 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Signal Degradation to Computation Collapse: Uncovering the Two Failure Modes of LLM Quantization
Apr 21, 2026Post-Training Quantization (PTQ) is critical for the efficient deployment of Large Language Models (LLMs). While 4-bit quantization is widely regarded as an optimal trade-off, reducing the precision to 2-bit usually triggers a catastrophic ``performance cliff.'' It remains unclear whether the underlying mechanisms differ fundamentally. Consequently, we conduct a systematic mechanistic analysis, revealing two qualitatively distinct failure modes: Signal Degradation, where the computational patterns remain intact but information precision is impaired by cumulative error; and Computation Collapse, where key components fail to function, preventing correct information processing and destroying the signal in the early layers. Guided by this diagnosis, we conduct mechanism-aware interventions, demonstrating that targeted, training-free repair can mitigate Signal Degradation, but remains ineffective for Computation Collapse. Our findings provide a systematic diagnostic framework for PTQ failures and suggest that addressing Computation Collapse requires structural reconstruction rather than mere compensation.
LVOmniBench: Pioneering Long Audio-Video Understanding Evaluation for Omnimodal LLMs
Mar 19, 2026Recent advancements in omnimodal large language models (OmniLLMs) have significantly improved the comprehension of audio and video inputs. However, current evaluations primarily focus on short audio and video clips ranging from 10 seconds to 5 minutes, failing to reflect the demands of real-world applications, where videos typically run for tens of minutes. To address this critical gap, we introduce LVOmniBench, a new benchmark designed specifically for the cross-modal comprehension of long-form audio and video. This dataset comprises high-quality videos sourced from open platforms that feature rich audio-visual dynamics. Through rigorous manual selection and annotation, LVOmniBench comprises 275 videos, ranging in duration from 10 to 90 minutes, and 1,014 question-answer (QA) pairs. LVOmniBench aims to rigorously evaluate the capabilities of OmniLLMs across domains, including long-term memory, temporal localization, fine-grained understanding, and multimodal perception. Our extensive evaluation reveals that current OmniLLMs encounter significant challenges when processing extended audio-visual inputs. Open-source models generally achieve accuracies below 35%, whereas the Gemini 3 Pro reaches a peak accuracy of approximately 65%. We anticipate that this dataset, along with our empirical findings, will stimulate further research and the development of advanced models capable of resolving complex cross-modal understanding problems within long-form audio-visual contexts.
TextShield-R1: Reinforced Reasoning for Tampered Text Detection
Feb 23, 2026The growing prevalence of tampered images poses serious security threats, highlighting the urgent need for reliable detection methods. Multimodal large language models (MLLMs) demonstrate strong potential in analyzing tampered images and generating interpretations. However, they still struggle with identifying micro-level artifacts, exhibit low accuracy in localizing tampered text regions, and heavily rely on expensive annotations for forgery interpretation. To this end, we introduce TextShield-R1, the first reinforcement learning based MLLM solution for tampered text detection and reasoning. Specifically, our approach introduces Forensic Continual Pre-training, an easy-to-hard curriculum that well prepares the MLLM for tampered text detection by harnessing the large-scale cheap data from natural image forensic and OCR tasks. During fine-tuning, we perform Group Relative Policy Optimization with novel reward functions to reduce annotation dependency and improve reasoning capabilities. At inference time, we enhance localization accuracy via OCR Rectification, a method that leverages the MLLM's strong text recognition abilities to refine its predictions. Furthermore, to support rigorous evaluation, we introduce the Text Forensics Reasoning (TFR) benchmark, comprising over 45k real and tampered images across 16 languages, 10 tampering techniques, and diverse domains. Rich reasoning-style annotations are included, allowing for comprehensive assessment. Our TFR benchmark simultaneously addresses seven major limitations of existing benchmarks and enables robust evaluation under cross-style, cross-method, and cross-language conditions. Extensive experiments demonstrate that TextShield-R1 significantly advances the state of the art in interpretable tampered text detection.
IESR:Efficient MCTS-Based Modular Reasoning for Text-to-SQL with Large Language Models
Feb 05, 2026Text-to-SQL is a key natural language processing task that maps natural language questions to SQL queries, enabling intuitive interaction with web-based databases. Although current methods perform well on benchmarks like BIRD and Spider, they struggle with complex reasoning, domain knowledge, and hypothetical queries, and remain costly in enterprise deployment. To address these issues, we propose a framework named IESR(Information Enhanced Structured Reasoning) for lightweight large language models: (i) leverages LLMs for key information understanding and schema linking, and decoupling mathematical computation and SQL generation, (ii) integrates a multi-path reasoning mechanism based on Monte Carlo Tree Search (MCTS) with majority voting, and (iii) introduces a trajectory consistency verification module with a discriminator model to ensure accuracy and consistency. Experimental results demonstrate that IESR achieves state-of-the-art performance on the complex reasoning benchmark LogicCat (24.28 EX) and the Archer dataset (37.28 EX) using only compact lightweight models without fine-tuning. Furthermore, our analysis reveals that current coder models exhibit notable biases and deficiencies in physical knowledge, mathematical computation, and common-sense reasoning, highlighting important directions for future research. We released code at https://github.com/Ffunkytao/IESR-SLM.
OmniAgent: Audio-Guided Active Perception Agent for Omnimodal Audio-Video Understanding
Dec 29, 2025Omnimodal large language models have made significant strides in unifying audio and visual modalities; however, they often lack the fine-grained cross-modal understanding and have difficulty with multimodal alignment. To address these limitations, we introduce OmniAgent, a fully audio-guided active perception agent that dynamically orchestrates specialized tools to achieve more fine-grained audio-visual reasoning. Unlike previous works that rely on rigid, static workflows and dense frame-captioning, this paper demonstrates a paradigm shift from passive response generation to active multimodal inquiry. OmniAgent employs dynamic planning to autonomously orchestrate tool invocation on demand, strategically concentrating perceptual attention on task-relevant cues. Central to our approach is a novel coarse-to-fine audio-guided perception paradigm, which leverages audio cues to localize temporal events and guide subsequent reasoning. Extensive empirical evaluations on three audio-video understanding benchmarks demonstrate that OmniAgent achieves state-of-the-art performance, surpassing leading open-source and proprietary models by substantial margins of 10% - 20% accuracy.
StreamingAssistant: Efficient Visual Token Pruning for Accelerating Online Video Understanding
Dec 14, 2025Online video understanding is essential for applications like public surveillance and AI glasses. However, applying Multimodal Large Language Models (MLLMs) to this domain is challenging due to the large number of video frames, resulting in high GPU memory usage and computational latency. To address these challenges, we propose token pruning as a means to reduce context length while retaining critical information. Specifically, we introduce a novel redundancy metric, Maximum Similarity to Spatially Adjacent Video Tokens (MSSAVT), which accounts for both token similarity and spatial position. To mitigate the bidirectional dependency between pruning and redundancy, we further design a masked pruning strategy that ensures only mutually unadjacent tokens are pruned. We also integrate an existing temporal redundancy-based pruning method to eliminate temporal redundancy of the video modality. Experimental results on multiple online and offline video understanding benchmarks demonstrate that our method significantly improves the accuracy (i.e., by 4\% at most) while incurring a negligible pruning latency (i.e., less than 1ms). Our full implementation will be made publicly available.
OmniZip: Audio-Guided Dynamic Token Compression for Fast Omnimodal Large Language Models
Nov 18, 2025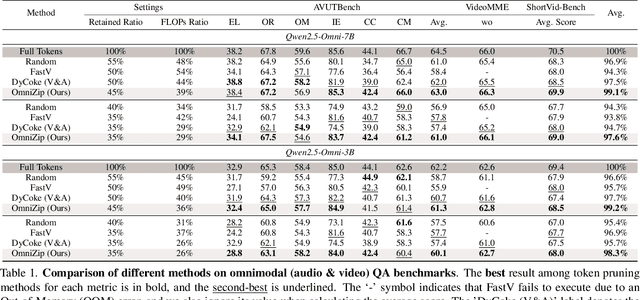
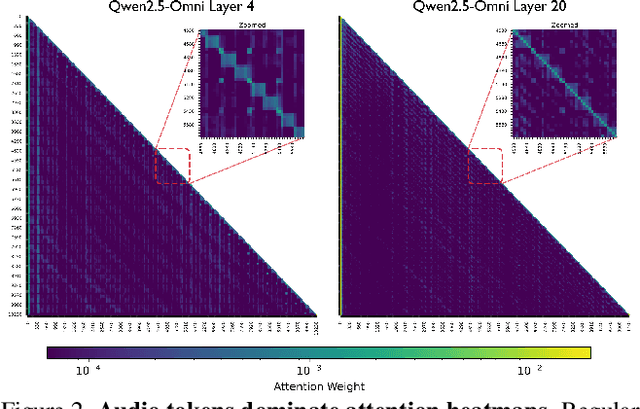
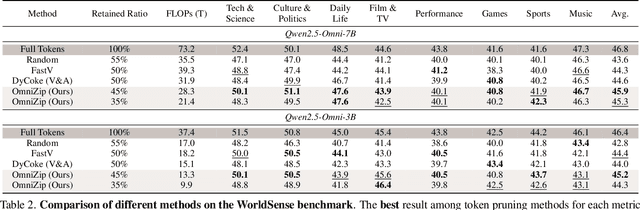
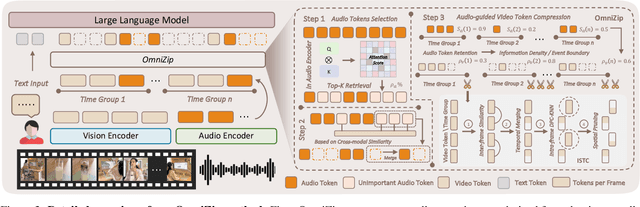
Omnimodal large language models (OmniLLMs) have attracted increasing research attention of late towards unified audio-video understanding, wherein processing audio-video token sequences creates a significant computational bottleneck, however. Existing token compression methods have yet to accommodate this emerging need of jointly compressing multimodal tokens. To bridge this gap, we present OmniZip, a training-free, audio-guided audio-visual token-compression framework that optimizes multimodal token representation and accelerates inference. Specifically, OmniZip first identifies salient audio tokens, then computes an audio retention score for each time group to capture information density, thereby dynamically guiding video token pruning and preserving cues from audio anchors enhanced by cross-modal similarity. For each time window, OmniZip compresses the video tokens using an interleaved spatio-temporal scheme. Extensive empirical results demonstrate the merits of OmniZip - it achieves 3.42X inference speedup and 1.4X memory reduction over other top-performing counterparts, while maintaining performance with no training.
SR-KI: Scalable and Real-Time Knowledge Integration into LLMs via Supervised Attention
Nov 09, 2025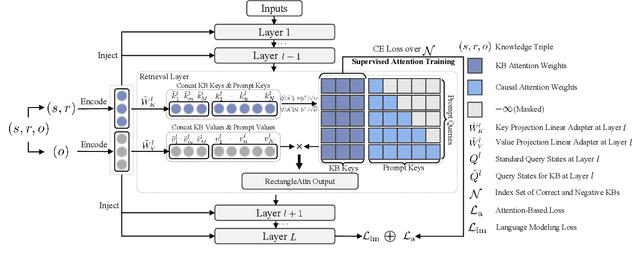
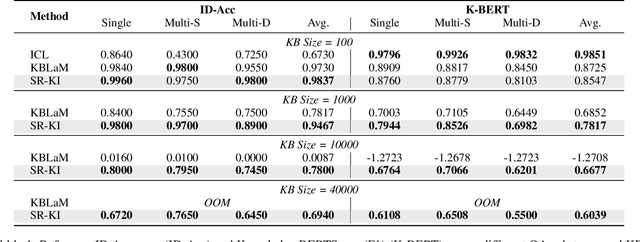
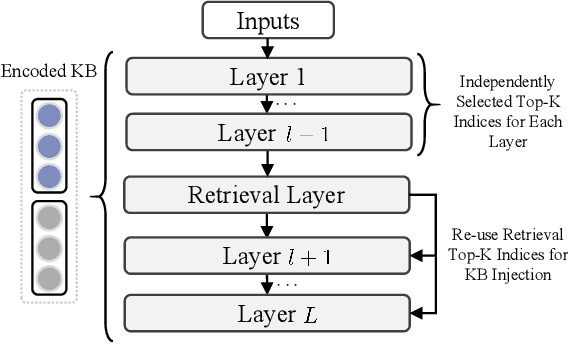
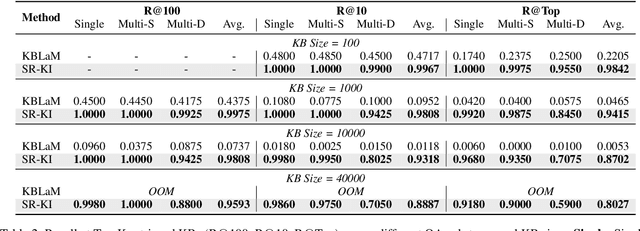
This paper proposes SR-KI, a novel approach for integrating real-time and large-scale structured knowledge bases (KBs) into large language models (LLMs). SR-KI begins by encoding KBs into key-value pairs using a pretrained encoder, and injects them into LLMs' KV cache. Building on this representation, we employ a two-stage training paradigm: first locating a dedicated retrieval layer within the LLM, and then applying an attention-based loss at this layer to explicitly supervise attention toward relevant KB entries. Unlike traditional retrieval-augmented generation methods that rely heavily on the performance of external retrievers and multi-stage pipelines, SR-KI supports end-to-end inference by performing retrieval entirely within the models latent space. This design enables efficient compression of injected knowledge and facilitates dynamic knowledge updates. Comprehensive experiments demonstrate that SR-KI enables the integration of up to 40K KBs into a 7B LLM on a single A100 40GB GPU, and achieves strong retrieval performance, maintaining over 98% Recall@10 on the best-performing task and exceeding 88% on average across all tasks. Task performance on question answering and KB ID generation also demonstrates that SR-KI maintains strong performance while achieving up to 99.75% compression of the injected KBs.
EvolKV: Evolutionary KV Cache Compression for LLM Inference
Sep 10, 2025Existing key-value (KV) cache compression methods typically rely on heuristics, such as uniform cache allocation across layers or static eviction policies, however, they ignore the critical interplays among layer-specific feature patterns and task performance, which can lead to degraded generalization. In this paper, we propose EvolKV, an adaptive framework for layer-wise, task-driven KV cache compression that jointly optimizes the memory efficiency and task performance. By reformulating cache allocation as a multi-objective optimization problem, EvolKV leverages evolutionary search to dynamically configure layer budgets while directly maximizing downstream performance. Extensive experiments on 11 tasks demonstrate that our approach outperforms all baseline methods across a wide range of KV cache budgets on long-context tasks and surpasses heuristic baselines by up to 7 percentage points on GSM8K. Notably, EvolKV achieves superior performance over the full KV cache setting on code completion while utilizing only 1.5% of the original budget, suggesting the untapped potential in learned compression strategies for KV cache budget allocation.
TableEval: A Real-World Benchmark for Complex, Multilingual, and Multi-Structured Table Question Answering
Jun 04, 2025LLMs have shown impressive progress in natural language processing. However, they still face significant challenges in TableQA, where real-world complexities such as diverse table structures, multilingual data, and domain-specific reasoning are crucial. Existing TableQA benchmarks are often limited by their focus on simple flat tables and suffer from data leakage. Furthermore, most benchmarks are monolingual and fail to capture the cross-lingual and cross-domain variability in practical applications. To address these limitations, we introduce TableEval, a new benchmark designed to evaluate LLMs on realistic TableQA tasks. Specifically, TableEval includes tables with various structures (such as concise, hierarchical, and nested tables) collected from four domains (including government, finance, academia, and industry reports). Besides, TableEval features cross-lingual scenarios with tables in Simplified Chinese, Traditional Chinese, and English. To minimize the risk of data leakage, we collect all data from recent real-world documents. Considering that existing TableQA metrics fail to capture semantic accuracy, we further propose SEAT, a new evaluation framework that assesses the alignment between model responses and reference answers at the sub-question level. Experimental results have shown that SEAT achieves high agreement with human judgment. Extensive experiments on TableEval reveal critical gaps in the ability of state-of-the-art LLMs to handle these complex, real-world TableQA tasks, offering insights for future improvements. We make our dataset available here: https://github.com/wenge-research/TableEval.