 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Pre-trained Language Model Sensitivity via Mask Specific losses: A case study on Biomedical NER
Mar 28, 2024


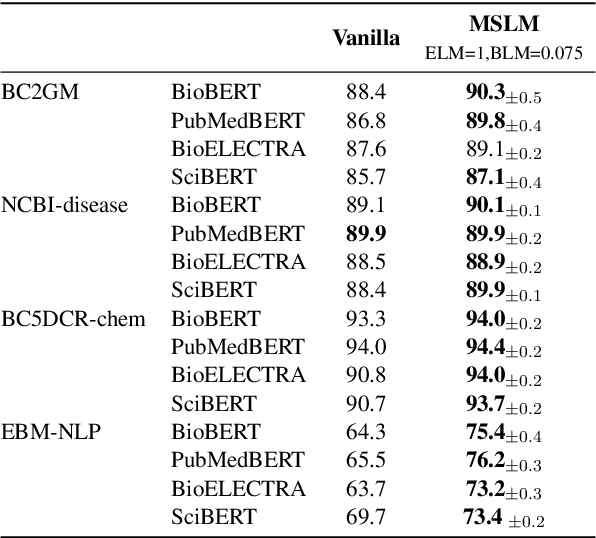
Adapting language models (LMs) to novel domains is often achieved through fine-tuning a pre-trained LM (PLM) on domain-specific data. Fine-tuning introduces new knowledge into an LM, enabling it to comprehend and efficiently perform a target domain task. Fine-tuning can however be inadvertently insensitive if it ignores the wide array of disparities (e.g in word meaning) between source and target domains. For instance, words such as chronic and pressure may be treated lightly in social conversations, however, clinically, these words are usually an expression of concern. To address insensitive fine-tuning, we propose Mask Specific Language Modeling (MSLM), an approach that efficiently acquires target domain knowledge by appropriately weighting the importance of domain-specific terms (DS-terms) during fine-tuning. MSLM jointly masks DS-terms and generic words, then learns mask-specific losses by ensuring LMs incur larger penalties for inaccurately predicting DS-terms compared to generic words. Results of our analysis show that MSLM improves LMs sensitivity and detection of DS-terms. We empirically show that an optimal masking rate not only depends on the LM, but also on the dataset and the length of sequences. Our proposed masking strategy outperforms advanced masking strategies such as span- and PMI-based masking.
Select and Augment: Enhanced Dense Retrieval Knowledge Graph Augmentation
Jul 28, 2023Injecting textual information into knowledge graph (KG) entity representations has been a worthwhile expedition in terms of improving performance in KG oriented tasks within the NLP community. External knowledge often adopted to enhance KG embeddings ranges from semantically rich lexical dependency parsed features to a set of relevant key words to entire text descriptions supplied from an external corpus such as wikipedia and many more. Despite the gains this innovation (Text-enhanced KG embeddings) has made, the proposal in this work suggests that it can be improved even further. Instead of using a single text description (which would not sufficiently represent an entity because of the inherent lexical ambiguity of text), we propose a multi-task framework that jointly selects a set of text descriptions relevant to KG entities as well as align or augment KG embeddings with text descriptions. Different from prior work that plugs formal entity descriptions declared in knowledge bases, this framework leverages a retriever model to selectively identify richer or highly relevant text descriptions to use in augmenting entities. Furthermore, the framework treats the number of descriptions to use in augmentation process as a parameter, which allows the flexibility of enumerating across several numbers before identifying an appropriate number. Experiment results for Link Prediction demonstrate a 5.5% and 3.5% percentage increase in the Mean Reciprocal Rank (MRR) and Hits@10 scores respectively, in comparison to text-enhanced knowledge graph augmentation methods using traditional CNNs.
Assessment of contextualised representations in detecting outcome phrases in clinical trials
Mar 13, 2022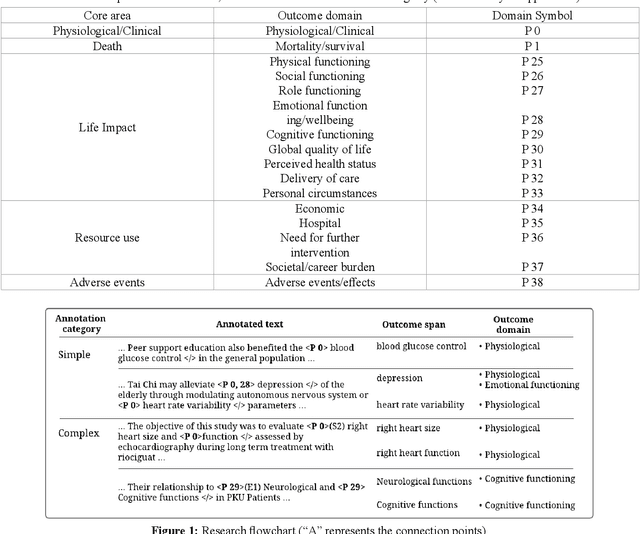

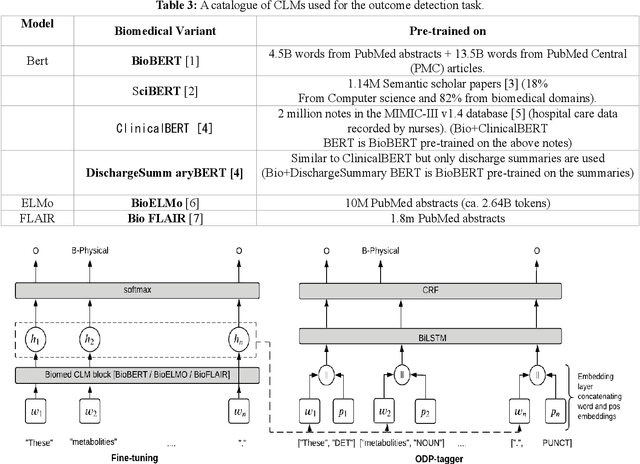
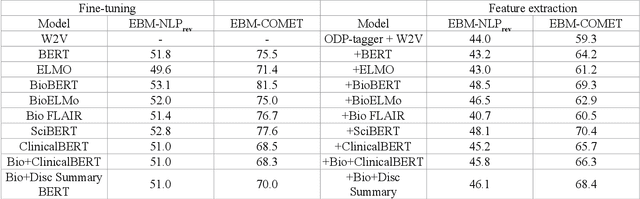
Automating the recognition of outcomes reported in clinical trials using machine learning has a huge potential of speeding up access to evidence necessary in healthcare decision-making. Prior research has however acknowledged inadequate training corpora as a challenge for the Outcome detection (OD) task. Additionally, several contextualized representations like BERT and ELMO have achieved unparalleled success in detecting various diseases, genes, proteins, and chemicals, however, the same cannot be emphatically stated for outcomes, because these models have been relatively under-tested and studied for the OD task. We introduce "EBM-COMET", a dataset in which 300 PubMed abstracts are expertly annotated for clinical outcomes. Unlike prior related datasets that use arbitrary outcome classifications, we use labels from a taxonomy recently published to standardize outcome classifications. To extract outcomes, we fine-tune a variety of pre-trained contextualized representations, additionally, we use frozen contextualized and context-independent representations in our custom neural model augmented with clinically informed Part-Of-Speech embeddings and a cost-sensitive loss function. We adopt strict evaluation for the trained models by rewarding them for correctly identifying full outcome phrases rather than words within the entities i.e. given an outcome "systolic blood pressure", the models are rewarded a classification score only when they predict all 3 words in sequence, otherwise, they are not rewarded. We observe our best model (BioBERT) achieve 81.5\% F1, 81.3\% sensitivity and 98.0\% specificity. We reach a consensus on which contextualized representations are best suited for detecting outcomes from clinical-trial abstracts. Furthermore, our best model outperforms scores published on the original EBM-NLP dataset leader-board scores.