 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnnotating Training Data for Conditional Semantic Textual Similarity Measurement using Large Language Models
Sep 17, 2025


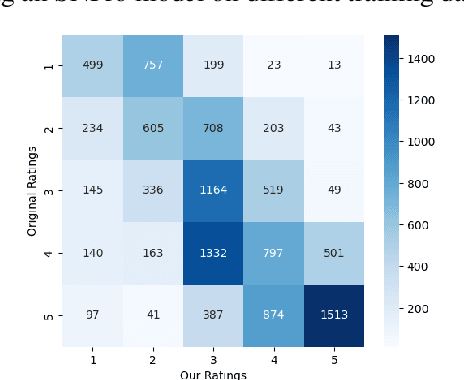
Semantic similarity between two sentences depends on the aspects considered between those sentences. To study this phenomenon, Deshpande et al. (2023) proposed the Conditional Semantic Textual Similarity (C-STS) task and annotated a human-rated similarity dataset containing pairs of sentences compared under two different conditions. However, Tu et al. (2024) found various annotation issues in this dataset and showed that manually re-annotating a small portion of it leads to more accurate C-STS models. Despite these pioneering efforts, the lack of large and accurately annotated C-STS datasets remains a blocker for making progress on this task as evidenced by the subpar performance of the C-STS models. To address this training data need, we resort to Large Language Models (LLMs) to correct the condition statements and similarity ratings in the original dataset proposed by Deshpande et al. (2023). Our proposed method is able to re-annotate a large training dataset for the C-STS task with minimal manual effort. Importantly, by training a supervised C-STS model on our cleaned and re-annotated dataset, we achieve a 5.4% statistically significant improvement in Spearman correlation. The re-annotated dataset is available at https://LivNLP.github.io/CSTS-reannotation.
CASE -- Condition-Aware Sentence Embeddings for Conditional Semantic Textual Similarity Measurement
Mar 21, 2025The meaning conveyed by a sentence often depends on the context in which it appears. Despite the progress of sentence embedding methods, it remains unclear how to best modify a sentence embedding conditioned on its context. To address this problem, we propose Condition-Aware Sentence Embeddings (CASE), an efficient and accurate method to create an embedding for a sentence under a given condition. First, CASE creates an embedding for the condition using a Large Language Model (LLM), where the sentence influences the attention scores computed for the tokens in the condition during pooling. Next, a supervised nonlinear projection is learned to reduce the dimensionality of the LLM-based text embeddings. We show that CASE significantly outperforms previously proposed Conditional Semantic Textual Similarity (C-STS) methods on an existing standard benchmark dataset. We find that subtracting the condition embedding consistently improves the C-STS performance of LLM-based text embeddings. Moreover, we propose a supervised dimensionality reduction method that not only reduces the dimensionality of LLM-based embeddings but also significantly improves their performance.
Evaluating the Effect of Retrieval Augmentation on Social Biases
Feb 24, 2025Retrieval Augmented Generation (RAG) has gained popularity as a method for conveniently incorporating novel facts that were not seen during the pre-training stage in Large Language Model (LLM)-based Natural Language Generation (NLG) systems. However, LLMs are known to encode significant levels of unfair social biases. The modulation of these biases by RAG in NLG systems is not well understood. In this paper, we systematically study the relationship between the different components of a RAG system and the social biases presented in the text generated across three languages (i.e. English, Japanese and Chinese) and four social bias types (i.e. gender, race, age and religion). Specifically, using the Bias Question Answering (BBQ) benchmark datasets, we evaluate the social biases in RAG responses from document collections with varying levels of stereotypical biases, employing multiple LLMs used as generators. We find that the biases in document collections are often amplified in the generated responses, even when the generating LLM exhibits a low-level of bias. Our findings raise concerns about the use of RAG as a technique for injecting novel facts into NLG systems and call for careful evaluation of potential social biases in RAG applications before their real-world deployment.
Improving Unsupervised Constituency Parsing via Maximizing Semantic Information
Oct 03, 2024



Unsupervised constituency parsers organize phrases within a sentence into a tree-shaped syntactic constituent structure that reflects the organization of sentence semantics. However, the traditional objective of maximizing sentence log-likelihood (LL) does not explicitly account for the close relationship between the constituent structure and the semantics, resulting in a weak correlation between LL values and parsing accuracy. In this paper, we introduce a novel objective for training unsupervised parsers: maximizing the information between constituent structures and sentence semantics (SemInfo). We introduce a bag-of-substrings model to represent the semantics and apply the probability-weighted information metric to estimate the SemInfo. Additionally, we develop a Tree Conditional Random Field (TreeCRF)-based model to apply the SemInfo maximization objective to Probabilistic Context-Free Grammar (PCFG) induction, the state-of-the-art method for unsupervised constituency parsing. Experiments demonstrate that SemInfo correlates more strongly with parsing accuracy than LL. Our algorithm significantly enhances parsing accuracy by an average of 7.85 points across five PCFG variants and in four languages, achieving new state-of-the-art results in three of the four languages.
Investigating the Contextualised Word Embedding Dimensions Responsible for Contextual and Temporal Semantic Changes
Jul 03, 2024Words change their meaning over time as well as in different contexts. The sense-aware contextualised word embeddings (SCWEs) such as the ones produced by XL-LEXEME by fine-tuning masked langauge models (MLMs) on Word-in-Context (WiC) data attempt to encode such semantic changes of words within the contextualised word embedding (CWE) spaces. Despite the superior performance of SCWEs in contextual/temporal semantic change detection (SCD) benchmarks, it remains unclear as to how the meaning changes are encoded in the embedding space. To study this, we compare pre-trained CWEs and their fine-tuned versions on contextual and temporal semantic change benchmarks under Principal Component Analysis (PCA) and Independent Component Analysis (ICA) transformations. Our experimental results reveal several novel insights such as (a) although there exist a smaller number of axes that are responsible for semantic changes of words in the pre-trained CWE space, this information gets distributed across all dimensions when fine-tuned, and (b) in contrast to prior work studying the geometry of CWEs, we find that PCA to better represent semantic changes than ICA. Source code is available at https://github.com/LivNLP/svp-dims .
Evaluating Short-Term Temporal Fluctuations of Social Biases in Social Media Data and Masked Language Models
Jun 19, 2024



Social biases such as gender or racial biases have been reported in language models (LMs), including Masked Language Models (MLMs). Given that MLMs are continuously trained with increasing amounts of additional data collected over time, an important yet unanswered question is how the social biases encoded with MLMs vary over time. In particular, the number of social media users continues to grow at an exponential rate, and it is a valid concern for the MLMs trained specifically on social media data whether their social biases (if any) would also amplify over time. To empirically analyse this problem, we use a series of MLMs pretrained on chronologically ordered temporal snapshots of corpora. Our analysis reveals that, although social biases are present in all MLMs, most types of social bias remain relatively stable over time (with a few exceptions). To further understand the mechanisms that influence social biases in MLMs, we analyse the temporal corpora used to train the MLMs. Our findings show that some demographic groups, such as male, obtain higher preference over the other, such as female on the training corpora constantly.
Improving Diversity of Commonsense Generation by Large Language Models via In-Context Learning
Apr 25, 2024



Generative Commonsense Reasoning (GCR) requires a model to reason about a situation using commonsense knowledge, while generating coherent sentences. Although the quality of the generated sentences is crucial, the diversity of the generation is equally important because it reflects the model's ability to use a range of commonsense knowledge facts. Large Language Models (LLMs) have shown proficiency in enhancing the generation quality across various tasks through in-context learning (ICL) using given examples without the need for any fine-tuning. However, the diversity aspect in LLM outputs has not been systematically studied before. To address this, we propose a simple method that diversifies the LLM generations, while preserving their quality. Experimental results on three benchmark GCR datasets show that our method achieves an ideal balance between the quality and diversity. Moreover, the sentences generated by our proposed method can be used as training data to improve diversity in existing commonsense generators.
Constituents Correspond to Word Sequence Patterns among Sentences with Equivalent Predicate-Argument Structures: Unsupervised Constituency Parsing by Span Matching
Apr 18, 2024Unsupervised constituency parsing is about identifying word sequences that form a syntactic unit (i.e., constituents) in a target sentence. Linguists identify the constituent by evaluating a set of Predicate-Argument Structure (PAS) equivalent sentences where we find the constituent corresponds to frequent word sequences. However, such information is unavailable to previous parsing methods which identify the constituent by observing sentences with diverse PAS. In this study, we empirically verify that \textbf{constituents correspond to word sequence patterns in the PAS-equivalent sentence set}. We propose a frequency-based method \emph{span-overlap}, applying the word sequence pattern to computational unsupervised parsing for the first time. Parsing experiments show that the span-overlap parser outperforms state-of-the-art parsers in eight out of ten languages. Further discrimination analysis confirms that the span-overlap method can non-trivially separate constituents from non-constituents. This result highlights the utility of the word sequence pattern. Additionally, we discover a multilingual phenomenon: \textbf{participant-denoting constituents are more frequent than event-denoting constituents}. The phenomenon indicates a behavioral difference between the two constituent types, laying the foundation for future labeled unsupervised parsing.
Improving Pre-trained Language Model Sensitivity via Mask Specific losses: A case study on Biomedical NER
Mar 28, 2024


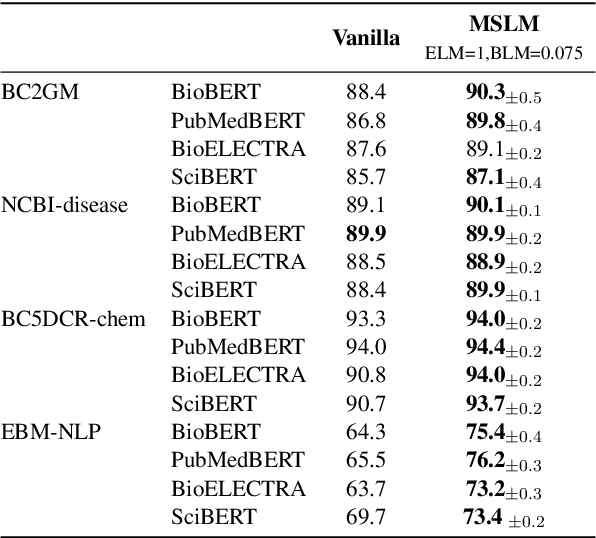
Adapting language models (LMs) to novel domains is often achieved through fine-tuning a pre-trained LM (PLM) on domain-specific data. Fine-tuning introduces new knowledge into an LM, enabling it to comprehend and efficiently perform a target domain task. Fine-tuning can however be inadvertently insensitive if it ignores the wide array of disparities (e.g in word meaning) between source and target domains. For instance, words such as chronic and pressure may be treated lightly in social conversations, however, clinically, these words are usually an expression of concern. To address insensitive fine-tuning, we propose Mask Specific Language Modeling (MSLM), an approach that efficiently acquires target domain knowledge by appropriately weighting the importance of domain-specific terms (DS-terms) during fine-tuning. MSLM jointly masks DS-terms and generic words, then learns mask-specific losses by ensuring LMs incur larger penalties for inaccurately predicting DS-terms compared to generic words. Results of our analysis show that MSLM improves LMs sensitivity and detection of DS-terms. We empirically show that an optimal masking rate not only depends on the LM, but also on the dataset and the length of sequences. Our proposed masking strategy outperforms advanced masking strategies such as span- and PMI-based masking.
Evaluating Unsupervised Dimensionality Reduction Methods for Pretrained Sentence Embeddings
Mar 20, 2024Sentence embeddings produced by Pretrained Language Models (PLMs) have received wide attention from the NLP community due to their superior performance when representing texts in numerous downstream applications. However, the high dimensionality of the sentence embeddings produced by PLMs is problematic when representing large numbers of sentences in memory- or compute-constrained devices. As a solution, we evaluate unsupervised dimensionality reduction methods to reduce the dimensionality of sentence embeddings produced by PLMs. Our experimental results show that simple methods such as Principal Component Analysis (PCA) can reduce the dimensionality of sentence embeddings by almost $50\%$, without incurring a significant loss in performance in multiple downstream tasks. Surprisingly, reducing the dimensionality further improves performance over the original high-dimensional versions for the sentence embeddings produced by some PLMs in some tasks.