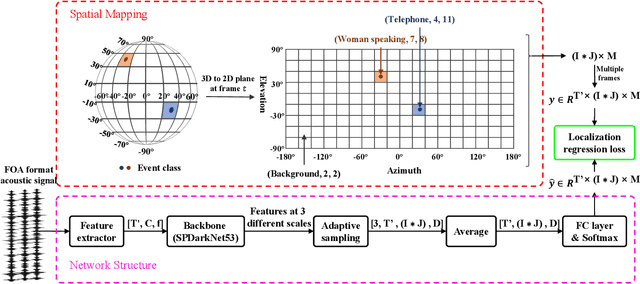
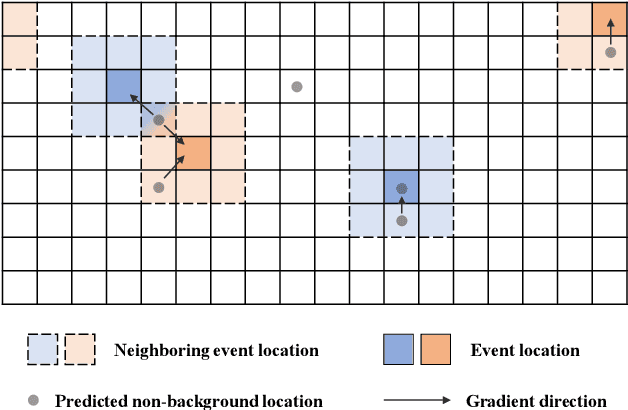

Sound Event Localization and Detection (SELD) combines the Sound Event Detection (SED) with the corresponding Direction Of Arrival (DOA). Recently, adopted event oriented multi-track methods affect the generality in polyphonic environments due to the limitation of the number of tracks. To enhance the generality in polyphonic environments, we propose Spatial Mapping and Regression Localization for SELD (SMRL-SELD). SMRL-SELD segments the 3D spatial space, mapping it to a 2D plane, and a new regression localization loss is proposed to help the results converge toward the location of the corresponding event. SMRL-SELD is location-oriented, allowing the model to learn event features based on orientation. Thus, the method enables the model to process polyphonic sounds regardless of the number of overlapping events. We conducted experiments on STARSS23 and STARSS22 datasets and our proposed SMRL-SELD outperforms the existing SELD methods in overall evaluation and polyphony environments.
AnyArtisticGlyph: Multilingual Controllable Artistic Glyph Generation
Apr 07, 2025



Artistic Glyph Image Generation (AGIG) differs from current creativity-focused generation models by offering finely controllable deterministic generation. It transfers the style of a reference image to a source while preserving its content. Although advanced and promising, current methods may reveal flaws when scrutinizing synthesized image details, often producing blurred or incorrect textures, posing a significant challenge. Hence, we introduce AnyArtisticGlyph, a diffusion-based, multilingual controllable artistic glyph generation model. It includes a font fusion and embedding module, which generates latent features for detailed structure creation, and a vision-text fusion and embedding module that uses the CLIP model to encode references and blends them with transformation caption embeddings for seamless global image generation. Moreover, we incorporate a coarse-grained feature-level loss to enhance generation accuracy. Experiments show that it produces natural, detailed artistic glyph images with state-of-the-art performance. Our project will be open-sourced on https://github.com/jiean001/AnyArtisticGlyph to advance text generation technology.
UniCrossAdapter: Multimodal Adaptation of CLIP for Radiology Report Generation
Mar 20, 2025Automated radiology report generation aims to expedite the tedious and error-prone reporting process for radiologists. While recent works have made progress, learning to align medical images and textual findings remains challenging due to the relative scarcity of labeled medical data. For example, datasets for this task are much smaller than those used for image captioning in computer vision. In this work, we propose to transfer representations from CLIP, a large-scale pre-trained vision-language model, to better capture cross-modal semantics between images and texts. However, directly applying CLIP is suboptimal due to the domain gap between natural images and radiology. To enable efficient adaptation, we introduce UniCrossAdapter, lightweight adapter modules that are incorporated into CLIP and fine-tuned on the target task while keeping base parameters fixed. The adapters are distributed across modalities and their interaction to enhance vision-language alignment. Experiments on two public datasets demonstrate the effectiveness of our approach, advancing state-of-the-art in radiology report generation. The proposed transfer learning framework provides a means of harnessing semantic knowledge from large-scale pre-trained models to tackle data-scarce medical vision-language tasks. Code is available at https://github.com/chauncey-tow/MRG-CLIP.
CausalCLIPSeg: Unlocking CLIP's Potential in Referring Medical Image Segmentation with Causal Intervention
Mar 20, 2025Referring medical image segmentation targets delineating lesions indicated by textual descriptions. Aligning visual and textual cues is challenging due to their distinct data properties. Inspired by large-scale pre-trained vision-language models, we propose CausalCLIPSeg, an end-to-end framework for referring medical image segmentation that leverages CLIP. Despite not being trained on medical data, we enforce CLIP's rich semantic space onto the medical domain by a tailored cross-modal decoding method to achieve text-to-pixel alignment. Furthermore, to mitigate confounding bias that may cause the model to learn spurious correlations instead of meaningful causal relationships, CausalCLIPSeg introduces a causal intervention module which self-annotates confounders and excavates causal features from inputs for segmentation judgments. We also devise an adversarial min-max game to optimize causal features while penalizing confounding ones. Extensive experiments demonstrate the state-of-the-art performance of our proposed method. Code is available at https://github.com/WUTCM-Lab/CausalCLIPSeg.
One-Shot Medical Video Object Segmentation via Temporal Contrastive Memory Networks
Mar 19, 2025Video object segmentation is crucial for the efficient analysis of complex medical video data, yet it faces significant challenges in data availability and annotation. We introduce the task of one-shot medical video object segmentation, which requires separating foreground and background pixels throughout a video given only the mask annotation of the first frame. To address this problem, we propose a temporal contrastive memory network comprising image and mask encoders to learn feature representations, a temporal contrastive memory bank that aligns embeddings from adjacent frames while pushing apart distant ones to explicitly model inter-frame relationships and stores these features, and a decoder that fuses encoded image features and memory readouts for segmentation. We also collect a diverse, multi-source medical video dataset spanning various modalities and anatomies to benchmark this task. Extensive experiments demonstrate state-of-the-art performance in segmenting both seen and unseen structures from a single exemplar, showing ability to generalize from scarce labels. This highlights the potential to alleviate annotation burdens for medical video analysis. Code is available at https://github.com/MedAITech/TCMN.
Striving for Simplicity: Simple Yet Effective Prior-Aware Pseudo-Labeling for Semi-Supervised Ultrasound Image Segmentation
Mar 18, 2025Medical ultrasound imaging is ubiquitous, but manual analysis struggles to keep pace. Automated segmentation can help but requires large labeled datasets, which are scarce. Semi-supervised learning leveraging both unlabeled and limited labeled data is a promising approach. State-of-the-art methods use consistency regularization or pseudo-labeling but grow increasingly complex. Without sufficient labels, these models often latch onto artifacts or allow anatomically implausible segmentations. In this paper, we present a simple yet effective pseudo-labeling method with an adversarially learned shape prior to regularize segmentations. Specifically, we devise an encoder-twin-decoder network where the shape prior acts as an implicit shape model, penalizing anatomically implausible but not ground-truth-deviating predictions. Without bells and whistles, our simple approach achieves state-of-the-art performance on two benchmarks under different partition protocols. We provide a strong baseline for future semi-supervised medical image segmentation. Code is available at https://github.com/WUTCM-Lab/Shape-Prior-Semi-Seg.