 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBespoke Large Language Models for Digital Triage Assistance in Mental Health Care
Mar 28, 2024Contemporary large language models (LLMs) may have utility for processing unstructured, narrative free-text clinical data contained in electronic health records (EHRs) -- a particularly important use-case for mental health where a majority of routinely-collected patient data lacks structured, machine-readable content. A significant problem for the the United Kingdom's National Health Service (NHS) are the long waiting lists for specialist mental healthcare. According to NHS data, in each month of 2023, there were between 370,000 and 470,000 individual new referrals into secondary mental healthcare services. Referrals must be triaged by clinicians, using clinical information contained in the patient's EHR to arrive at a decision about the most appropriate mental healthcare team to assess and potentially treat these patients. The ability to efficiently recommend a relevant team by ingesting potentially voluminous clinical notes could help services both reduce referral waiting times and with the right technology, improve the evidence available to justify triage decisions. We present and evaluate three different approaches for LLM-based, end-to-end ingestion of variable-length clinical EHR data to assist clinicians when triaging referrals. Our model is able to deliver triage recommendations consistent with existing clinical practices and it's architecture was implemented on a single GPU, making it practical for implementation in resource-limited NHS environments where private implementations of LLM technology will be necessary to ensure confidential clinical data is appropriately controlled and governed.
Developing Healthcare Language Model Embedding Spaces
Mar 28, 2024Pre-trained Large Language Models (LLMs) often struggle on out-of-domain datasets like healthcare focused text. We explore specialized pre-training to adapt smaller LLMs to different healthcare datasets. Three methods are assessed: traditional masked language modeling, Deep Contrastive Learning for Unsupervised Textual Representations (DeCLUTR), and a novel pre-training objective utilizing metadata categories from the healthcare settings. These schemes are evaluated on downstream document classification tasks for each dataset, with additional analysis of the resultant embedding spaces. Contrastively trained models outperform other approaches on the classification tasks, delivering strong performance from limited labeled data and with fewer model parameter updates required. While metadata-based pre-training does not further improve classifications across the datasets, it yields interesting embedding cluster separability. All domain adapted LLMs outperform their publicly available general base LLM, validating the importance of domain-specialization. This research illustrates efficient approaches to instill healthcare competency in compact LLMs even under tight computational budgets, an essential capability for responsible and sustainable deployment in local healthcare settings. We provide pre-training guidelines for specialized healthcare LLMs, motivate continued inquiry into contrastive objectives, and demonstrates adaptation techniques to align small LLMs with privacy-sensitive medical tasks.
Rationale production to support clinical decision-making
Nov 15, 2021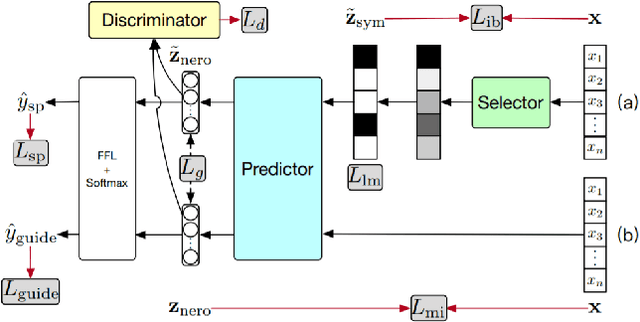
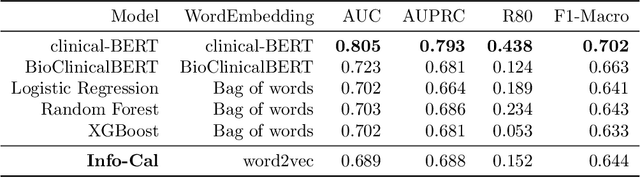

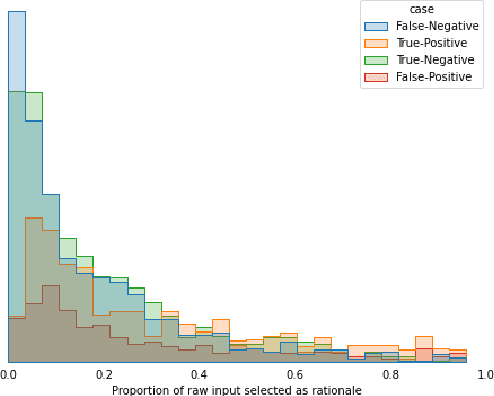
The development of neural networks for clinical artificial intelligence (AI) is reliant on interpretability, transparency, and performance. The need to delve into the black-box neural network and derive interpretable explanations of model output is paramount. A task of high clinical importance is predicting the likelihood of a patient being readmitted to hospital in the near future to enable efficient triage. With the increasing adoption of electronic health records (EHRs), there is great interest in applications of natural language processing (NLP) to clinical free-text contained within EHRs. In this work, we apply InfoCal, the current state-of-the-art model that produces extractive rationales for its predictions, to the task of predicting hospital readmission using hospital discharge notes. We compare extractive rationales produced by InfoCal to competitive transformer-based models pretrained on clinical text data and for which the attention mechanism can be used for interpretation. We find each presented model with selected interpretability or feature importance methods yield varying results, with clinical language domain expertise and pretraining critical to performance and subsequent interpretability.