 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePBEBench: A Multi-Step Programming by Examples Reasoning Benchmark inspired by Historical Linguistics
May 29, 2025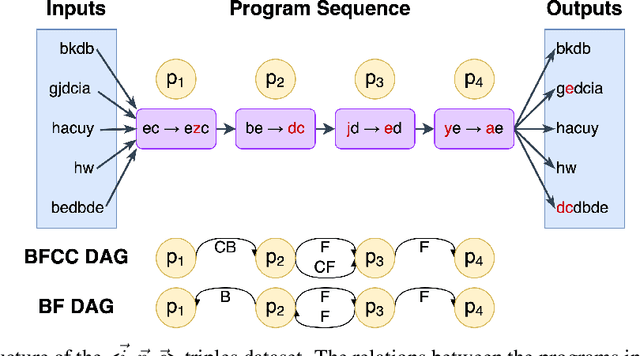
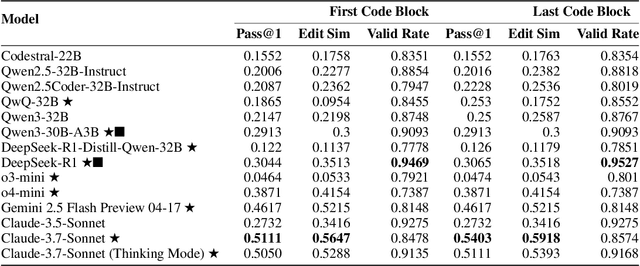
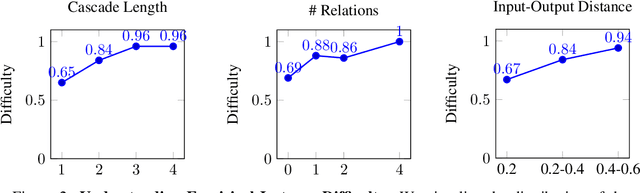
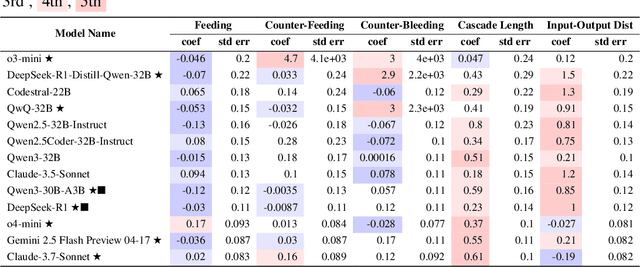
Recently, long chain of thought (LCoT), Large Language Models (LLMs), have taken the machine learning world by storm with their breathtaking reasoning capabilities. However, are the abstract reasoning abilities of these models general enough for problems of practical importance? Unlike past work, which has focused mainly on math, coding, and data wrangling, we focus on a historical linguistics-inspired inductive reasoning problem, formulated as Programming by Examples. We develop a fully automated pipeline for dynamically generating a benchmark for this task with controllable difficulty in order to tackle scalability and contamination issues to which many reasoning benchmarks are subject. Using our pipeline, we generate a test set with nearly 1k instances that is challenging for all state-of-the-art reasoning LLMs, with the best model (Claude-3.7-Sonnet) achieving a mere 54% pass rate, demonstrating that LCoT LLMs still struggle with a class or reasoning that is ubiquitous in historical linguistics as well as many other domains.
Leveraging Allophony in Self-Supervised Speech Models for Atypical Pronunciation Assessment
Feb 10, 2025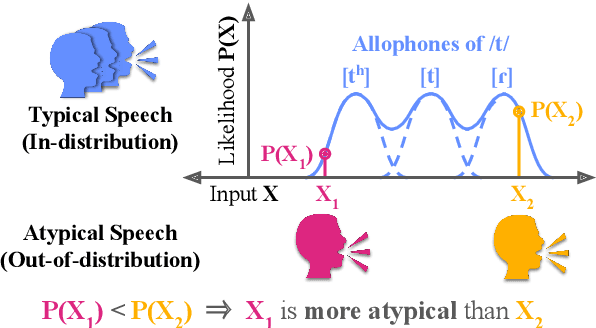
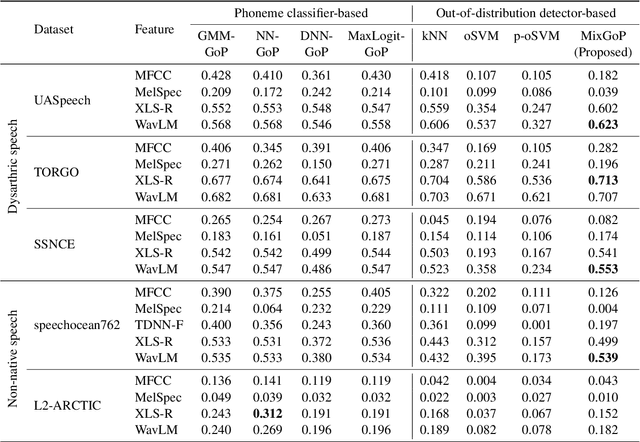
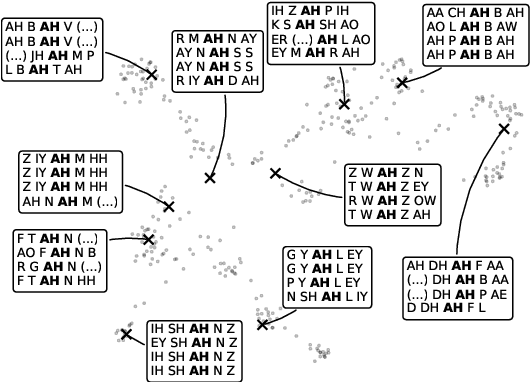
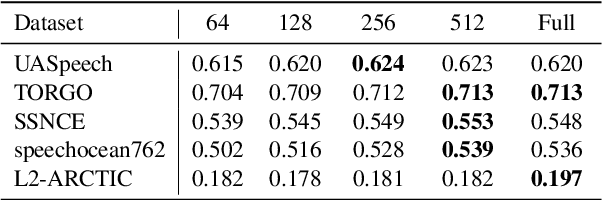
Allophony refers to the variation in the phonetic realization of a phoneme based on its phonetic environment. Modeling allophones is crucial for atypical pronunciation assessment, which involves distinguishing atypical from typical pronunciations. However, recent phoneme classifier-based approaches often simplify this by treating various realizations as a single phoneme, bypassing the complexity of modeling allophonic variation. Motivated by the acoustic modeling capabilities of frozen self-supervised speech model (S3M) features, we propose MixGoP, a novel approach that leverages Gaussian mixture models to model phoneme distributions with multiple subclusters. Our experiments show that MixGoP achieves state-of-the-art performance across four out of five datasets, including dysarthric and non-native speech. Our analysis further suggests that S3M features capture allophonic variation more effectively than MFCCs and Mel spectrograms, highlighting the benefits of integrating MixGoP with S3M features.
Derivational Morphology Reveals Analogical Generalization in Large Language Models
Nov 12, 2024



What mechanisms underlie linguistic generalization in large language models (LLMs)? This question has attracted considerable attention, with most studies analyzing the extent to which the language skills of LLMs resemble rules. As of yet, it is not known whether linguistic generalization in LLMs could equally well be explained as the result of analogical processes, which can be formalized as similarity operations on stored exemplars. A key shortcoming of prior research is its focus on linguistic phenomena with a high degree of regularity, for which rule-based and analogical approaches make the same predictions. Here, we instead examine derivational morphology, specifically English adjective nominalization, which displays notable variability. We introduce a new method for investigating linguistic generalization in LLMs: focusing on GPT-J, we fit cognitive models that instantiate rule-based and analogical learning to the LLM training data and compare their predictions on a set of nonce adjectives with those of the LLM, allowing us to draw direct conclusions regarding underlying mechanisms. As expected, rule-based and analogical models explain the predictions of GPT-J equally well for adjectives with regular nominalization patterns. However, for adjectives with variable nominalization patterns, the analogical model provides a much better match. Furthermore, GPT-J's behavior is sensitive to the individual word frequencies, even for regular forms, a behavior that is consistent with an analogical account of regular forms but not a rule-based one. These findings refute the hypothesis that GPT-J's linguistic generalization on adjective nominalization involves rules, suggesting similarity operations on stored exemplars as the underlying mechanism. Overall, our study suggests that analogical processes play a bigger role in the linguistic generalization of LLMs than previously thought.
ELCC: the Emergent Language Corpus Collection
Jul 04, 2024We introduce the Emergent Language Corpus Collection (ELCC): a collection of corpora collected from open source implementations of emergent communication systems across the literature. These systems include a variety of signalling game environments as well as more complex tasks like a social deduction game and embodied navigation. Each corpus is annotated with metadata describing the characteristics of the source system as well as a suite of analyses of the corpus (e.g., size, entropy, average message length). Currently, research studying emergent languages requires directly running different systems which takes time away from actual analyses of such languages, limits the variety of languages that are studied, and presents a barrier to entry for researchers without a background in deep learning. The availability of a substantial collection of well-documented emergent language corpora, then, will enable new directions of research which focus their purview on the properties of emergent languages themselves rather than on experimental apparatus.
A Review of the Applications of Deep Learning-Based Emergent Communication
Jul 03, 2024Emergent communication, or emergent language, is the field of research which studies how human language-like communication systems emerge de novo in deep multi-agent reinforcement learning environments. The possibilities of replicating the emergence of a complex behavior like language have strong intuitive appeal, yet it is necessary to complement this with clear notions of how such research can be applicable to other fields of science, technology, and engineering. This paper comprehensively reviews the applications of emergent communication research across machine learning, natural language processing, linguistics, and cognitive science. Each application is illustrated with a description of its scope, an explication of emergent communication's unique role in addressing it, a summary of the extant literature working towards the application, and brief recommendations for near-term research directions.
* 49 pages, 15 figures
XferBench: a Data-Driven Benchmark for Emergent Language
Jul 03, 2024In this paper, we introduce a benchmark for evaluating the overall quality of emergent languages using data-driven methods. Specifically, we interpret the notion of the "quality" of an emergent language as its similarity to human language within a deep learning framework. We measure this by using the emergent language as pretraining data for a downstream NLP tasks in human language -- the better the downstream performance, the better the emergent language. We implement this benchmark as an easy-to-use Python package that only requires a text file of utterances from the emergent language to be evaluated. Finally, we empirically test the benchmark's validity using human, synthetic, and emergent language baselines.
* 15 pages, 5 figures
Can Large Language Models Code Like a Linguist?: A Case Study in Low Resource Sound Law Induction
Jun 18, 2024



Historical linguists have long written a kind of incompletely formalized ''program'' that converts reconstructed words in an ancestor language into words in one of its attested descendants that consist of a series of ordered string rewrite functions (called sound laws). They do this by observing pairs of words in the reconstructed language (protoforms) and the descendent language (reflexes) and constructing a program that transforms protoforms into reflexes. However, writing these programs is error-prone and time-consuming. Prior work has successfully scaffolded this process computationally, but fewer researchers have tackled Sound Law Induction (SLI), which we approach in this paper by casting it as Programming by Examples. We propose a language-agnostic solution that utilizes the programming ability of Large Language Models (LLMs) by generating Python sound law programs from sound change examples. We evaluate the effectiveness of our approach for various LLMs, propose effective methods to generate additional language-agnostic synthetic data to fine-tune LLMs for SLI, and compare our method with existing automated SLI methods showing that while LLMs lag behind them they can complement some of their weaknesses.
Transformed Protoform Reconstruction
Jul 06, 2023



Protoform reconstruction is the task of inferring what morphemes or words appeared like in the ancestral languages of a set of daughter languages. Meloni et al. (2021) achieved the state-of-the-art on Latin protoform reconstruction with an RNN-based encoder-decoder with attention model. We update their model with the state-of-the-art seq2seq model: the Transformer. Our model outperforms their model on a suite of different metrics on two different datasets: their Romance data of 8,000 cognates spanning 5 languages and a Chinese dataset (Hou 2004) of 800+ cognates spanning 39 varieties. We also probe our model for potential phylogenetic signal contained in the model. Our code is publicly available at https://github.com/cmu-llab/acl-2023.
PWESuite: Phonetic Word Embeddings and Tasks They Facilitate
Apr 05, 2023



Word embeddings that map words into a fixed-dimensional vector space are the backbone of modern NLP. Most word embedding methods encode semantic information. However, phonetic information, which is important for some tasks, is often overlooked. In this work, we develop several novel methods which leverage articulatory features to build phonetically informed word embeddings, and present a set of phonetic word embeddings to encourage their community development, evaluation and use. While several methods for learning phonetic word embeddings already exist, there is a lack of consistency in evaluating their effectiveness. Thus, we also proposes several ways to evaluate both intrinsic aspects of phonetic word embeddings, such as word retrieval and correlation with sound similarity, and extrinsic performances, such as rhyme and cognate detection and sound analogies. We hope that our suite of tasks will promote reproducibility and provide direction for future research on phonetic word embeddings.
Mathematically Modeling the Lexicon Entropy of Emergent Language
Nov 28, 2022



We formulate a stochastic process, FiLex, as a mathematical model of lexicon entropy in deep learning-based emergent language systems. Defining a model mathematically allows it to generate clear predictions which can be directly and decisively tested. We empirically verify across four different environments that FiLex predicts the correct correlation between hyperparameters (training steps, lexicon size, learning rate, rollout buffer size, and Gumbel-Softmax temperature) and the emergent language's entropy in 20 out of 20 environment-hyperparameter combinations. Furthermore, our experiments reveal that different environments show diverse relationships between their hyperparameters and entropy which demonstrates the need for a model which can make well-defined predictions at a precise level of granularity.