 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing LSTMs to Model the Java Programming Language
Paper and Code
Aug 26, 2019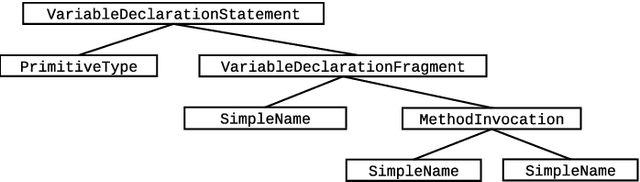
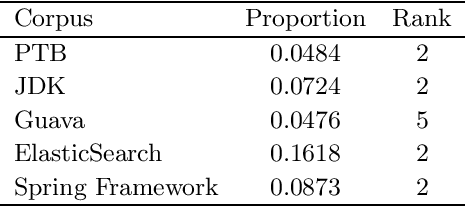
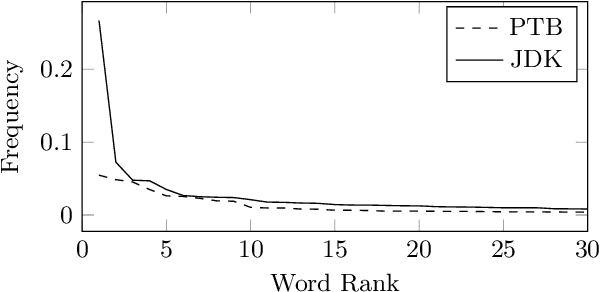
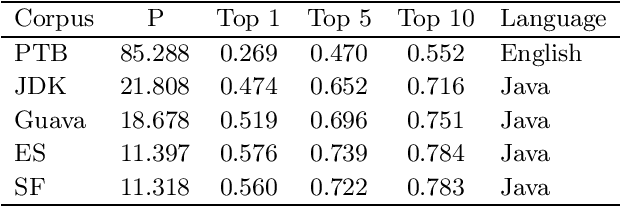
Recurrent neural networks (RNNs), specifically long-short term memory networks (LSTMs), can model natural language effectively. This research investigates the ability for these same LSTMs to perform next "word" prediction on the Java programming language. Java source code from four different repositories undergoes a transformation that preserves the logical structure of the source code and removes the code's various specificities such as variable names and literal values. Such datasets and an additional English language corpus are used to train and test standard LSTMs' ability to predict the next element in a sequence. Results suggest that LSTMs can effectively model Java code achieving perplexities under 22 and accuracies above 0.47, which is an improvement over LSTM's performance on the English language which demonstrated a perplexity of 85 and an accuracy of 0.27. This research can have applicability in other areas such as syntactic template suggestion and automated bug patching.