 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealisID: Scale-Robust and Fine-Controllable Identity Customization via Local and Global Complementation
Dec 22, 2024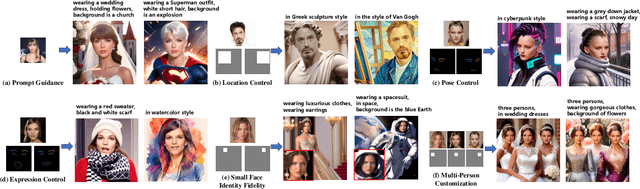
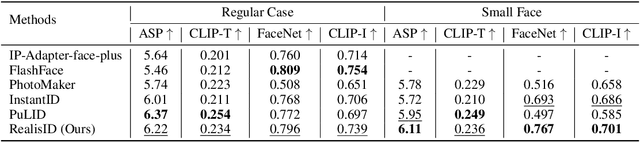
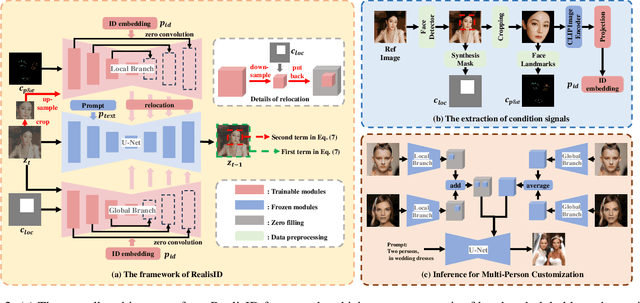
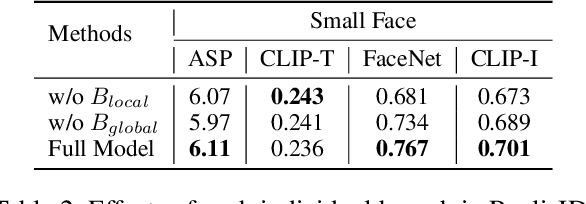
Recently, the success of text-to-image synthesis has greatly advanced the development of identity customization techniques, whose main goal is to produce realistic identity-specific photographs based on text prompts and reference face images. However, it is difficult for existing identity customization methods to simultaneously meet the various requirements of different real-world applications, including the identity fidelity of small face, the control of face location, pose and expression, as well as the customization of multiple persons. To this end, we propose a scale-robust and fine-controllable method, namely RealisID, which learns different control capabilities through the cooperation between a pair of local and global branches. Specifically, by using cropping and up-sampling operations to filter out face-irrelevant information, the local branch concentrates the fine control of facial details and the scale-robust identity fidelity within the face region. Meanwhile, the global branch manages the overall harmony of the entire image. It also controls the face location by taking the location guidance as input. As a result, RealisID can benefit from the complementarity of these two branches. Finally, by implementing our branches with two different variants of ControlNet, our method can be easily extended to handle multi-person customization, even only trained on single-person datasets. Extensive experiments and ablation studies indicate the effectiveness of RealisID and verify its ability in fulfilling all the requirements mentioned above.
SHMT: Self-supervised Hierarchical Makeup Transfer via Latent Diffusion Models
Dec 15, 2024



This paper studies the challenging task of makeup transfer, which aims to apply diverse makeup styles precisely and naturally to a given facial image. Due to the absence of paired data, current methods typically synthesize sub-optimal pseudo ground truths to guide the model training, resulting in low makeup fidelity. Additionally, different makeup styles generally have varying effects on the person face, but existing methods struggle to deal with this diversity. To address these issues, we propose a novel Self-supervised Hierarchical Makeup Transfer (SHMT) method via latent diffusion models. Following a "decoupling-and-reconstruction" paradigm, SHMT works in a self-supervised manner, freeing itself from the misguidance of imprecise pseudo-paired data. Furthermore, to accommodate a variety of makeup styles, hierarchical texture details are decomposed via a Laplacian pyramid and selectively introduced to the content representation. Finally, we design a novel Iterative Dual Alignment (IDA) module that dynamically adjusts the injection condition of the diffusion model, allowing the alignment errors caused by the domain gap between content and makeup representations to be corrected. Extensive quantitative and qualitative analyses demonstrate the effectiveness of our method. Our code is available at \url{https://github.com/Snowfallingplum/SHMT}.
Content-Style Decoupling for Unsupervised Makeup Transfer without Generating Pseudo Ground Truth
May 27, 2024The absence of real targets to guide the model training is one of the main problems with the makeup transfer task. Most existing methods tackle this problem by synthesizing pseudo ground truths (PGTs). However, the generated PGTs are often sub-optimal and their imprecision will eventually lead to performance degradation. To alleviate this issue, in this paper, we propose a novel Content-Style Decoupled Makeup Transfer (CSD-MT) method, which works in a purely unsupervised manner and thus eliminates the negative effects of generating PGTs. Specifically, based on the frequency characteristics analysis, we assume that the low-frequency (LF) component of a face image is more associated with its makeup style information, while the high-frequency (HF) component is more related to its content details. This assumption allows CSD-MT to decouple the content and makeup style information in each face image through the frequency decomposition. After that, CSD-MT realizes makeup transfer by maximizing the consistency of these two types of information between the transferred result and input images, respectively. Two newly designed loss functions are also introduced to further improve the transfer performance. Extensive quantitative and qualitative analyses show the effectiveness of our CSD-MT method. Our code is available at https://github.com/Snowfallingplum/CSD-MT.
Automatic Assessment of Divergent Thinking in Chinese Language with TransDis: A Transformer-Based Language Model Approach
Jun 26, 2023Language models have been increasingly popular for automatic creativity assessment, generating semantic distances to objectively measure the quality of creative ideas. However, there is currently a lack of an automatic assessment system for evaluating creative ideas in the Chinese language. To address this gap, we developed TransDis, a scoring system using transformer-based language models, capable of providing valid originality (quality) and flexibility (variety) scores for Alternative Uses Task (AUT) responses in Chinese. Study 1 demonstrated that the latent model-rated originality factor, comprised of three transformer-based models, strongly predicted human originality ratings, and the model-rated flexibility strongly correlated with human flexibility ratings as well. Criterion validity analyses indicated that model-rated originality and flexibility positively correlated to other creativity measures, demonstrating similar validity to human ratings. Study 2 & 3 showed that TransDis effectively distinguished participants instructed to provide creative vs. common uses (Study 2) and participants instructed to generate ideas in a flexible vs. persistent way (Study 3). Our findings suggest that TransDis can be a reliable and low-cost tool for measuring idea originality and flexibility in Chinese language, potentially paving the way for automatic creativity assessment in other languages. We offer an open platform to compute originality and flexibility for AUT responses in Chinese and over 50 other languages (https://osf.io/59jv2/).
ESPT: A Self-Supervised Episodic Spatial Pretext Task for Improving Few-Shot Learning
Apr 26, 2023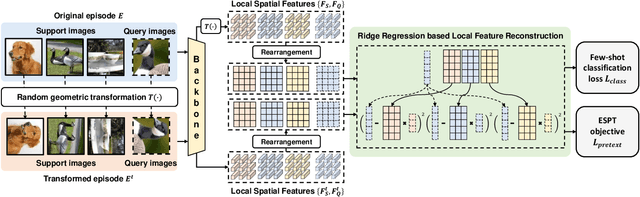
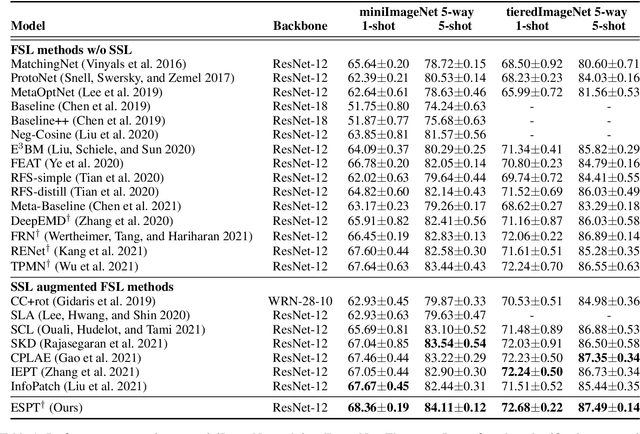
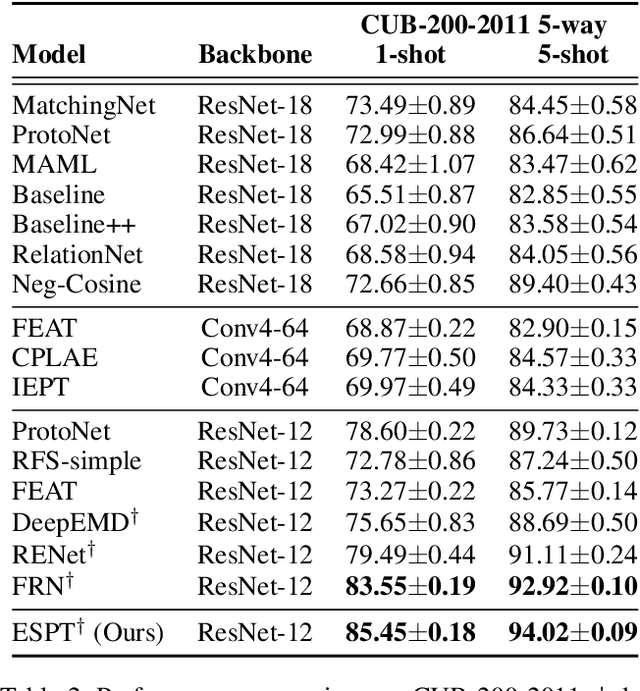
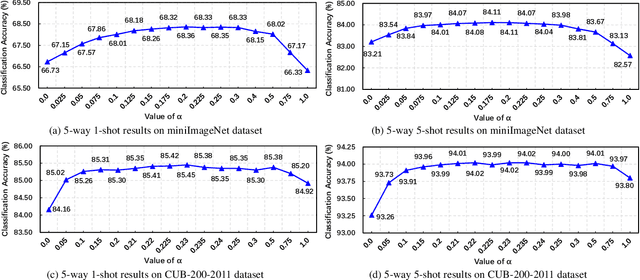
Self-supervised learning (SSL) techniques have recently been integrated into the few-shot learning (FSL) framework and have shown promising results in improving the few-shot image classification performance. However, existing SSL approaches used in FSL typically seek the supervision signals from the global embedding of every single image. Therefore, during the episodic training of FSL, these methods cannot capture and fully utilize the local visual information in image samples and the data structure information of the whole episode, which are beneficial to FSL. To this end, we propose to augment the few-shot learning objective with a novel self-supervised Episodic Spatial Pretext Task (ESPT). Specifically, for each few-shot episode, we generate its corresponding transformed episode by applying a random geometric transformation to all the images in it. Based on these, our ESPT objective is defined as maximizing the local spatial relationship consistency between the original episode and the transformed one. With this definition, the ESPT-augmented FSL objective promotes learning more transferable feature representations that capture the local spatial features of different images and their inter-relational structural information in each input episode, thus enabling the model to generalize better to new categories with only a few samples. Extensive experiments indicate that our ESPT method achieves new state-of-the-art performance for few-shot image classification on three mainstay benchmark datasets. The source code will be available at: https://github.com/Whut-YiRong/ESPT.
SSAT: A Symmetric Semantic-Aware Transformer Network for Makeup Transfer and Removal
Dec 07, 2021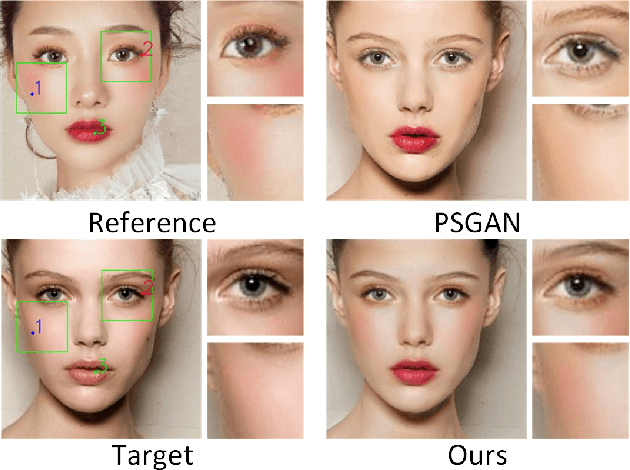
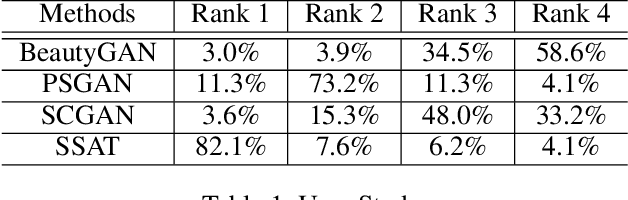
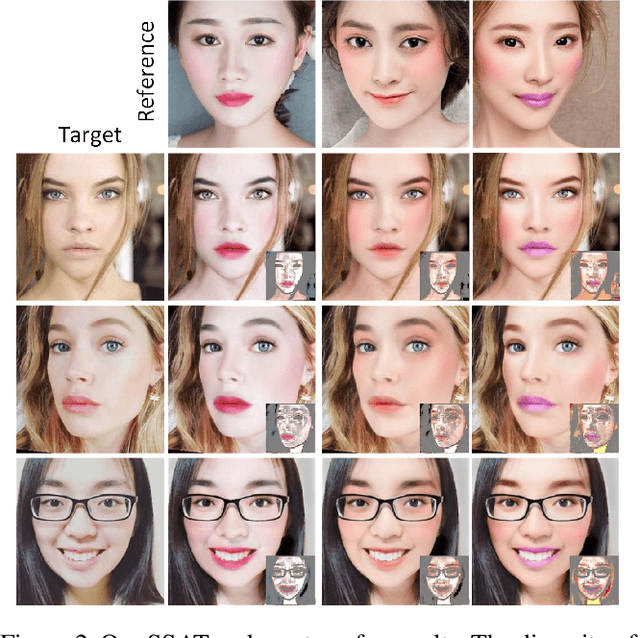
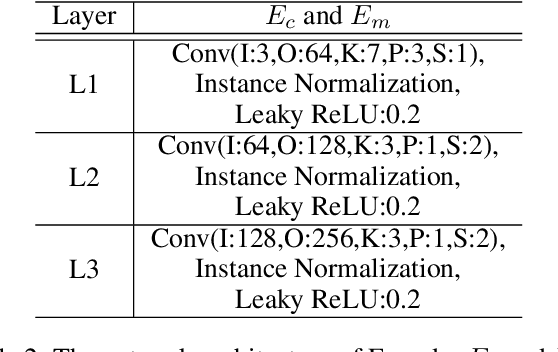
Makeup transfer is not only to extract the makeup style of the reference image, but also to render the makeup style to the semantic corresponding position of the target image. However, most existing methods focus on the former and ignore the latter, resulting in a failure to achieve desired results. To solve the above problems, we propose a unified Symmetric Semantic-Aware Transformer (SSAT) network, which incorporates semantic correspondence learning to realize makeup transfer and removal simultaneously. In SSAT, a novel Symmetric Semantic Corresponding Feature Transfer (SSCFT) module and a weakly supervised semantic loss are proposed to model and facilitate the establishment of accurate semantic correspondence. In the generation process, the extracted makeup features are spatially distorted by SSCFT to achieve semantic alignment with the target image, then the distorted makeup features are combined with unmodified makeup irrelevant features to produce the final result. Experiments show that our method obtains more visually accurate makeup transfer results, and user study in comparison with other state-of-the-art makeup transfer methods reflects the superiority of our method. Besides, we verify the robustness of the proposed method in the difference of expression and pose, object occlusion scenes, and extend it to video makeup transfer. Code will be available at https://gitee.com/sunzhaoyang0304/ssat-msp.
Local Facial Makeup Transfer via Disentangled Representation
Mar 27, 2020
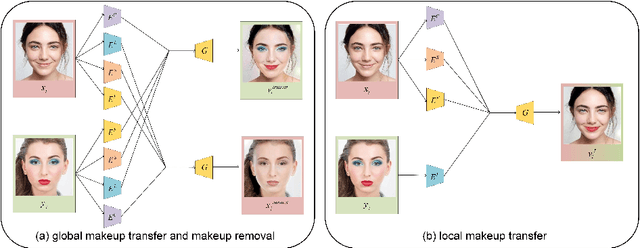
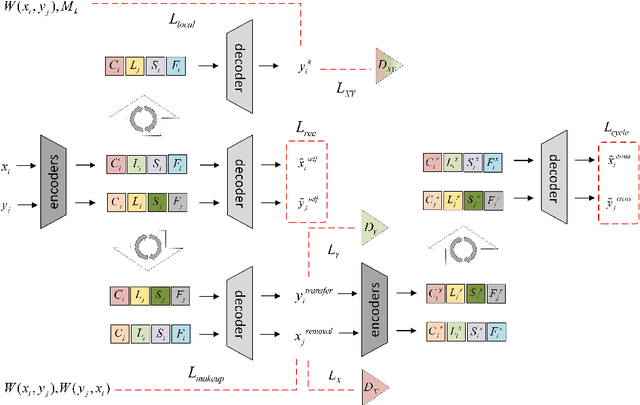

Facial makeup transfer aims to render a non-makeup face image in an arbitrary given makeup one while preserving face identity. The most advanced method separates makeup style information from face images to realize makeup transfer. However, makeup style includes several semantic clear local styles which are still entangled together. In this paper, we propose a novel unified adversarial disentangling network to further decompose face images into four independent components, i.e., personal identity, lips makeup style, eyes makeup style and face makeup style. Owing to the further disentangling of makeup style, our method can not only control the degree of global makeup style, but also flexibly regulate the degree of local makeup styles which any other approaches can't do. For makeup removal, different from other methods which regard makeup removal as the reverse process of makeup, we integrate the makeup transfer with the makeup removal into one uniform framework and obtain multiple makeup removal results. Extensive experiments have demonstrated that our approach can produce more realistic and accurate makeup transfer results compared to the state-of-the-art methods.
Directional Regularized Tensor Modeling for Video Rain Streaks Removal
Feb 19, 2019
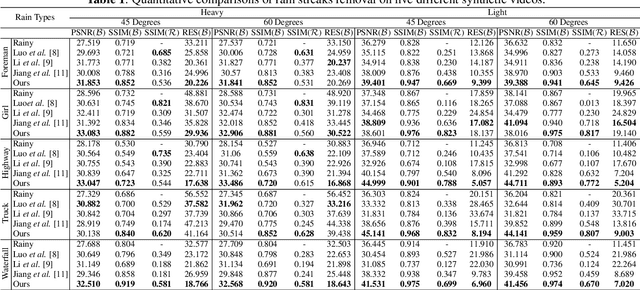
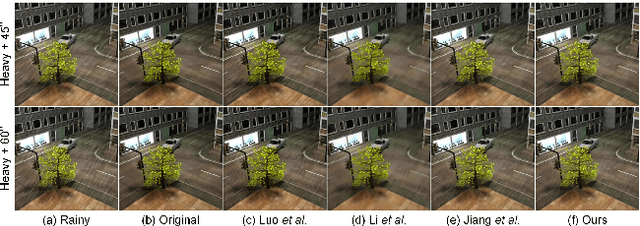
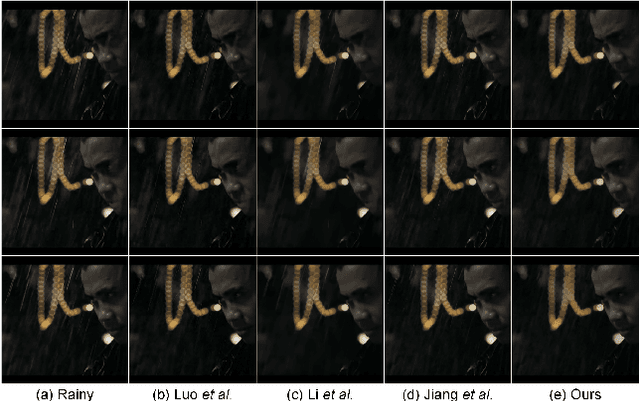
Outdoor videos sometimes contain unexpected rain streaks due to the rainy weather, which bring negative effects on subsequent computer vision applications, e.g., video surveillance, object recognition and tracking, etc. In this paper, we propose a directional regularized tensor-based video deraining model by taking into consideration the arbitrary direction of rain streaks. In particular, the sparsity of rain streaks in spatial and derivative domains, the spatiotemporal sparsity and low-rank property of video background are incorporated into the proposed method. Different from many previous methods under the assumption of vertically falling rain streaks, we consider a more realistic assumption that all the rain streaks in a video fall in an approximately similar arbitrary direction. The resulting complicated optimization problem will be effectively solved through an alternating direction method. Comprehensive experiments on both synthetic and realistic datasets have demonstrated the superiority of the proposed deraining method.