 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnnotating Training Data for Conditional Semantic Textual Similarity Measurement using Large Language Models
Sep 17, 2025


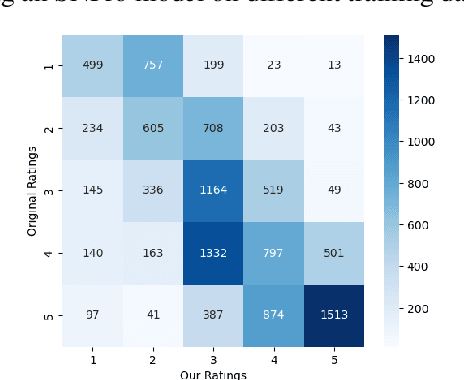
Semantic similarity between two sentences depends on the aspects considered between those sentences. To study this phenomenon, Deshpande et al. (2023) proposed the Conditional Semantic Textual Similarity (C-STS) task and annotated a human-rated similarity dataset containing pairs of sentences compared under two different conditions. However, Tu et al. (2024) found various annotation issues in this dataset and showed that manually re-annotating a small portion of it leads to more accurate C-STS models. Despite these pioneering efforts, the lack of large and accurately annotated C-STS datasets remains a blocker for making progress on this task as evidenced by the subpar performance of the C-STS models. To address this training data need, we resort to Large Language Models (LLMs) to correct the condition statements and similarity ratings in the original dataset proposed by Deshpande et al. (2023). Our proposed method is able to re-annotate a large training dataset for the C-STS task with minimal manual effort. Importantly, by training a supervised C-STS model on our cleaned and re-annotated dataset, we achieve a 5.4% statistically significant improvement in Spearman correlation. The re-annotated dataset is available at https://LivNLP.github.io/CSTS-reannotation.
CASE -- Condition-Aware Sentence Embeddings for Conditional Semantic Textual Similarity Measurement
Mar 21, 2025The meaning conveyed by a sentence often depends on the context in which it appears. Despite the progress of sentence embedding methods, it remains unclear how to best modify a sentence embedding conditioned on its context. To address this problem, we propose Condition-Aware Sentence Embeddings (CASE), an efficient and accurate method to create an embedding for a sentence under a given condition. First, CASE creates an embedding for the condition using a Large Language Model (LLM), where the sentence influences the attention scores computed for the tokens in the condition during pooling. Next, a supervised nonlinear projection is learned to reduce the dimensionality of the LLM-based text embeddings. We show that CASE significantly outperforms previously proposed Conditional Semantic Textual Similarity (C-STS) methods on an existing standard benchmark dataset. We find that subtracting the condition embedding consistently improves the C-STS performance of LLM-based text embeddings. Moreover, we propose a supervised dimensionality reduction method that not only reduces the dimensionality of LLM-based embeddings but also significantly improves their performance.
Evaluating Unsupervised Dimensionality Reduction Methods for Pretrained Sentence Embeddings
Mar 20, 2024Sentence embeddings produced by Pretrained Language Models (PLMs) have received wide attention from the NLP community due to their superior performance when representing texts in numerous downstream applications. However, the high dimensionality of the sentence embeddings produced by PLMs is problematic when representing large numbers of sentences in memory- or compute-constrained devices. As a solution, we evaluate unsupervised dimensionality reduction methods to reduce the dimensionality of sentence embeddings produced by PLMs. Our experimental results show that simple methods such as Principal Component Analysis (PCA) can reduce the dimensionality of sentence embeddings by almost $50\%$, without incurring a significant loss in performance in multiple downstream tasks. Surprisingly, reducing the dimensionality further improves performance over the original high-dimensional versions for the sentence embeddings produced by some PLMs in some tasks.