 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models Perform on Par with Experts Identifying Mental Health Factors in Adolescent Online Forums
Apr 26, 2024



Mental health in children and adolescents has been steadily deteriorating over the past few years. The recent advent of Large Language Models (LLMs) offers much hope for cost and time efficient scaling of monitoring and intervention, yet despite specifically prevalent issues such as school bullying and eating disorders, previous studies on have not investigated performance in this domain or for open information extraction where the set of answers is not predetermined. We create a new dataset of Reddit posts from adolescents aged 12-19 annotated by expert psychiatrists for the following categories: TRAUMA, PRECARITY, CONDITION, SYMPTOMS, SUICIDALITY and TREATMENT and compare expert labels to annotations from two top performing LLMs (GPT3.5 and GPT4). In addition, we create two synthetic datasets to assess whether LLMs perform better when annotating data as they generate it. We find GPT4 to be on par with human inter-annotator agreement and performance on synthetic data to be substantially higher, however we find the model still occasionally errs on issues of negation and factuality and higher performance on synthetic data is driven by greater complexity of real data rather than inherent advantage.
Bespoke Large Language Models for Digital Triage Assistance in Mental Health Care
Mar 28, 2024Contemporary large language models (LLMs) may have utility for processing unstructured, narrative free-text clinical data contained in electronic health records (EHRs) -- a particularly important use-case for mental health where a majority of routinely-collected patient data lacks structured, machine-readable content. A significant problem for the the United Kingdom's National Health Service (NHS) are the long waiting lists for specialist mental healthcare. According to NHS data, in each month of 2023, there were between 370,000 and 470,000 individual new referrals into secondary mental healthcare services. Referrals must be triaged by clinicians, using clinical information contained in the patient's EHR to arrive at a decision about the most appropriate mental healthcare team to assess and potentially treat these patients. The ability to efficiently recommend a relevant team by ingesting potentially voluminous clinical notes could help services both reduce referral waiting times and with the right technology, improve the evidence available to justify triage decisions. We present and evaluate three different approaches for LLM-based, end-to-end ingestion of variable-length clinical EHR data to assist clinicians when triaging referrals. Our model is able to deliver triage recommendations consistent with existing clinical practices and it's architecture was implemented on a single GPU, making it practical for implementation in resource-limited NHS environments where private implementations of LLM technology will be necessary to ensure confidential clinical data is appropriately controlled and governed.
STEntConv: Predicting Disagreement with Stance Detection and a Signed Graph Convolutional Network
Mar 26, 2024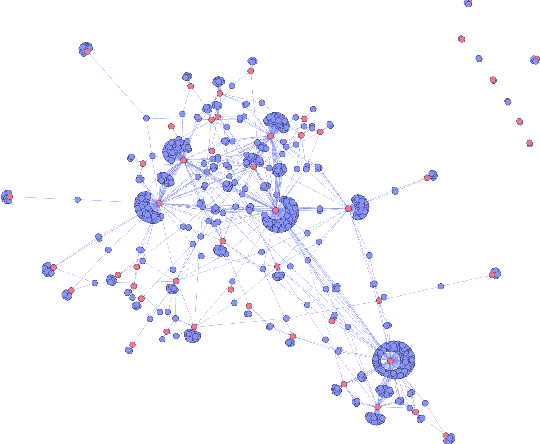
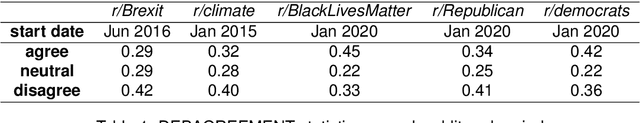

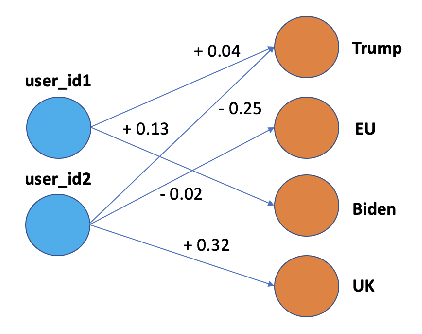
The rise of social media platforms has led to an increase in polarised online discussions, especially on political and socio-cultural topics such as elections and climate change. We propose a simple and novel unsupervised method to predict whether the authors of two posts agree or disagree, leveraging user stances about named entities obtained from their posts. We present STEntConv, a model which builds a graph of users and named entities weighted by stance and trains a Signed Graph Convolutional Network (SGCN) to detect disagreement between comment and reply posts. We run experiments and ablation studies and show that including this information improves disagreement detection performance on a dataset of Reddit posts for a range of controversial subreddit topics, without the need for platform-specific features or user history.
Detecting the Clinical Features of Difficult-to-Treat Depression using Synthetic Data from Large Language Models
Feb 12, 2024



Difficult-to-treat depression (DTD) has been proposed as a broader and more clinically comprehensive perspective on a person's depressive disorder where despite treatment, they continue to experience significant burden. We sought to develop a Large Language Model (LLM)-based tool capable of interrogating routinely-collected, narrative (free-text) electronic health record (EHR) data to locate published prognostic factors that capture the clinical syndrome of DTD. In this work, we use LLM-generated synthetic data (GPT3.5) and a Non-Maximum Suppression (NMS) algorithm to train a BERT-based span extraction model. The resulting model is then able to extract and label spans related to a variety of relevant positive and negative factors in real clinical data (i.e. spans of text that increase or decrease the likelihood of a patient matching the DTD syndrome). We show it is possible to obtain good overall performance (0.70 F1 across polarity) on real clinical data on a set of as many as 20 different factors, and high performance (0.85 F1 with 0.95 precision) on a subset of important DTD factors such as history of abuse, family history of affective disorder, illness severity and suicidality by training the model exclusively on synthetic data. Our results show promise for future healthcare applications especially in applications where traditionally, highly confidential medical data and human-expert annotation would normally be required.
Not wacky vs. definitely wacky: A study of scalar adverbs in pretrained language models
May 25, 2023



Vector space models of word meaning all share the assumption that words occurring in similar contexts have similar meanings. In such models, words that are similar in their topical associations but differ in their logical force tend to emerge as semantically close, creating well-known challenges for NLP applications that involve logical reasoning. Modern pretrained language models, such as BERT, RoBERTa and GPT-3 hold the promise of performing better on logical tasks than classic static word embeddings. However, reports are mixed about their success. In the current paper, we advance this discussion through a systematic study of scalar adverbs, an under-explored class of words with strong logical force. Using three different tasks, involving both naturalistic social media data and constructed examples, we investigate the extent to which BERT, RoBERTa, GPT-2 and GPT-3 exhibit general, human-like, knowledge of these common words. We ask: 1) Do the models distinguish amongst the three semantic categories of MODALITY, FREQUENCY and DEGREE? 2) Do they have implicit representations of full scales from maximally negative to maximally positive? 3) How do word frequency and contextual factors impact model performance? We find that despite capturing some aspects of logical meaning, the models fall far short of human performance.