 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRiSM: Benchmarking Phone Realization in Speech Models
Jan 20, 2026Phone recognition (PR) serves as the atomic interface for language-agnostic modeling for cross-lingual speech processing and phonetic analysis. Despite prolonged efforts in developing PR systems, current evaluations only measure surface-level transcription accuracy. We introduce PRiSM, the first open-source benchmark designed to expose blind spots in phonetic perception through intrinsic and extrinsic evaluation of PR systems. PRiSM standardizes transcription-based evaluation and assesses downstream utility in clinical, educational, and multilingual settings with transcription and representation probes. We find that diverse language exposure during training is key to PR performance, encoder-CTC models are the most stable, and specialized PR models still outperform Large Audio Language Models. PRiSM releases code, recipes, and datasets to move the field toward multilingual speech models with robust phonetic ability: https://github.com/changelinglab/prism.
ELCC: the Emergent Language Corpus Collection
Jul 04, 2024We introduce the Emergent Language Corpus Collection (ELCC): a collection of corpora collected from open source implementations of emergent communication systems across the literature. These systems include a variety of signalling game environments as well as more complex tasks like a social deduction game and embodied navigation. Each corpus is annotated with metadata describing the characteristics of the source system as well as a suite of analyses of the corpus (e.g., size, entropy, average message length). Currently, research studying emergent languages requires directly running different systems which takes time away from actual analyses of such languages, limits the variety of languages that are studied, and presents a barrier to entry for researchers without a background in deep learning. The availability of a substantial collection of well-documented emergent language corpora, then, will enable new directions of research which focus their purview on the properties of emergent languages themselves rather than on experimental apparatus.
XferBench: a Data-Driven Benchmark for Emergent Language
Jul 03, 2024In this paper, we introduce a benchmark for evaluating the overall quality of emergent languages using data-driven methods. Specifically, we interpret the notion of the "quality" of an emergent language as its similarity to human language within a deep learning framework. We measure this by using the emergent language as pretraining data for a downstream NLP tasks in human language -- the better the downstream performance, the better the emergent language. We implement this benchmark as an easy-to-use Python package that only requires a text file of utterances from the emergent language to be evaluated. Finally, we empirically test the benchmark's validity using human, synthetic, and emergent language baselines.
* 15 pages, 5 figures
A Review of the Applications of Deep Learning-Based Emergent Communication
Jul 03, 2024Emergent communication, or emergent language, is the field of research which studies how human language-like communication systems emerge de novo in deep multi-agent reinforcement learning environments. The possibilities of replicating the emergence of a complex behavior like language have strong intuitive appeal, yet it is necessary to complement this with clear notions of how such research can be applicable to other fields of science, technology, and engineering. This paper comprehensively reviews the applications of emergent communication research across machine learning, natural language processing, linguistics, and cognitive science. Each application is illustrated with a description of its scope, an explication of emergent communication's unique role in addressing it, a summary of the extant literature working towards the application, and brief recommendations for near-term research directions.
* 49 pages, 15 figures
Mathematically Modeling the Lexicon Entropy of Emergent Language
Nov 28, 2022



We formulate a stochastic process, FiLex, as a mathematical model of lexicon entropy in deep learning-based emergent language systems. Defining a model mathematically allows it to generate clear predictions which can be directly and decisively tested. We empirically verify across four different environments that FiLex predicts the correct correlation between hyperparameters (training steps, lexicon size, learning rate, rollout buffer size, and Gumbel-Softmax temperature) and the emergent language's entropy in 20 out of 20 environment-hyperparameter combinations. Furthermore, our experiments reveal that different environments show diverse relationships between their hyperparameters and entropy which demonstrates the need for a model which can make well-defined predictions at a precise level of granularity.
Recommendations for Systematic Research on Emergent Language
Jun 22, 2022Emergent language is unique among fields within the discipline of machine learning for its open-endedness, not obviously presenting well-defined problems to be solved. As a result, the current research in the field has largely been exploratory: focusing on establishing new problems, techniques, and phenomena. Yet after these problems have been established, subsequent progress requires research which can measurably demonstrate how it improves on prior approaches. This type of research is what we call systematic research; in this paper, we illustrate this mode of research specifically for emergent language. We first identify the overarching goals of emergent language research, categorizing them as either science or engineering. Using this distinction, we present core methodological elements of science and engineering, analyze their role in current emergent language research, and recommend how to apply these elements.
Modeling Emergent Lexicon Formation with a Self-Reinforcing Stochastic Process
Jun 22, 2022

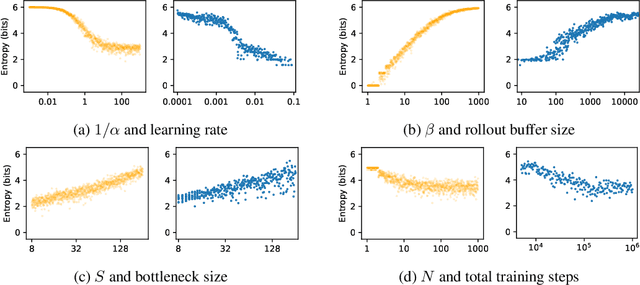
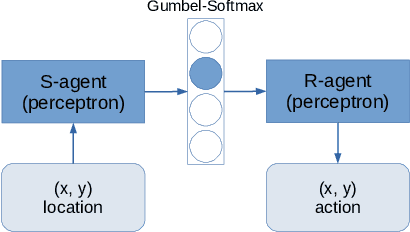
We introduce FiLex, a self-reinforcing stochastic process which models finite lexicons in emergent language experiments. The central property of FiLex is that it is a self-reinforcing process, parallel to the intuition that the more a word is used in a language, the more its use will continue. As a theoretical model, FiLex serves as a way to both explain and predict the behavior of the emergent language system. We empirically test FiLex's ability to capture the relationship between the emergent language's hyperparameters and the lexicon's Shannon entropy.
Case Study: Deontological Ethics in NLP
Oct 09, 2020
Recent work in natural language processing (NLP) has focused on ethical challenges such as understanding and mitigating bias in data and algorithms; identifying objectionable content like hate speech, stereotypes and offensive language; and building frameworks for better system design and data handling practices. However, there has been little discussion about the ethical foundations that underlie these efforts. In this work, we study one ethical theory, namely deontological ethics, from the perspective of NLP. In particular, we focus on the generalization principle and the respect for autonomy through informed consent. We provide four case studies to demonstrate how these principles can be used with NLP systems. We also recommend directions to avoid the ethical issues in these systems.
Detecting Compromised Implicit Association Test Results Using Supervised Learning
Sep 03, 2019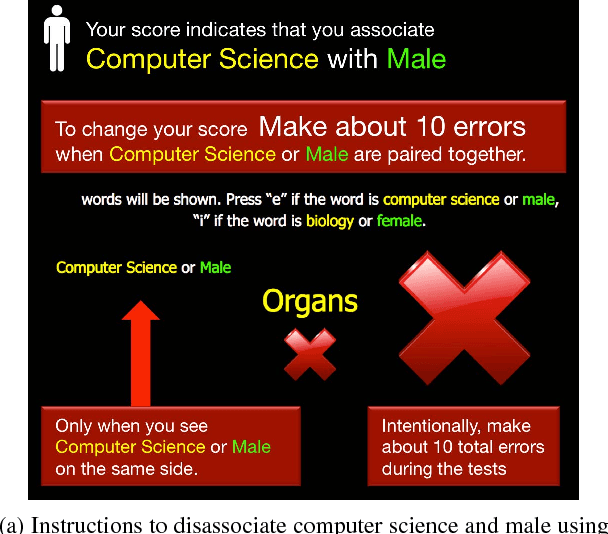
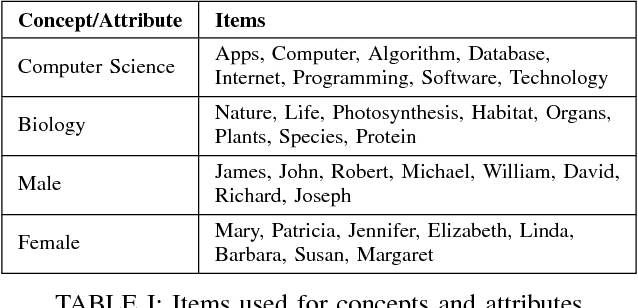

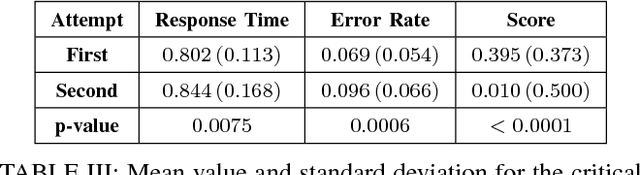
An implicit association test is a human psychological test used to measure subconscious associations. While widely recognized by psychologists as an effective tool in measuring attitudes and biases, the validity of the results can be compromised if a subject does not follow the instructions or attempts to manipulate the outcome. Compared to previous work, we collect training data using a more generalized methodology. We train a variety of different classifiers to identify a participant's first attempt versus a second possibly compromised attempt. To compromise the second attempt, participants are shown their score and are instructed to change it using one of five randomly selected deception methods. Compared to previous work, our methodology demonstrates a more robust and practical framework for accurately identifying a wide variety of deception techniques applicable to the IAT.
* 6 pages, 1 figure
Using LSTMs to Model the Java Programming Language
Aug 26, 2019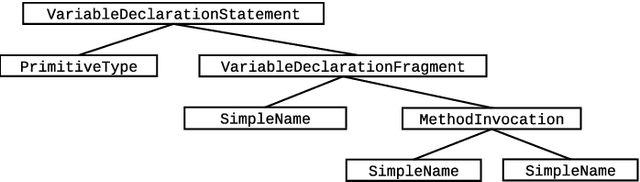
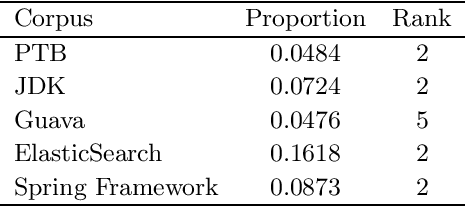
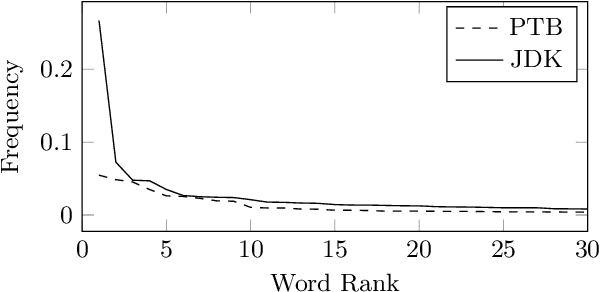
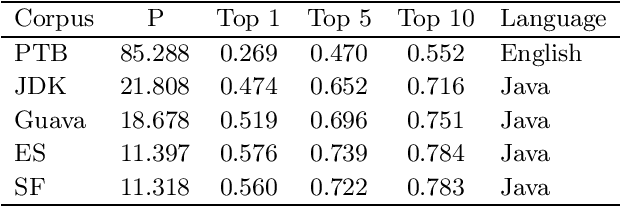
Recurrent neural networks (RNNs), specifically long-short term memory networks (LSTMs), can model natural language effectively. This research investigates the ability for these same LSTMs to perform next "word" prediction on the Java programming language. Java source code from four different repositories undergoes a transformation that preserves the logical structure of the source code and removes the code's various specificities such as variable names and literal values. Such datasets and an additional English language corpus are used to train and test standard LSTMs' ability to predict the next element in a sequence. Results suggest that LSTMs can effectively model Java code achieving perplexities under 22 and accuracies above 0.47, which is an improvement over LSTM's performance on the English language which demonstrated a perplexity of 85 and an accuracy of 0.27. This research can have applicability in other areas such as syntactic template suggestion and automated bug patching.
* 9 pages, 2 figures