 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSylber 2.0: A Universal Syllable Embedding
Jan 29, 2026Scaling spoken language modeling requires speech tokens that are both efficient and universal. Recent work has proposed syllables as promising speech tokens at low temporal resolution, but existing models are constrained to English and fail to capture sufficient acoustic detail. To address this gap, we present Sylber 2.0, a self-supervised framework for coding speech at the syllable level that enables efficient temporal compression and high-fidelity reconstruction. Sylber 2.0 achieves a very low token frequency around 5 Hz, while retaining both linguistic and acoustic detail across multiple languages and expressive styles. Experiments show that it performs on par with previous models operating on high-frequency baselines. Furthermore, Sylber 2.0 enables efficient TTS modeling which can generate speech with competitive intelligibility and quality with SOTA models using only 72M parameters. Moreover, the universality of Sylber 2.0 provides more effective features for low resource ASR than previous speech coding frameworks. In sum, we establish an effective syllable-level abstraction for general spoken language.
Scaling Spoken Language Models with Syllabic Speech Tokenization
Sep 30, 2025Spoken language models (SLMs) typically discretize speech into high-frame-rate tokens extracted from SSL speech models. As the most successful LMs are based on the Transformer architecture, processing these long token streams with self-attention is expensive, as attention scales quadratically with sequence length. A recent SSL work introduces acoustic tokenization of speech at the syllable level, which is more interpretable and potentially more scalable with significant compression in token lengths (4-5 Hz). Yet, their value for spoken language modeling is not yet fully explored. We present the first systematic study of syllabic tokenization for spoken language modeling, evaluating models on a suite of SLU benchmarks while varying training data scale. Syllabic tokens can match or surpass the previous high-frame rate tokens while significantly cutting training and inference costs, achieving more than a 2x reduction in training time and a 5x reduction in FLOPs. Our findings highlight syllable-level language modeling as a promising path to efficient long-context spoken language models.
Deep Speech Synthesis from Multimodal Articulatory Representations
Dec 17, 2024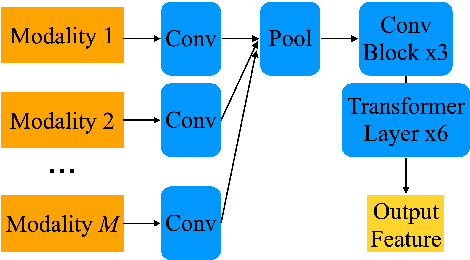
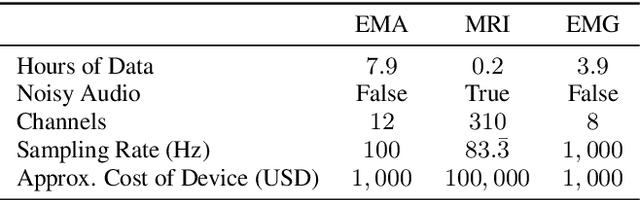
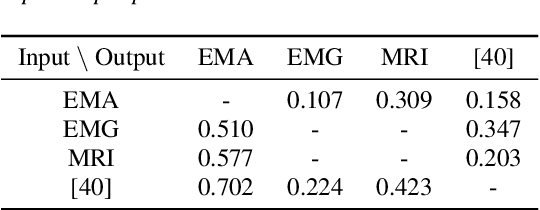

The amount of articulatory data available for training deep learning models is much less compared to acoustic speech data. In order to improve articulatory-to-acoustic synthesis performance in these low-resource settings, we propose a multimodal pre-training framework. On single-speaker speech synthesis tasks from real-time magnetic resonance imaging and surface electromyography inputs, the intelligibility of synthesized outputs improves noticeably. For example, compared to prior work, utilizing our proposed transfer learning methods improves the MRI-to-speech performance by 36% word error rate. In addition to these intelligibility results, our multimodal pre-trained models consistently outperform unimodal baselines on three objective and subjective synthesis quality metrics.
Sylber: Syllabic Embedding Representation of Speech from Raw Audio
Oct 09, 2024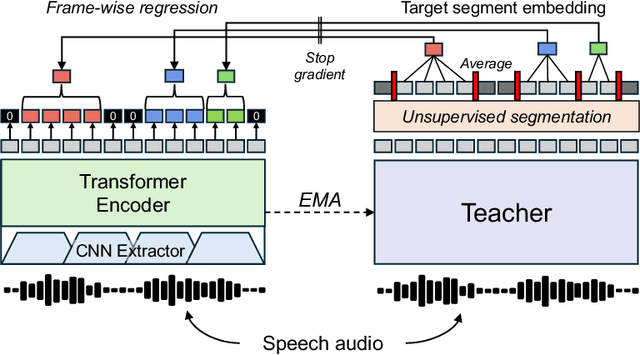
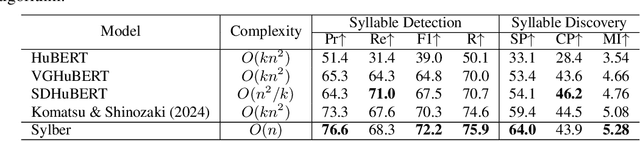
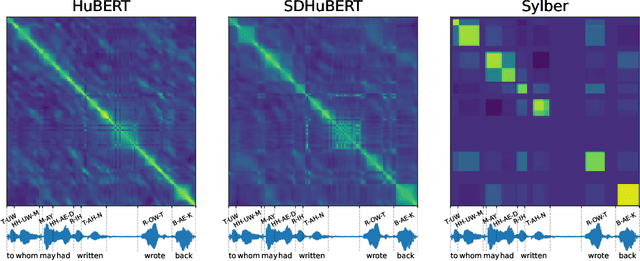
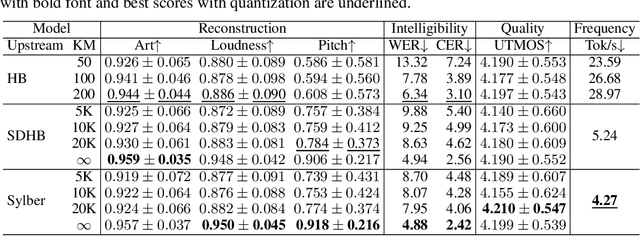
Syllables are compositional units of spoken language that play a crucial role in human speech perception and production. However, current neural speech representations lack structure, resulting in dense token sequences that are costly to process. To bridge this gap, we propose a new model, Sylber, that produces speech representations with clean and robust syllabic structure. Specifically, we propose a self-supervised model that regresses features on syllabic segments distilled from a teacher model which is an exponential moving average of the model in training. This results in a highly structured representation of speech features, offering three key benefits: 1) a fast, linear-time syllable segmentation algorithm, 2) efficient syllabic tokenization with an average of 4.27 tokens per second, and 3) syllabic units better suited for lexical and syntactic understanding. We also train token-to-speech generative models with our syllabic units and show that fully intelligible speech can be reconstructed from these tokens. Lastly, we observe that categorical perception, a linguistic phenomenon of speech perception, emerges naturally in our model, making the embedding space more categorical and sparse than previous self-supervised learning approaches. Together, we present a novel self-supervised approach for representing speech as syllables, with significant potential for efficient speech tokenization and spoken language modeling.
Towards EMG-to-Speech with a Necklace Form Factor
Jul 31, 2024



Electrodes for decoding speech from electromyography (EMG) are typically placed on the face, requiring adhesives that are inconvenient and skin-irritating if used regularly. We explore a different device form factor, where dry electrodes are placed around the neck instead. 11-word, multi-speaker voiced EMG classifiers trained on data recorded with this device achieve 92.7% accuracy. Ablation studies reveal the importance of having more than two electrodes on the neck, and phonological analyses reveal similar classification confusions between neck-only and neck-and-face form factors. Finally, speech-EMG correlation experiments demonstrate a linear relationship between many EMG spectrogram frequency bins and self-supervised speech representation dimensions.
Self-Supervised Models of Speech Infer Universal Articulatory Kinematics
Oct 16, 2023



Self-Supervised Learning (SSL) based models of speech have shown remarkable performance on a range of downstream tasks. These state-of-the-art models have remained blackboxes, but many recent studies have begun "probing" models like HuBERT, to correlate their internal representations to different aspects of speech. In this paper, we show "inference of articulatory kinematics" as fundamental property of SSL models, i.e., the ability of these models to transform acoustics into the causal articulatory dynamics underlying the speech signal. We also show that this abstraction is largely overlapping across the language of the data used to train the model, with preference to the language with similar phonological system. Furthermore, we show that with simple affine transformations, Acoustic-to-Articulatory inversion (AAI) is transferrable across speakers, even across genders, languages, and dialects, showing the generalizability of this property. Together, these results shed new light on the internals of SSL models that are critical to their superior performance, and open up new avenues into language-agnostic universal models for speech engineering, that are interpretable and grounded in speech science.
SD-HuBERT: Self-Distillation Induces Syllabic Organization in HuBERT
Oct 16, 2023



Data-driven unit discovery in self-supervised learning (SSL) of speech has embarked on a new era of spoken language processing. Yet, the discovered units often remain in phonetic space, limiting the utility of SSL representations. Here, we demonstrate that a syllabic organization emerges in learning sentence-level representation of speech. In particular, we adopt "self-distillation" objective to fine-tune the pretrained HuBERT with an aggregator token that summarizes the entire sentence. Without any supervision, the resulting model draws definite boundaries in speech, and the representations across frames show salient syllabic structures. We demonstrate that this emergent structure largely corresponds to the ground truth syllables. Furthermore, we propose a new benchmark task, Spoken Speech ABX, for evaluating sentence-level representation of speech. When compared to previous models, our model outperforms in both unsupervised syllable discovery and learning sentence-level representation. Together, we demonstrate that the self-distillation of HuBERT gives rise to syllabic organization without relying on external labels or modalities, and potentially provides novel data-driven units for spoken language modeling.
Deep Speech Synthesis from MRI-Based Articulatory Representations
Jul 05, 2023
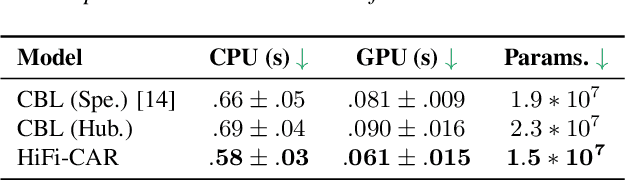
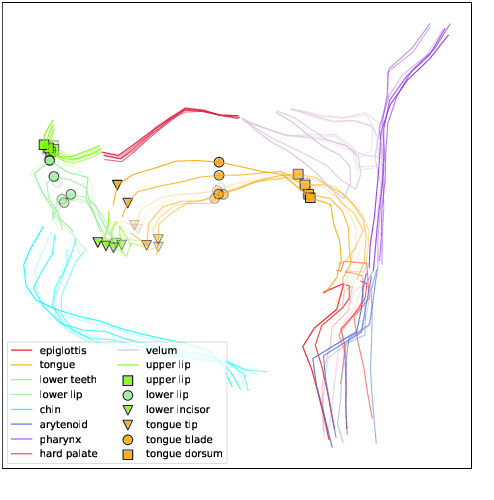
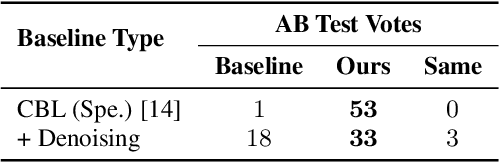
In this paper, we study articulatory synthesis, a speech synthesis method using human vocal tract information that offers a way to develop efficient, generalizable and interpretable synthesizers. While recent advances have enabled intelligible articulatory synthesis using electromagnetic articulography (EMA), these methods lack critical articulatory information like excitation and nasality, limiting generalization capabilities. To bridge this gap, we propose an alternative MRI-based feature set that covers a much more extensive articulatory space than EMA. We also introduce normalization and denoising procedures to enhance the generalizability of deep learning methods trained on MRI data. Moreover, we propose an MRI-to-speech model that improves both computational efficiency and speech fidelity. Finally, through a series of ablations, we show that the proposed MRI representation is more comprehensive than EMA and identify the most suitable MRI feature subset for articulatory synthesis.
Speaker-Independent Acoustic-to-Articulatory Speech Inversion
Feb 14, 2023



To build speech processing methods that can handle speech as naturally as humans, researchers have explored multiple ways of building an invertible mapping from speech to an interpretable space. The articulatory space is a promising inversion target, since this space captures the mechanics of speech production. To this end, we build an acoustic-to-articulatory inversion (AAI) model that leverages autoregression, adversarial training, and self supervision to generalize to unseen speakers. Our approach obtains 0.784 correlation on an electromagnetic articulography (EMA) dataset, improving the state-of-the-art by 12.5%. Additionally, we show the interpretability of these representations through directly comparing the behavior of estimated representations with speech production behavior. Finally, we propose a resynthesis-based AAI evaluation metric that does not rely on articulatory labels, demonstrating its efficacy with an 18-speaker dataset.
Articulatory Representation Learning Via Joint Factor Analysis and Neural Matrix Factorization
Oct 29, 2022Articulatory representation learning is the fundamental research in modeling neural speech production system. Our previous work has established a deep paradigm to decompose the articulatory kinematics data into gestures, which explicitly model the phonological and linguistic structure encoded with human speech production mechanism, and corresponding gestural scores. We continue with this line of work by raising two concerns: (1) The articulators are entangled together in the original algorithm such that some of the articulators do not leverage effective moving patterns, which limits the interpretability of both gestures and gestural scores; (2) The EMA data is sparsely sampled from articulators, which limits the intelligibility of learned representations. In this work, we propose a novel articulatory representation decomposition algorithm that takes the advantage of guided factor analysis to derive the articulatory-specific factors and factor scores. A neural convolutive matrix factorization algorithm is then employed on the factor scores to derive the new gestures and gestural scores. We experiment with the rtMRI corpus that captures the fine-grained vocal tract contours. Both subjective and objective evaluation results suggest that the newly proposed system delivers the articulatory representations that are intelligible, generalizable, efficient and interpretable.