 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTracking Temporal Dynamics of Vector Sets with Gaussian Process
Dec 17, 2025Understanding the temporal evolution of sets of vectors is a fundamental challenge across various domains, including ecology, crime analysis, and linguistics. For instance, ecosystem structures evolve due to interactions among plants, herbivores, and carnivores; the spatial distribution of crimes shifts in response to societal changes; and word embedding vectors reflect cultural and semantic trends over time. However, analyzing such time-varying sets of vectors is challenging due to their complicated structures, which also evolve over time. In this work, we propose a novel method for modeling the distribution underlying each set of vectors using infinite-dimensional Gaussian processes. By approximating the latent function in the Gaussian process with Random Fourier Features, we obtain compact and comparable vector representations over time. This enables us to track and visualize temporal transitions of vector sets in a low-dimensional space. We apply our method to both sociological data (crime distributions) and linguistic data (word embeddings), demonstrating its effectiveness in capturing temporal dynamics. Our results show that the proposed approach provides interpretable and robust representations, offering a powerful framework for analyzing structural changes in temporally indexed vector sets across diverse domains.
Analyzing Continuous Semantic Shifts with Diachronic Word Similarity Matrices
Jan 16, 2025



The meanings and relationships of words shift over time. This phenomenon is referred to as semantic shift.Research focused on understanding how semantic shifts occur over multiple time periods is essential for gaining a detailed understanding of semantic shifts.However, detecting change points only between adjacent time periods is insufficient for analyzing detailed semantic shifts, and using BERT-based methods to examine word sense proportions incurs a high computational cost.To address those issues, we propose a simple yet intuitive framework for how semantic shifts occur over multiple time periods by leveraging a similarity matrix between the embeddings of the same word through time.We compute a diachronic word similarity matrix using fast and lightweight word embeddings across arbitrary time periods, making it deeper to analyze continuous semantic shifts.Additionally, by clustering the similarity matrices for different words, we can categorize words that exhibit similar behavior of semantic shift in an unsupervised manner.
Investigating the Contextualised Word Embedding Dimensions Responsible for Contextual and Temporal Semantic Changes
Jul 03, 2024



Words change their meaning over time as well as in different contexts. The sense-aware contextualised word embeddings (SCWEs) such as the ones produced by XL-LEXEME by fine-tuning masked langauge models (MLMs) on Word-in-Context (WiC) data attempt to encode such semantic changes of words within the contextualised word embedding (CWE) spaces. Despite the superior performance of SCWEs in contextual/temporal semantic change detection (SCD) benchmarks, it remains unclear as to how the meaning changes are encoded in the embedding space. To study this, we compare pre-trained CWEs and their fine-tuned versions on contextual and temporal semantic change benchmarks under Principal Component Analysis (PCA) and Independent Component Analysis (ICA) transformations. Our experimental results reveal several novel insights such as (a) although there exist a smaller number of axes that are responsible for semantic changes of words in the pre-trained CWE space, this information gets distributed across all dimensions when fine-tuned, and (b) in contrast to prior work studying the geometry of CWEs, we find that PCA to better represent semantic changes than ICA. Source code is available at https://github.com/LivNLP/svp-dims .
A Semantic Distance Metric Learning approach for Lexical Semantic Change Detection
Mar 01, 2024



Detecting temporal semantic changes of words is an important task for various NLP applications that must make time-sensitive predictions. Lexical Semantic Change Detection (SCD) task considers the problem of predicting whether a given target word, $w$, changes its meaning between two different text corpora, $C_1$ and $C_2$. For this purpose, we propose a supervised two-staged SCD method that uses existing Word-in-Context (WiC) datasets. In the first stage, for a target word $w$, we learn two sense-aware encoder that represents the meaning of $w$ in a given sentence selected from a corpus. Next, in the second stage, we learn a sense-aware distance metric that compares the semantic representations of a target word across all of its occurrences in $C_1$ and $C_2$. Experimental results on multiple benchmark datasets for SCD show that our proposed method consistently outperforms all previously proposed SCD methods for multiple languages, establishing a novel state-of-the-art for SCD. Interestingly, our findings imply that there are specialised dimensions that carry information related to semantic changes of words in the sense-aware embedding space. Source code is available at https://github.com/a1da4/svp-sdml .
$\textit{Swap and Predict}$ -- Predicting the Semantic Changes in Words across Corpora by Context Swapping
Oct 16, 2023



Meanings of words change over time and across domains. Detecting the semantic changes of words is an important task for various NLP applications that must make time-sensitive predictions. We consider the problem of predicting whether a given target word, $w$, changes its meaning between two different text corpora, $\mathcal{C}_1$ and $\mathcal{C}_2$. For this purpose, we propose $\textit{Swapping-based Semantic Change Detection}$ (SSCD), an unsupervised method that randomly swaps contexts between $\mathcal{C}_1$ and $\mathcal{C}_2$ where $w$ occurs. We then look at the distribution of contextualised word embeddings of $w$, obtained from a pretrained masked language model (MLM), representing the meaning of $w$ in its occurrence contexts in $\mathcal{C}_1$ and $\mathcal{C}_2$. Intuitively, if the meaning of $w$ does not change between $\mathcal{C}_1$ and $\mathcal{C}_2$, we would expect the distributions of contextualised word embeddings of $w$ to remain the same before and after this random swapping process. Despite its simplicity, we demonstrate that even by using pretrained MLMs without any fine-tuning, our proposed context swapping method accurately predicts the semantic changes of words in four languages (English, German, Swedish, and Latin) and across different time spans (over 50 years and about five years). Moreover, our method achieves significant performance improvements compared to strong baselines for the English semantic change prediction task. Source code is available at https://github.com/a1da4/svp-swap .
Can Word Sense Distribution Detect Semantic Changes of Words?
Oct 16, 2023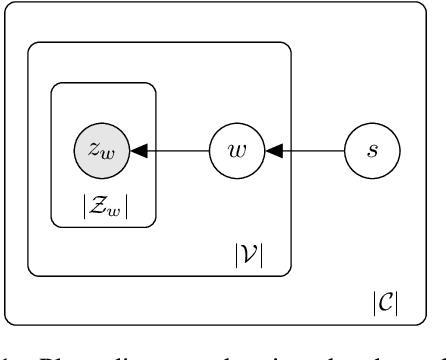
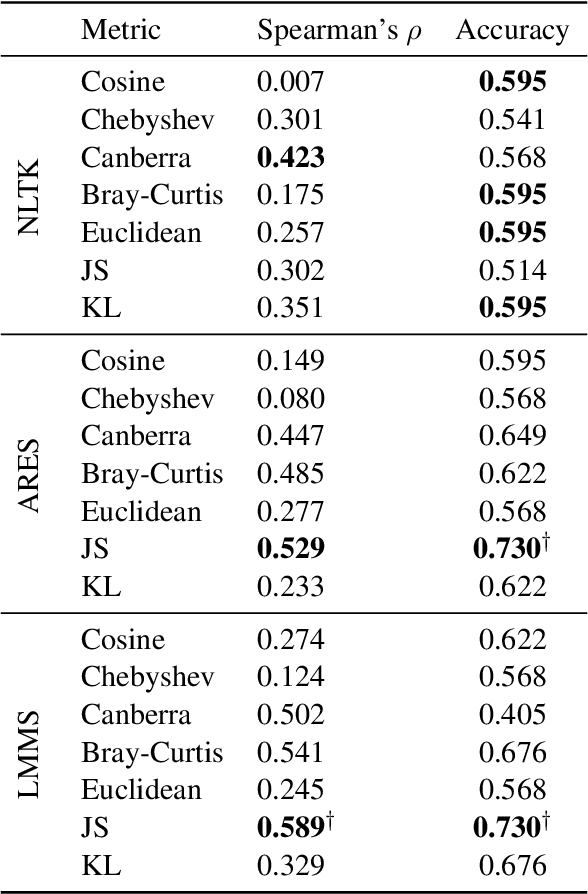
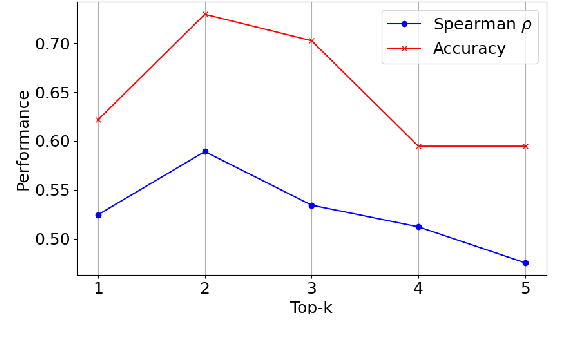
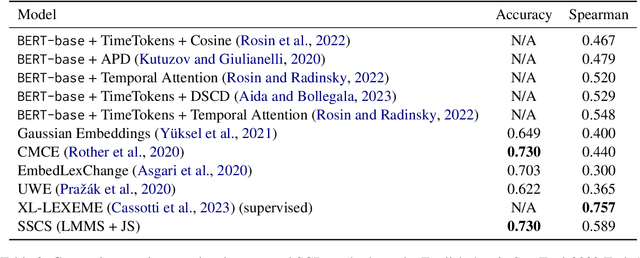
Semantic Change Detection (SCD) of words is an important task for various NLP applications that must make time-sensitive predictions. Some words are used over time in novel ways to express new meanings, and these new meanings establish themselves as novel senses of existing words. On the other hand, Word Sense Disambiguation (WSD) methods associate ambiguous words with sense ids, depending on the context in which they occur. Given this relationship between WSD and SCD, we explore the possibility of predicting whether a target word has its meaning changed between two corpora collected at different time steps, by comparing the distributions of senses of that word in each corpora. For this purpose, we use pretrained static sense embeddings to automatically annotate each occurrence of the target word in a corpus with a sense id. Next, we compute the distribution of sense ids of a target word in a given corpus. Finally, we use different divergence or distance measures to quantify the semantic change of the target word across the two given corpora. Our experimental results on SemEval 2020 Task 1 dataset show that word sense distributions can be accurately used to predict semantic changes of words in English, German, Swedish and Latin.
* Accepted to Findings of EMNLP 2023
Unsupervised Semantic Variation Prediction using the Distribution of Sibling Embeddings
May 15, 2023



Languages are dynamic entities, where the meanings associated with words constantly change with time. Detecting the semantic variation of words is an important task for various NLP applications that must make time-sensitive predictions. Existing work on semantic variation prediction have predominantly focused on comparing some form of an averaged contextualised representation of a target word computed from a given corpus. However, some of the previously associated meanings of a target word can become obsolete over time (e.g. meaning of gay as happy), while novel usages of existing words are observed (e.g. meaning of cell as a mobile phone). We argue that mean representations alone cannot accurately capture such semantic variations and propose a method that uses the entire cohort of the contextualised embeddings of the target word, which we refer to as the sibling distribution. Experimental results on SemEval-2020 Task 1 benchmark dataset for semantic variation prediction show that our method outperforms prior work that consider only the mean embeddings, and is comparable to the current state-of-the-art. Moreover, a qualitative analysis shows that our method detects important semantic changes in words that are not captured by the existing methods. Source code is available at https://github.com/a1da4/svp-gauss .
Construction of a Quality Estimation Dataset for Automatic Evaluation of Japanese Grammatical Error Correction
Jan 20, 2022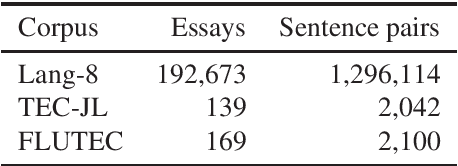
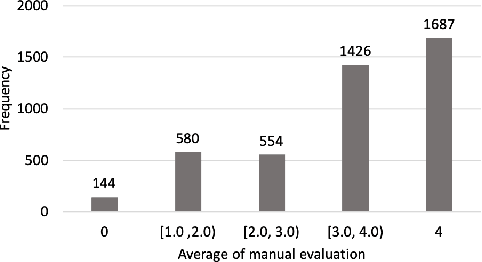


In grammatical error correction (GEC), automatic evaluation is an important factor for research and development of GEC systems. Previous studies on automatic evaluation have demonstrated that quality estimation models built from datasets with manual evaluation can achieve high performance in automatic evaluation of English GEC without using reference sentences.. However, quality estimation models have not yet been studied in Japanese, because there are no datasets for constructing quality estimation models. Therefore, in this study, we created a quality estimation dataset with manual evaluation to build an automatic evaluation model for Japanese GEC. Moreover, we conducted a meta-evaluation to verify the dataset's usefulness in building the Japanese quality estimation model.