 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDerivational Morphology Reveals Analogical Generalization in Large Language Models
Nov 12, 2024



What mechanisms underlie linguistic generalization in large language models (LLMs)? This question has attracted considerable attention, with most studies analyzing the extent to which the language skills of LLMs resemble rules. As of yet, it is not known whether linguistic generalization in LLMs could equally well be explained as the result of analogical processes, which can be formalized as similarity operations on stored exemplars. A key shortcoming of prior research is its focus on linguistic phenomena with a high degree of regularity, for which rule-based and analogical approaches make the same predictions. Here, we instead examine derivational morphology, specifically English adjective nominalization, which displays notable variability. We introduce a new method for investigating linguistic generalization in LLMs: focusing on GPT-J, we fit cognitive models that instantiate rule-based and analogical learning to the LLM training data and compare their predictions on a set of nonce adjectives with those of the LLM, allowing us to draw direct conclusions regarding underlying mechanisms. As expected, rule-based and analogical models explain the predictions of GPT-J equally well for adjectives with regular nominalization patterns. However, for adjectives with variable nominalization patterns, the analogical model provides a much better match. Furthermore, GPT-J's behavior is sensitive to the individual word frequencies, even for regular forms, a behavior that is consistent with an analogical account of regular forms but not a rule-based one. These findings refute the hypothesis that GPT-J's linguistic generalization on adjective nominalization involves rules, suggesting similarity operations on stored exemplars as the underlying mechanism. Overall, our study suggests that analogical processes play a bigger role in the linguistic generalization of LLMs than previously thought.
Not wacky vs. definitely wacky: A study of scalar adverbs in pretrained language models
May 25, 2023



Vector space models of word meaning all share the assumption that words occurring in similar contexts have similar meanings. In such models, words that are similar in their topical associations but differ in their logical force tend to emerge as semantically close, creating well-known challenges for NLP applications that involve logical reasoning. Modern pretrained language models, such as BERT, RoBERTa and GPT-3 hold the promise of performing better on logical tasks than classic static word embeddings. However, reports are mixed about their success. In the current paper, we advance this discussion through a systematic study of scalar adverbs, an under-explored class of words with strong logical force. Using three different tasks, involving both naturalistic social media data and constructed examples, we investigate the extent to which BERT, RoBERTa, GPT-2 and GPT-3 exhibit general, human-like, knowledge of these common words. We ask: 1) Do the models distinguish amongst the three semantic categories of MODALITY, FREQUENCY and DEGREE? 2) Do they have implicit representations of full scales from maximally negative to maximally positive? 3) How do word frequency and contextual factors impact model performance? We find that despite capturing some aspects of logical meaning, the models fall far short of human performance.
HateCheck: Functional Tests for Hate Speech Detection Models
Dec 31, 2020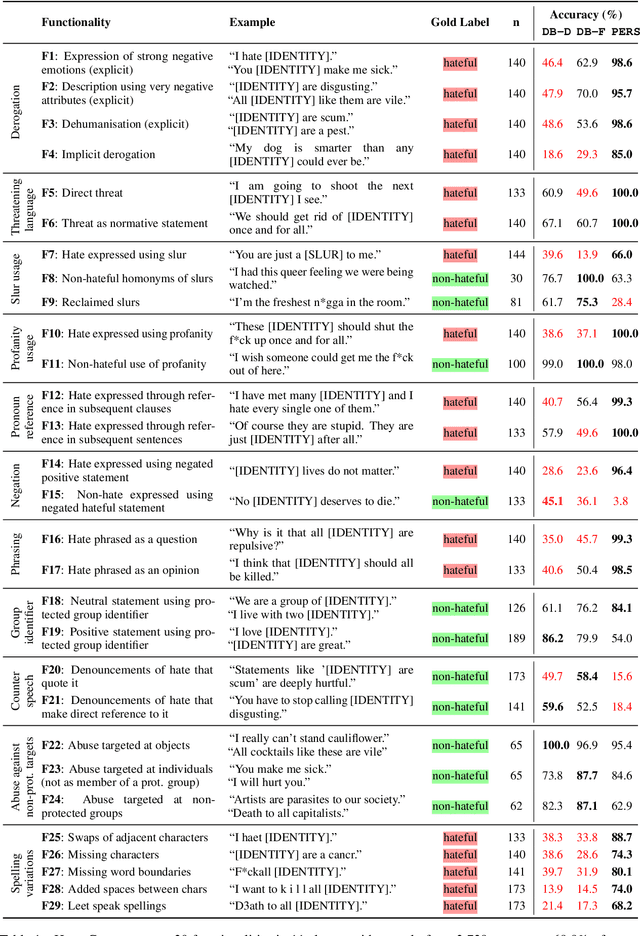
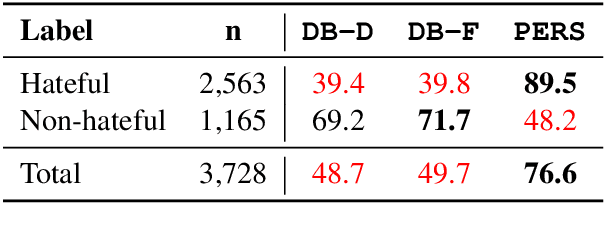
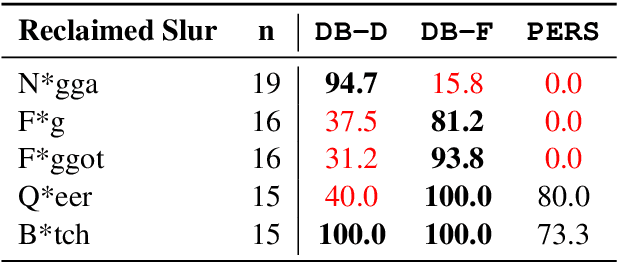
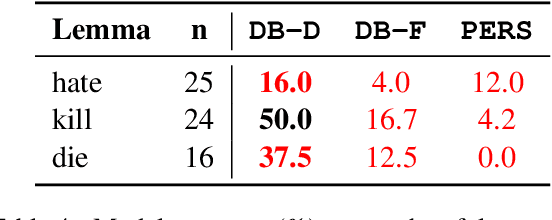
Detecting online hate is a difficult task that even state-of-the-art models struggle with. In previous research, hate speech detection models are typically evaluated by measuring their performance on held-out test data using metrics such as accuracy and F1 score. However, this approach makes it difficult to identify specific model weak points. It also risks overestimating generalisable model quality due to increasingly well-evidenced systematic gaps and biases in hate speech datasets. To enable more targeted diagnostic insights, we introduce HateCheck, a first suite of functional tests for hate speech detection models. We specify 29 model functionalities, the selection of which we motivate by reviewing previous research and through a series of interviews with civil society stakeholders. We craft test cases for each functionality and validate data quality through a structured annotation process. To illustrate HateCheck's utility, we test near-state-of-the-art transformer detection models as well as a popular commercial model, revealing critical model weaknesses.
Stochastic phonological grammars and acceptability
Jul 28, 1997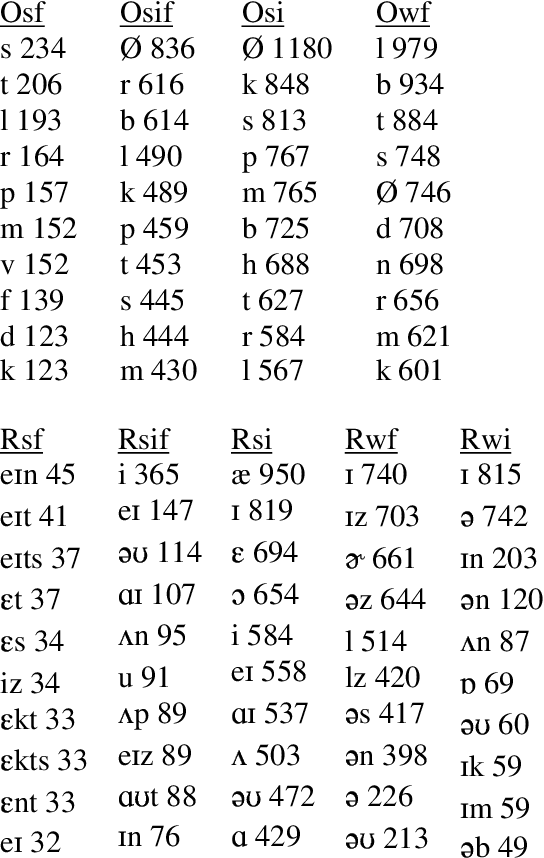
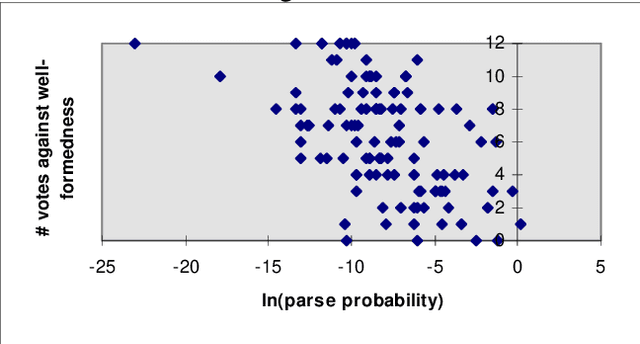
In foundational works of generative phonology it is claimed that subjects can reliably discriminate between possible but non-occurring words and words that could not be English. In this paper we examine the use of a probabilistic phonological parser for words to model experimentally-obtained judgements of the acceptability of a set of nonsense words. We compared various methods of scoring the goodness of the parse as a predictor of acceptability. We found that the probability of the worst part is not the best score of acceptability, indicating that classical generative phonology and Optimality Theory miss an important fact, as these approaches do not recognise a mechanism by which the frequency of well-formed parts may ameliorate the unacceptability of low-frequency parts. We argue that probabilistic generative grammars are demonstrably a more psychologically realistic model of phonological competence than standard generative phonology or Optimality Theory.