 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Pre-trained Language Model Sensitivity via Mask Specific losses: A case study on Biomedical NER
Mar 28, 2024


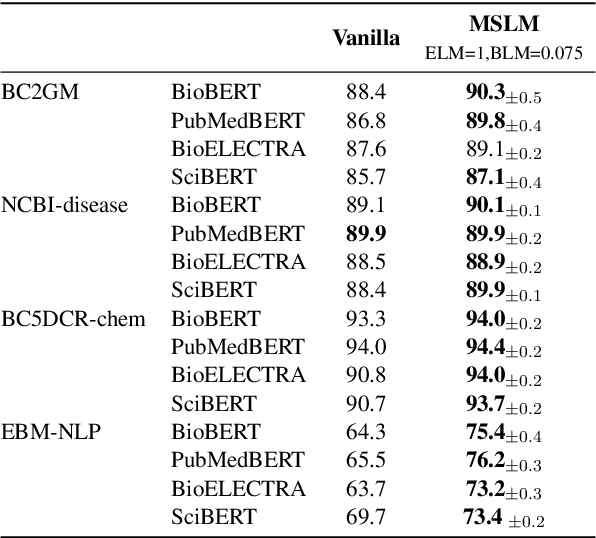
Adapting language models (LMs) to novel domains is often achieved through fine-tuning a pre-trained LM (PLM) on domain-specific data. Fine-tuning introduces new knowledge into an LM, enabling it to comprehend and efficiently perform a target domain task. Fine-tuning can however be inadvertently insensitive if it ignores the wide array of disparities (e.g in word meaning) between source and target domains. For instance, words such as chronic and pressure may be treated lightly in social conversations, however, clinically, these words are usually an expression of concern. To address insensitive fine-tuning, we propose Mask Specific Language Modeling (MSLM), an approach that efficiently acquires target domain knowledge by appropriately weighting the importance of domain-specific terms (DS-terms) during fine-tuning. MSLM jointly masks DS-terms and generic words, then learns mask-specific losses by ensuring LMs incur larger penalties for inaccurately predicting DS-terms compared to generic words. Results of our analysis show that MSLM improves LMs sensitivity and detection of DS-terms. We empirically show that an optimal masking rate not only depends on the LM, but also on the dataset and the length of sequences. Our proposed masking strategy outperforms advanced masking strategies such as span- and PMI-based masking.
Clinical Prompt Learning with Frozen Language Models
May 11, 2022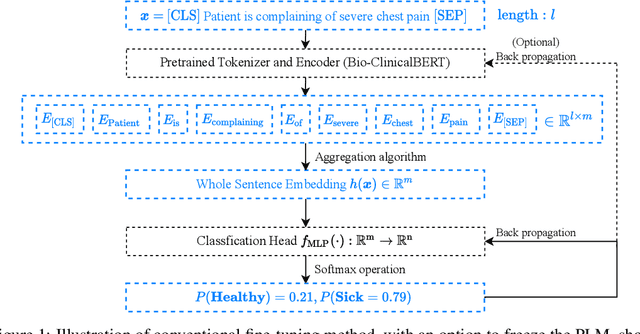
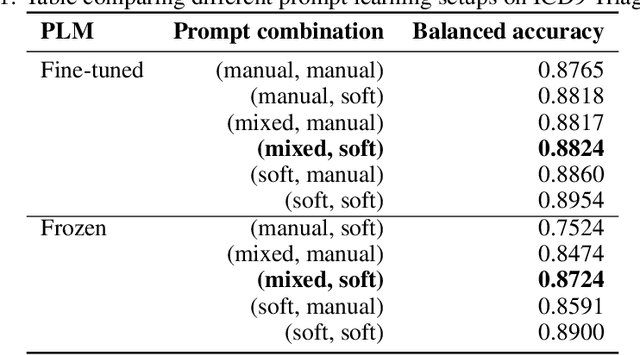
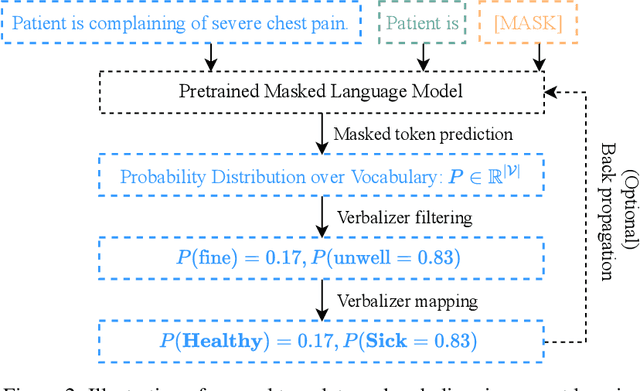

Prompt learning is a new paradigm in the Natural Language Processing (NLP) field which has shown impressive performance on a number of natural language tasks with common benchmarking text datasets in full, few-shot, and zero-shot train-evaluation setups. Recently, it has even been observed that large but frozen pre-trained language models (PLMs) with prompt learning outperform smaller but fine-tuned models. However, as with many recent NLP trends, the performance of even the largest PLMs such as GPT-3 do not perform well on specialized domains (e.g. medical text), and the common practice to achieve State of the Art (SoTA) results still consists of pre-training and fine-tuning the PLMs on downstream tasks. The reliance on fine-tuning large PLMs is problematic in clinical settings where data is often held in non-GPU environments, and more resource efficient methods of training specialized domain models is crucial. We investigated the viability of prompt learning on clinically meaningful decision tasks and directly compared with more traditional fine-tuning methods. Results are partially in line with the prompt learning literature, with prompt learning able to match or improve on traditional fine-tuning with substantially fewer trainable parameters and requiring less training data. We argue that prompt learning therefore provides lower computational resource costs applicable to clinical settings, that can serve as an alternative to fine-tuning ever increasing in size PLMs. Complementary code to reproduce experiments presented in this work can be found at: https://github.com/NtaylorOX/Public_Clinical_Prompt.