 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Inference of Reward Machines and Policies for Reinforcement Learning
Sep 12, 2019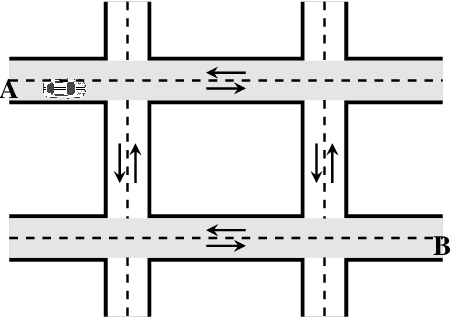

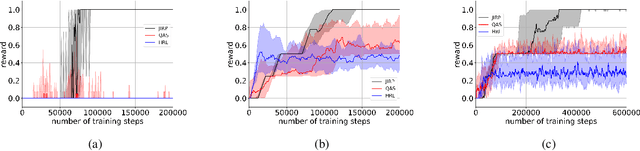
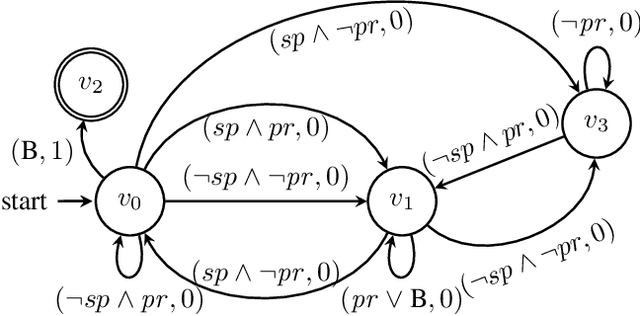
Incorporating high-level knowledge is an effective way to expedite reinforcement learning (RL), especially for complex tasks with sparse rewards. We investigate an RL problem where the high-level knowledge is in the form of reward machines, i.e., a type of Mealy machine that encodes the reward functions. We focus on a setting in which this knowledge is a priori not available to the learning agent. We develop an iterative algorithm that performs joint inference of reward machines and policies for RL (more specifically, q-learning). In each iteration, the algorithm maintains a hypothesis reward machine and a sample of RL episodes. It derives q-functions from the current hypothesis reward machine, and performs RL to update the q-functions. While performing RL, the algorithm updates the sample by adding RL episodes along which the obtained rewards are inconsistent with the rewards based on the current hypothesis reward machine. In the next iteration, the algorithm infers a new hypothesis reward machine from the updated sample. Based on an equivalence relationship we defined between states of reward machines, we transfer the q-functions between the hypothesis reward machines in consecutive iterations. We prove that the proposed algorithm converges almost surely to an optimal policy in the limit if a minimal reward machine can be inferred and the maximal length of each RL episode is sufficiently long. The experiments show that learning high-level knowledge in the form of reward machines can lead to fast convergence to optimal policies in RL, while standard RL methods such as q-learning and hierarchical RL methods fail to converge to optimal policies after a substantial number of training steps in many tasks.
Learning Linear Temporal Properties
Sep 20, 2018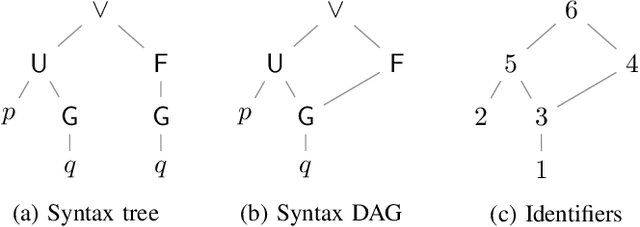
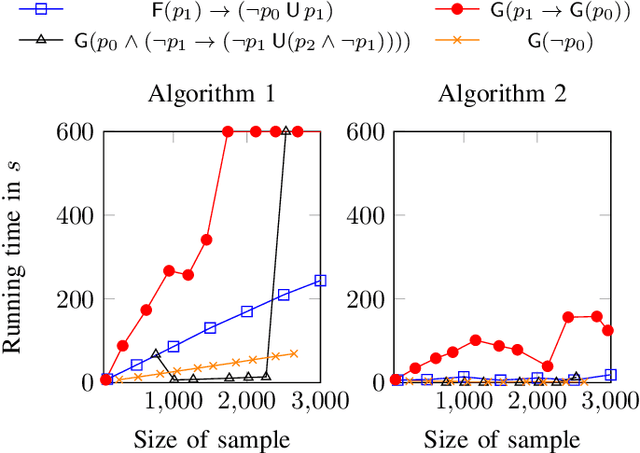
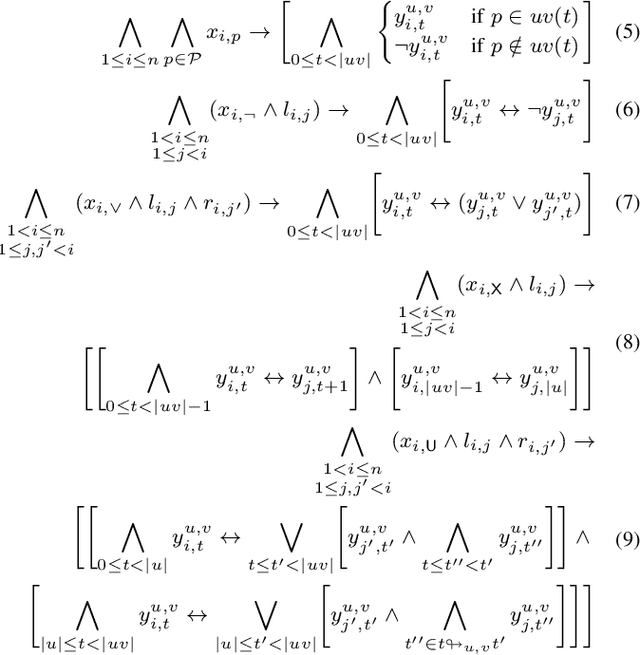
We present two novel algorithms for learning formulas in Linear Temporal Logic (LTL) from examples. The first learning algorithm reduces the learning task to a series of satisfiability problems in propositional Boolean logic and produces a smallest LTL formula (in terms of the number of subformulas) that is consistent with the given data. Our second learning algorithm, on the other hand, combines the SAT-based learning algorithm with classical algorithms for learning decision trees. The result is a learning algorithm that scales to real-world scenarios with hundreds of examples, but can no longer guarantee to produce minimal consistent LTL formulas. We compare both learning algorithms and demonstrate their performance on a wide range of synthetic benchmarks. Additionally, we illustrate their usefulness on the task of understanding executions of a leader election protocol.
Precise but Natural Specification for Robot Tasks
Sep 20, 2018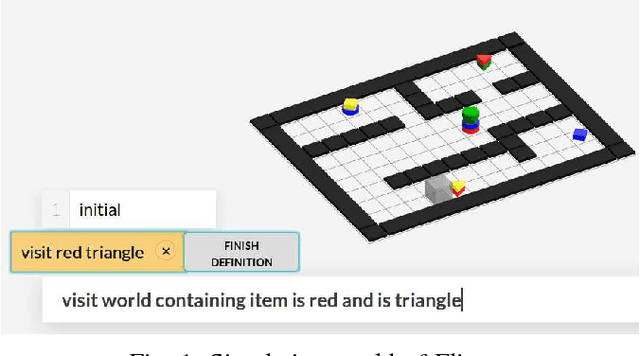

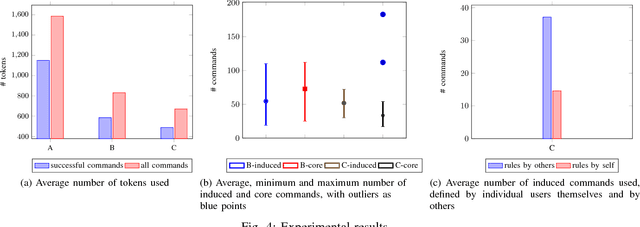
We present Flipper, a natural language interface for describing high-level task specifications for robots that are compiled into robot actions. Flipper starts with a formal core language for task planning that allows expressing rich temporal specifications and uses a semantic parser to provide a natural language interface. Flipper provides immediate visual feedback by executing an automatically constructed plan of the task in a graphical user interface. This allows the user to resolve potentially ambiguous interpretations. Flipper extends itself via naturalization: its users can add definitions for utterances, from which Flipper induces new rules and adds them to the core language, gradually growing a more and more natural task specification language. Flipper improves the naturalization by generalizing the definition provided by users. Unlike other task-specification systems, Flipper enables natural language interactions while maintaining the expressive power and formal precision of a programming language. We show through an initial user study that natural language interactions and generalization can considerably ease the description of tasks. Moreover, over time, users employ more and more concepts outside of the initial core language. Such extensions are available to the Flipper community, and users can use concepts that others have defined.