 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models Perform on Par with Experts Identifying Mental Health Factors in Adolescent Online Forums
Apr 26, 2024



Mental health in children and adolescents has been steadily deteriorating over the past few years. The recent advent of Large Language Models (LLMs) offers much hope for cost and time efficient scaling of monitoring and intervention, yet despite specifically prevalent issues such as school bullying and eating disorders, previous studies on have not investigated performance in this domain or for open information extraction where the set of answers is not predetermined. We create a new dataset of Reddit posts from adolescents aged 12-19 annotated by expert psychiatrists for the following categories: TRAUMA, PRECARITY, CONDITION, SYMPTOMS, SUICIDALITY and TREATMENT and compare expert labels to annotations from two top performing LLMs (GPT3.5 and GPT4). In addition, we create two synthetic datasets to assess whether LLMs perform better when annotating data as they generate it. We find GPT4 to be on par with human inter-annotator agreement and performance on synthetic data to be substantially higher, however we find the model still occasionally errs on issues of negation and factuality and higher performance on synthetic data is driven by greater complexity of real data rather than inherent advantage.
Developing Healthcare Language Model Embedding Spaces
Mar 28, 2024Pre-trained Large Language Models (LLMs) often struggle on out-of-domain datasets like healthcare focused text. We explore specialized pre-training to adapt smaller LLMs to different healthcare datasets. Three methods are assessed: traditional masked language modeling, Deep Contrastive Learning for Unsupervised Textual Representations (DeCLUTR), and a novel pre-training objective utilizing metadata categories from the healthcare settings. These schemes are evaluated on downstream document classification tasks for each dataset, with additional analysis of the resultant embedding spaces. Contrastively trained models outperform other approaches on the classification tasks, delivering strong performance from limited labeled data and with fewer model parameter updates required. While metadata-based pre-training does not further improve classifications across the datasets, it yields interesting embedding cluster separability. All domain adapted LLMs outperform their publicly available general base LLM, validating the importance of domain-specialization. This research illustrates efficient approaches to instill healthcare competency in compact LLMs even under tight computational budgets, an essential capability for responsible and sustainable deployment in local healthcare settings. We provide pre-training guidelines for specialized healthcare LLMs, motivate continued inquiry into contrastive objectives, and demonstrates adaptation techniques to align small LLMs with privacy-sensitive medical tasks.
Bespoke Large Language Models for Digital Triage Assistance in Mental Health Care
Mar 28, 2024Contemporary large language models (LLMs) may have utility for processing unstructured, narrative free-text clinical data contained in electronic health records (EHRs) -- a particularly important use-case for mental health where a majority of routinely-collected patient data lacks structured, machine-readable content. A significant problem for the the United Kingdom's National Health Service (NHS) are the long waiting lists for specialist mental healthcare. According to NHS data, in each month of 2023, there were between 370,000 and 470,000 individual new referrals into secondary mental healthcare services. Referrals must be triaged by clinicians, using clinical information contained in the patient's EHR to arrive at a decision about the most appropriate mental healthcare team to assess and potentially treat these patients. The ability to efficiently recommend a relevant team by ingesting potentially voluminous clinical notes could help services both reduce referral waiting times and with the right technology, improve the evidence available to justify triage decisions. We present and evaluate three different approaches for LLM-based, end-to-end ingestion of variable-length clinical EHR data to assist clinicians when triaging referrals. Our model is able to deliver triage recommendations consistent with existing clinical practices and it's architecture was implemented on a single GPU, making it practical for implementation in resource-limited NHS environments where private implementations of LLM technology will be necessary to ensure confidential clinical data is appropriately controlled and governed.
Efficiency at Scale: Investigating the Performance of Diminutive Language Models in Clinical Tasks
Feb 16, 2024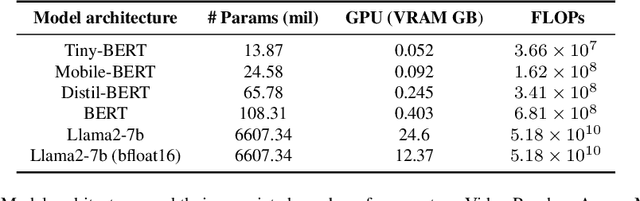
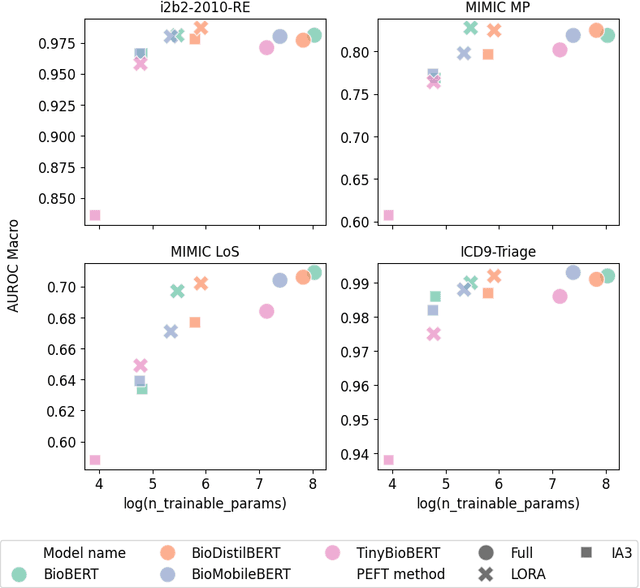
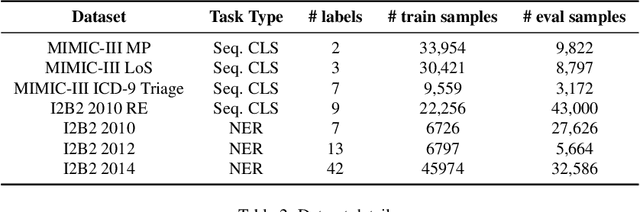
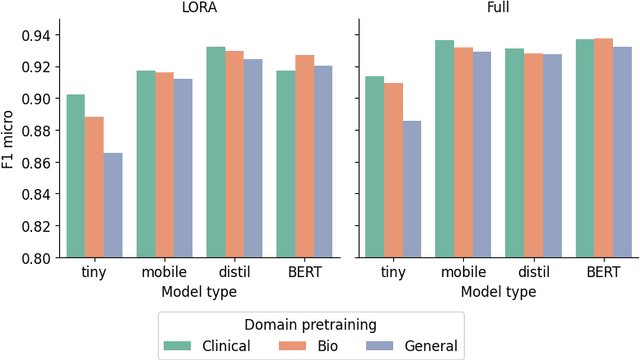
The entry of large language models (LLMs) into research and commercial spaces has led to a trend of ever-larger models, with initial promises of generalisability, followed by a widespread desire to downsize and create specialised models without the need for complete fine-tuning, using Parameter Efficient Fine-tuning (PEFT) methods. We present an investigation into the suitability of different PEFT methods to clinical decision-making tasks, across a range of model sizes, including extremely small models with as few as $25$ million parameters. Our analysis shows that the performance of most PEFT approaches varies significantly from one task to another, with the exception of LoRA, which maintains relatively high performance across all model sizes and tasks, typically approaching or matching full fine-tuned performance. The effectiveness of PEFT methods in the clinical domain is evident, particularly for specialised models which can operate on low-cost, in-house computing infrastructure. The advantages of these models, in terms of speed and reduced training costs, dramatically outweighs any performance gain from large foundation LLMs. Furthermore, we highlight how domain-specific pre-training interacts with PEFT methods and model size, and discuss how these factors interplay to provide the best efficiency-performance trade-off. Full code available at: tbd.
Detecting the Clinical Features of Difficult-to-Treat Depression using Synthetic Data from Large Language Models
Feb 12, 2024



Difficult-to-treat depression (DTD) has been proposed as a broader and more clinically comprehensive perspective on a person's depressive disorder where despite treatment, they continue to experience significant burden. We sought to develop a Large Language Model (LLM)-based tool capable of interrogating routinely-collected, narrative (free-text) electronic health record (EHR) data to locate published prognostic factors that capture the clinical syndrome of DTD. In this work, we use LLM-generated synthetic data (GPT3.5) and a Non-Maximum Suppression (NMS) algorithm to train a BERT-based span extraction model. The resulting model is then able to extract and label spans related to a variety of relevant positive and negative factors in real clinical data (i.e. spans of text that increase or decrease the likelihood of a patient matching the DTD syndrome). We show it is possible to obtain good overall performance (0.70 F1 across polarity) on real clinical data on a set of as many as 20 different factors, and high performance (0.85 F1 with 0.95 precision) on a subset of important DTD factors such as history of abuse, family history of affective disorder, illness severity and suicidality by training the model exclusively on synthetic data. Our results show promise for future healthcare applications especially in applications where traditionally, highly confidential medical data and human-expert annotation would normally be required.
Clinical Prompt Learning with Frozen Language Models
May 11, 2022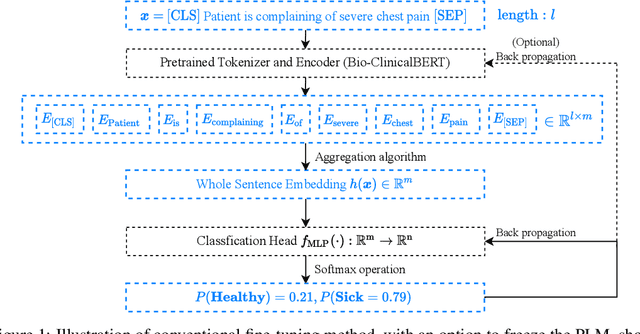
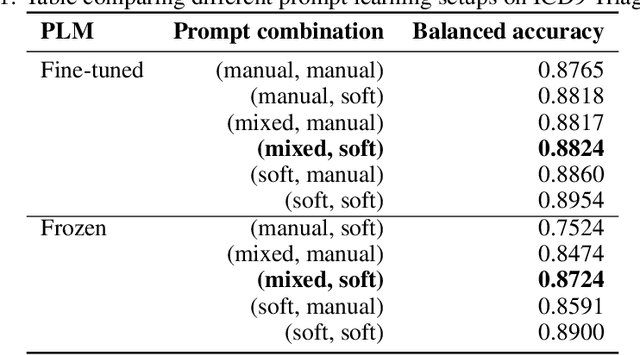
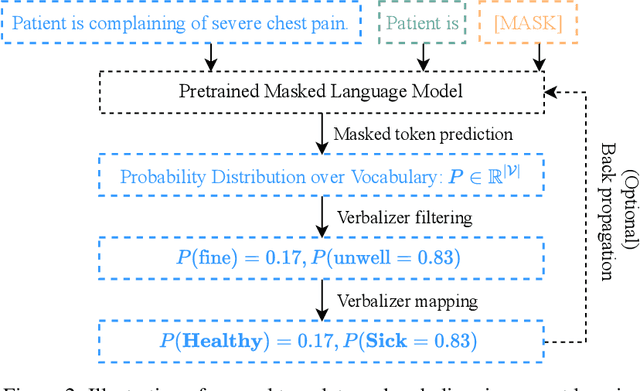

Prompt learning is a new paradigm in the Natural Language Processing (NLP) field which has shown impressive performance on a number of natural language tasks with common benchmarking text datasets in full, few-shot, and zero-shot train-evaluation setups. Recently, it has even been observed that large but frozen pre-trained language models (PLMs) with prompt learning outperform smaller but fine-tuned models. However, as with many recent NLP trends, the performance of even the largest PLMs such as GPT-3 do not perform well on specialized domains (e.g. medical text), and the common practice to achieve State of the Art (SoTA) results still consists of pre-training and fine-tuning the PLMs on downstream tasks. The reliance on fine-tuning large PLMs is problematic in clinical settings where data is often held in non-GPU environments, and more resource efficient methods of training specialized domain models is crucial. We investigated the viability of prompt learning on clinically meaningful decision tasks and directly compared with more traditional fine-tuning methods. Results are partially in line with the prompt learning literature, with prompt learning able to match or improve on traditional fine-tuning with substantially fewer trainable parameters and requiring less training data. We argue that prompt learning therefore provides lower computational resource costs applicable to clinical settings, that can serve as an alternative to fine-tuning ever increasing in size PLMs. Complementary code to reproduce experiments presented in this work can be found at: https://github.com/NtaylorOX/Public_Clinical_Prompt.
Rationale production to support clinical decision-making
Nov 15, 2021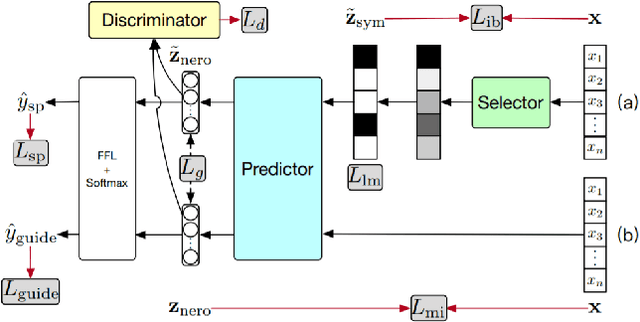
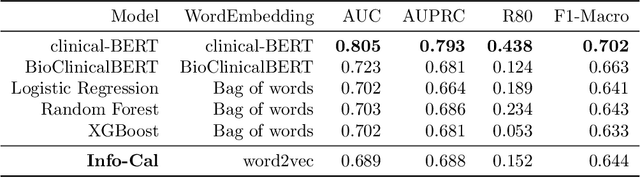

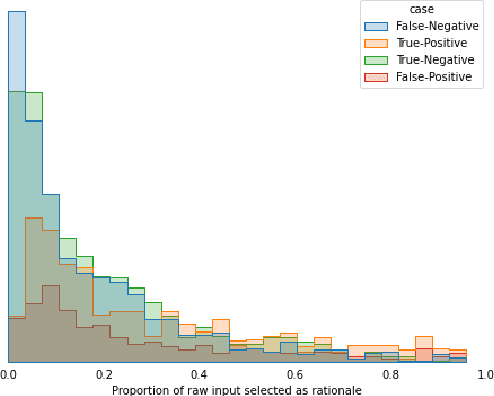
The development of neural networks for clinical artificial intelligence (AI) is reliant on interpretability, transparency, and performance. The need to delve into the black-box neural network and derive interpretable explanations of model output is paramount. A task of high clinical importance is predicting the likelihood of a patient being readmitted to hospital in the near future to enable efficient triage. With the increasing adoption of electronic health records (EHRs), there is great interest in applications of natural language processing (NLP) to clinical free-text contained within EHRs. In this work, we apply InfoCal, the current state-of-the-art model that produces extractive rationales for its predictions, to the task of predicting hospital readmission using hospital discharge notes. We compare extractive rationales produced by InfoCal to competitive transformer-based models pretrained on clinical text data and for which the attention mechanism can be used for interpretation. We find each presented model with selected interpretability or feature importance methods yield varying results, with clinical language domain expertise and pretraining critical to performance and subsequent interpretability.
An efficient representation of chronological events in medical texts
Oct 24, 2020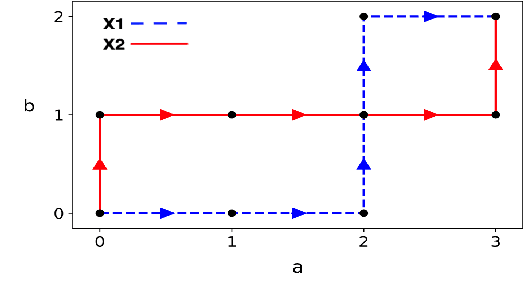
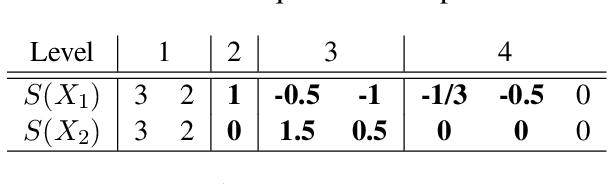

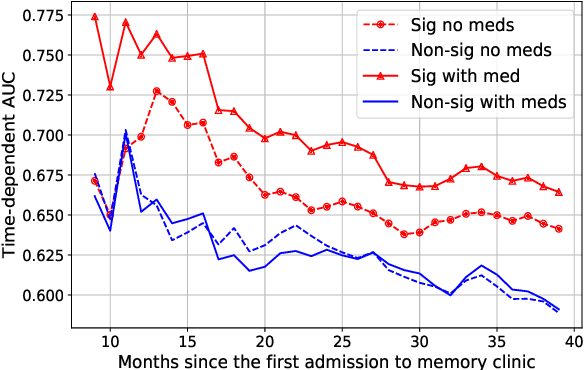
In this work we addressed the problem of capturing sequential information contained in longitudinal electronic health records (EHRs). Clinical notes, which is a particular type of EHR data, are a rich source of information and practitioners often develop clever solutions how to maximise the sequential information contained in free-texts. We proposed a systematic methodology for learning from chronological events available in clinical notes. The proposed methodological {\it path signature} framework creates a non-parametric hierarchical representation of sequential events of any type and can be used as features for downstream statistical learning tasks. The methodology was developed and externally validated using the largest in the UK secondary care mental health EHR data on a specific task of predicting survival risk of patients diagnosed with Alzheimer's disease. The signature-based model was compared to a common survival random forest model. Our results showed a 15.4$\%$ increase of risk prediction AUC at the time point of 20 months after the first admission to a specialist memory clinic and the signature method outperformed the baseline mixed-effects model by 13.2 $\%$.
Population Gradients improve performance across data-sets and architectures in object classification
Oct 23, 2020
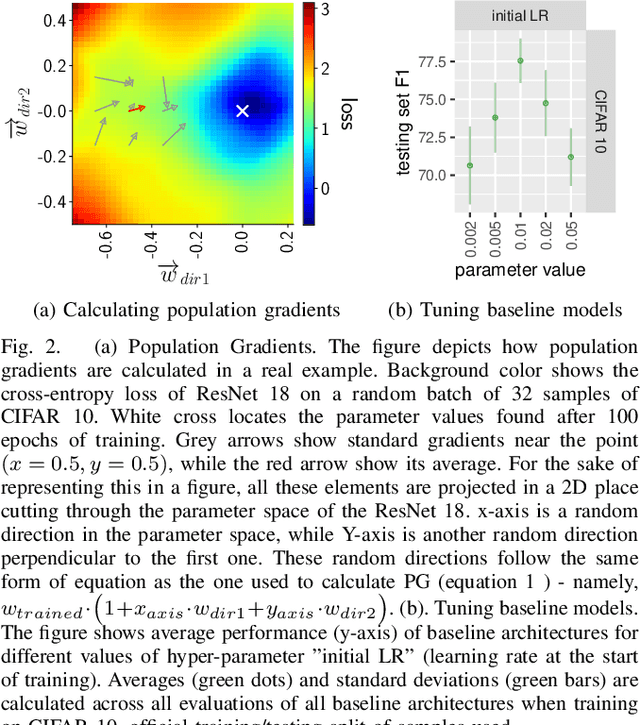
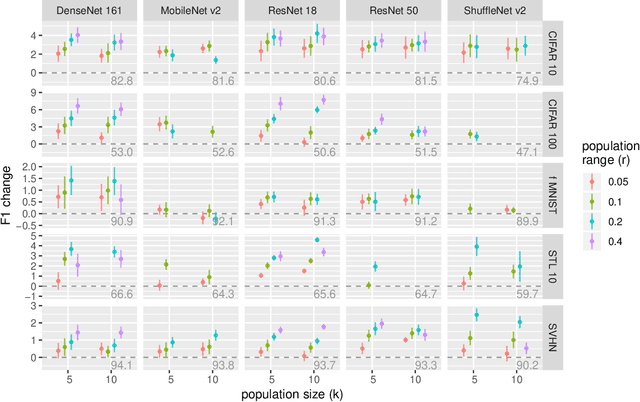
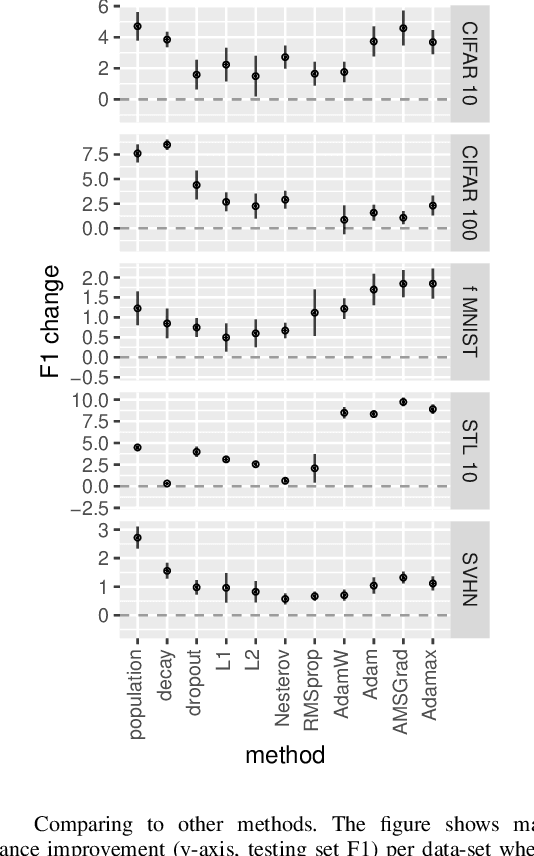
The most successful methods such as ReLU transfer functions, batch normalization, Xavier initialization, dropout, learning rate decay, or dynamic optimizers, have become standards in the field due, particularly, to their ability to increase the performance of Neural Networks (NNs) significantly and in almost all situations. Here we present a new method to calculate the gradients while training NNs, and show that it significantly improves final performance across architectures, data-sets, hyper-parameter values, training length, and model sizes, including when it is being combined with other common performance-improving methods (such as the ones mentioned above). Besides being effective in the wide array situations that we have tested, the increase in performance (e.g. F1) it provides is as high or higher than this one of all the other widespread performance-improving methods that we have compared against. We call our method Population Gradients (PG), and it consists on using a population of NNs to calculate a non-local estimation of the gradient, which is closer to the theoretical exact gradient (i.e. this one obtainable only with an infinitely big data-set) of the error function than the empirical gradient (i.e. this one obtained with the real finite data-set).
Med7: a transferable clinical natural language processing model for electronic health records
Mar 03, 2020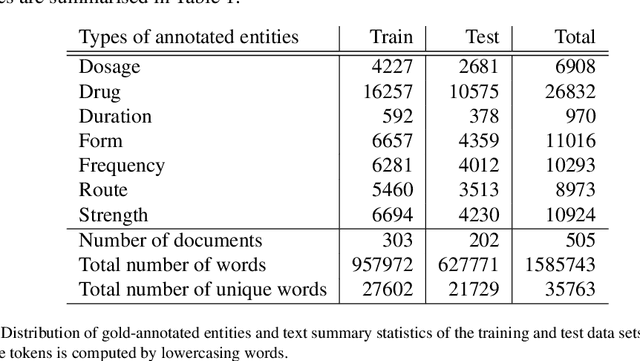
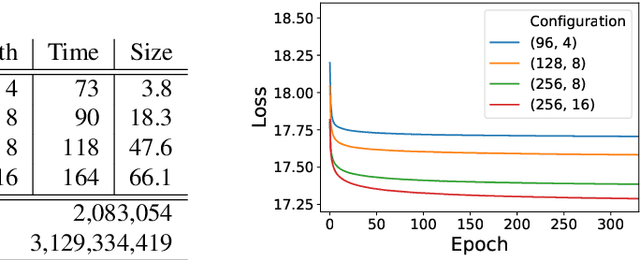
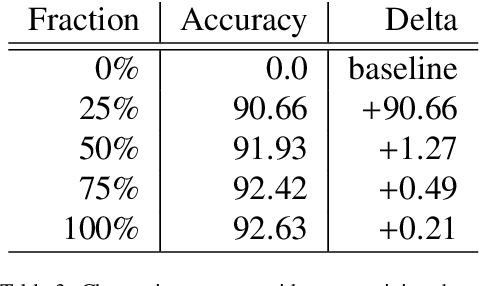
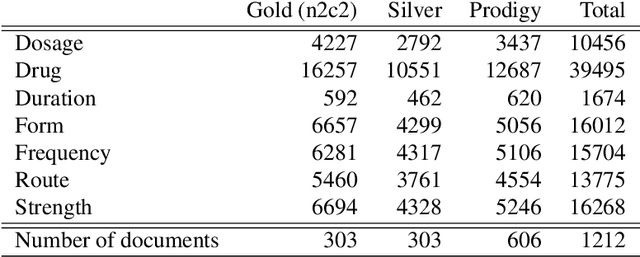
The field of clinical natural language processing has been advanced significantly since the introduction of deep learning models. The self-supervised representation learning and the transfer learning paradigm became the methods of choice in many natural language processing application, in particular in the settings with the dearth of high quality manually annotated data. Electronic health record systems are ubiquitous and the majority of patients' data are now being collected electronically and in particular in the form of free text. Identification of medical concepts and information extraction is a challenging task, yet important ingredient for parsing unstructured data into structured and tabulated format for downstream analytical tasks. In this work we introduced a named-entity recognition model for clinical natural language processing. The model is trained to recognise seven categories: drug names, route, frequency, dosage, strength, form, duration. The model was first self-supervisedly pre-trained by predicting the next word, using a collection of 2 million free-text patients' records from MIMIC-III corpora and then fine-tuned on the named-entity recognition task. The model achieved a lenient (strict) micro-averaged F1 score of 0.957 (0.893) across all seven categories. Additionally, we evaluated the transferability of the developed model using the data from the Intensive Care Unit in the US to secondary care mental health records (CRIS) in the UK. A direct application of the trained NER model to CRIS data resulted in reduced performance of F1=0.762, however after fine-tuning on a small sample from CRIS, the model achieved a reasonable performance of F1=0.944. This demonstrated that despite a close similarity between the data sets and the NER tasks, it is essential to fine-tune on the target domain data in order to achieve more accurate results.