 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConstruction of a Quality Estimation Dataset for Automatic Evaluation of Japanese Grammatical Error Correction
Jan 20, 2022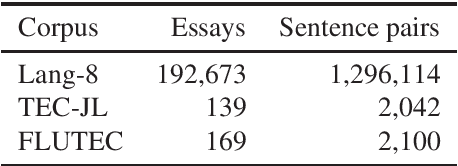
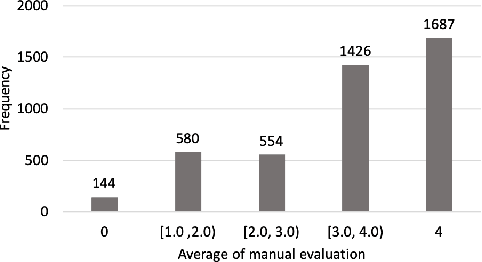


In grammatical error correction (GEC), automatic evaluation is an important factor for research and development of GEC systems. Previous studies on automatic evaluation have demonstrated that quality estimation models built from datasets with manual evaluation can achieve high performance in automatic evaluation of English GEC without using reference sentences.. However, quality estimation models have not yet been studied in Japanese, because there are no datasets for constructing quality estimation models. Therefore, in this study, we created a quality estimation dataset with manual evaluation to build an automatic evaluation model for Japanese GEC. Moreover, we conducted a meta-evaluation to verify the dataset's usefulness in building the Japanese quality estimation model.
Proficiency Matters Quality Estimation in Grammatical Error Correction
Jan 17, 2022



This study investigates how supervised quality estimation (QE) models of grammatical error correction (GEC) are affected by the learners' proficiency with the data. QE models for GEC evaluations in prior work have obtained a high correlation with manual evaluations. However, when functioning in a real-world context, the data used for the reported results have limitations because prior works were biased toward data by learners with relatively high proficiency levels. To address this issue, we created a QE dataset that includes multiple proficiency levels and explored the necessity of performing proficiency-wise evaluation for QE of GEC. Our experiments demonstrated that differences in evaluation dataset proficiency affect the performance of QE models, and proficiency-wise evaluation helps create more robust models.