 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProsodic ABX: A Language-Agnostic Method for Measuring Prosodic Contrast in Speech Representations
Apr 02, 2026Speech representations from self-supervised speech models (S3Ms) are known to be sensitive to phonemic contrasts, but their sensitivity to prosodic contrasts has not been directly measured. The ABX discrimination task has been used to measure phonemic contrast in S3M representations via minimal pairs. We introduce prosodic ABX, an extension of this framework to evaluate prosodic contrast with only a handful of examples and no explicit labels. Also, we build and release a dataset of English and Japanese minimal pairs and use it along with a Mandarin dataset to evaluate contrast in English stress, Japanese pitch accent, and Mandarin tone. Finally, we show that model and layer rankings are often preserved across several experimental conditions, making it practical for low-resource settings.
An Empirical Recipe for Universal Phone Recognition
Mar 30, 2026Phone recognition (PR) is a key enabler of multilingual and low-resource speech processing tasks, yet robust performance remains elusive. Highly performant English-focused models do not generalize across languages, while multilingual models underutilize pretrained representations. It also remains unclear how data scale, architecture, and training objective contribute to multilingual PR. We present PhoneticXEUS -- trained on large-scale multilingual data and achieving state-of-the-art performance on both multilingual (17.7% PFER) and accented English speech (10.6% PFER). Through controlled ablations with evaluations across 100+ languages under a unified scheme, we empirically establish our training recipe and quantify the impact of SSL representations, data scale, and loss objectives. In addition, we analyze error patterns across language families, accented speech, and articulatory features. All data and code are released openly.
Adapting Self-Supervised Speech Representations for Cross-lingual Dysarthria Detection in Parkinson's Disease
Mar 23, 2026The limited availability of dysarthric speech data makes cross-lingual detection an important but challenging problem. A key difficulty is that speech representations often encode language-dependent structure that can confound dysarthria detection. We propose a representation-level language shift (LS) that aligns source-language self-supervised speech representations with the target-language distribution using centroid-based vector adaptation estimated from healthy-control speech. We evaluate the approach on oral DDK recordings from Parkinson's disease speech datasets in Czech, German, and Spanish under both cross-lingual and multilingual settings. LS substantially improves sensitivity and F1 in cross-lingual settings, while yielding smaller but consistent gains in multilingual settings. Representation analysis further shows that LS reduces language identity in the embedding space, supporting the interpretation that LS removes language-dependent structure.
Self-Supervised Speech Models Encode Phonetic Context via Position-dependent Orthogonal Subspaces
Mar 13, 2026Transformer-based self-supervised speech models (S3Ms) are often described as contextualized, yet what this entails remains unclear. Here, we focus on how a single frame-level S3M representation can encode phones and their surrounding context. Prior work has shown that S3Ms represent phones compositionally; for example, phonological vectors such as voicing, bilabiality, and nasality vectors are superposed in the S3M representation of [m]. We extend this view by proposing that phonological information from a sequence of neighboring phones is also compositionally encoded in a single frame, such that vectors corresponding to previous, current, and next phones are superposed within a single frame-level representation. We show that this structure has several properties, including orthogonality between relative positions, and emergence of implicit phonetic boundaries. Together, our findings advance our understanding of context-dependent S3M representations.
Multilingual Dysarthric Speech Assessment Using Universal Phone Recognition and Language-Specific Phonemic Contrast Modeling
Jan 29, 2026The growing prevalence of neurological disorders associated with dysarthria motivates the need for automated intelligibility assessment methods that are applicalbe across languages. However, most existing approaches are either limited to a single language or fail to capture language-specific factors shaping intelligibility. We present a multilingual phoneme-production assessment framework that integrates universal phone recognition with language-specific phoneme interpretation using contrastive phonological feature distances for phone-to-phoneme mapping and sequence alignment. The framework yields three metrics: phoneme error rate (PER), phonological feature error rate (PFER), and a newly proposed alignment-free measure, phoneme coverage (PhonCov). Analysis on English, Spanish, Italian, and Tamil show that PER benefits from the combination of mapping and alignment, PFER from alignment alone, and PhonCov from mapping. Further analyses demonstrate that the proposed framework captures clinically meaningful patterns of intelligibility degradation consistent with established observations of dysarthric speech.
PRiSM: Benchmarking Phone Realization in Speech Models
Jan 20, 2026Phone recognition (PR) serves as the atomic interface for language-agnostic modeling for cross-lingual speech processing and phonetic analysis. Despite prolonged efforts in developing PR systems, current evaluations only measure surface-level transcription accuracy. We introduce PRiSM, the first open-source benchmark designed to expose blind spots in phonetic perception through intrinsic and extrinsic evaluation of PR systems. PRiSM standardizes transcription-based evaluation and assesses downstream utility in clinical, educational, and multilingual settings with transcription and representation probes. We find that diverse language exposure during training is key to PR performance, encoder-CTC models are the most stable, and specialized PR models still outperform Large Audio Language Models. PRiSM releases code, recipes, and datasets to move the field toward multilingual speech models with robust phonetic ability: https://github.com/changelinglab/prism.
CS-FLEURS: A Massively Multilingual and Code-Switched Speech Dataset
Sep 17, 2025We present CS-FLEURS, a new dataset for developing and evaluating code-switched speech recognition and translation systems beyond high-resourced languages. CS-FLEURS consists of 4 test sets which cover in total 113 unique code-switched language pairs across 52 languages: 1) a 14 X-English language pair set with real voices reading synthetically generated code-switched sentences, 2) a 16 X-English language pair set with generative text-to-speech 3) a 60 {Arabic, Mandarin, Hindi, Spanish}-X language pair set with the generative text-to-speech, and 4) a 45 X-English lower-resourced language pair test set with concatenative text-to-speech. Besides the four test sets, CS-FLEURS also provides a training set with 128 hours of generative text-to-speech data across 16 X-English language pairs. Our hope is that CS-FLEURS helps to broaden the scope of future code-switched speech research. Dataset link: https://huggingface.co/datasets/byan/cs-fleurs.
Towards Inclusive ASR: Investigating Voice Conversion for Dysarthric Speech Recognition in Low-Resource Languages
May 20, 2025Automatic speech recognition (ASR) for dysarthric speech remains challenging due to data scarcity, particularly in non-English languages. To address this, we fine-tune a voice conversion model on English dysarthric speech (UASpeech) to encode both speaker characteristics and prosodic distortions, then apply it to convert healthy non-English speech (FLEURS) into non-English dysarthric-like speech. The generated data is then used to fine-tune a multilingual ASR model, Massively Multilingual Speech (MMS), for improved dysarthric speech recognition. Evaluation on PC-GITA (Spanish), EasyCall (Italian), and SSNCE (Tamil) demonstrates that VC with both speaker and prosody conversion significantly outperforms the off-the-shelf MMS performance and conventional augmentation techniques such as speed and tempo perturbation. Objective and subjective analyses of the generated data further confirm that the generated speech simulates dysarthric characteristics.
Leveraging Allophony in Self-Supervised Speech Models for Atypical Pronunciation Assessment
Feb 10, 2025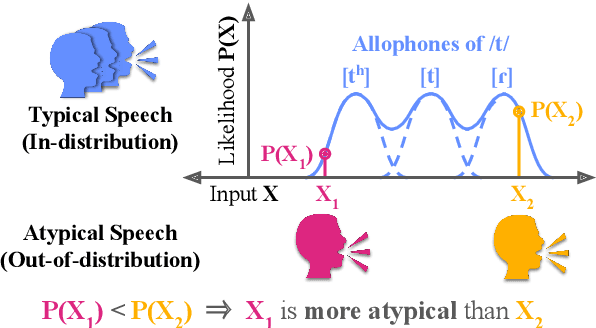
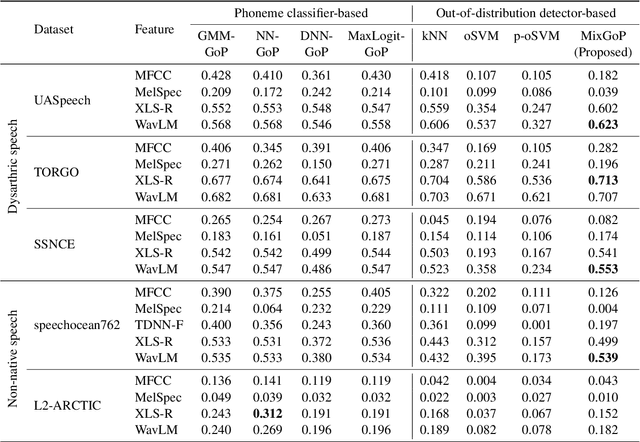
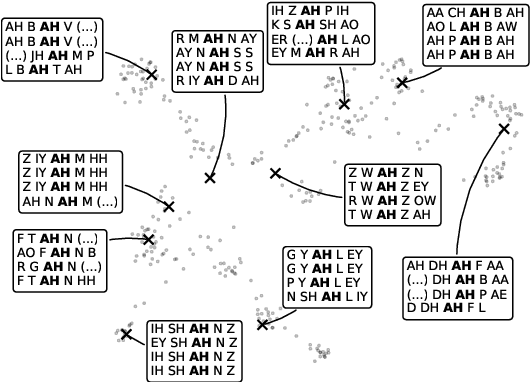
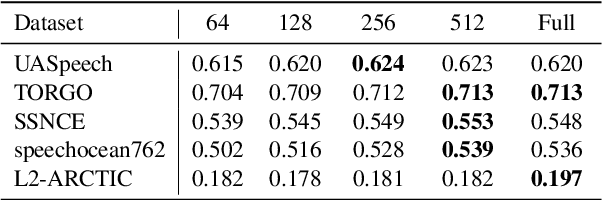
Allophony refers to the variation in the phonetic realization of a phoneme based on its phonetic environment. Modeling allophones is crucial for atypical pronunciation assessment, which involves distinguishing atypical from typical pronunciations. However, recent phoneme classifier-based approaches often simplify this by treating various realizations as a single phoneme, bypassing the complexity of modeling allophonic variation. Motivated by the acoustic modeling capabilities of frozen self-supervised speech model (S3M) features, we propose MixGoP, a novel approach that leverages Gaussian mixture models to model phoneme distributions with multiple subclusters. Our experiments show that MixGoP achieves state-of-the-art performance across four out of five datasets, including dysarthric and non-native speech. Our analysis further suggests that S3M features capture allophonic variation more effectively than MFCCs and Mel spectrograms, highlighting the benefits of integrating MixGoP with S3M features.
Dynamic-SUPERB Phase-2: A Collaboratively Expanding Benchmark for Measuring the Capabilities of Spoken Language Models with 180 Tasks
Nov 08, 2024



Multimodal foundation models, such as Gemini and ChatGPT, have revolutionized human-machine interactions by seamlessly integrating various forms of data. Developing a universal spoken language model that comprehends a wide range of natural language instructions is critical for bridging communication gaps and facilitating more intuitive interactions. However, the absence of a comprehensive evaluation benchmark poses a significant challenge. We present Dynamic-SUPERB Phase-2, an open and evolving benchmark for the comprehensive evaluation of instruction-based universal speech models. Building upon the first generation, this second version incorporates 125 new tasks contributed collaboratively by the global research community, expanding the benchmark to a total of 180 tasks, making it the largest benchmark for speech and audio evaluation. While the first generation of Dynamic-SUPERB was limited to classification tasks, Dynamic-SUPERB Phase-2 broadens its evaluation capabilities by introducing a wide array of novel and diverse tasks, including regression and sequence generation, across speech, music, and environmental audio. Evaluation results indicate that none of the models performed well universally. SALMONN-13B excelled in English ASR, while WavLLM demonstrated high accuracy in emotion recognition, but current models still require further innovations to handle a broader range of tasks. We will soon open-source all task data and the evaluation pipeline.