 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBagpiper: Solving Open-Ended Audio Tasks via Rich Captions
Feb 05, 2026Current audio foundation models typically rely on rigid, task-specific supervision, addressing isolated factors of audio rather than the whole. In contrast, human intelligence processes audio holistically, seamlessly bridging physical signals with abstract cognitive concepts to execute complex tasks. Grounded in this philosophy, we introduce Bagpiper, an 8B audio foundation model that interprets physical audio via rich captions, i.e., comprehensive natural language descriptions that encapsulate the critical cognitive concepts inherent in the signal (e.g., transcription, audio events). By pre-training on a massive corpus of 600B tokens, the model establishes a robust bidirectional mapping between raw audio and this high-level conceptual space. During fine-tuning, Bagpiper adopts a caption-then-process workflow, simulating an intermediate cognitive reasoning step to solve diverse tasks without task-specific priors. Experimentally, Bagpiper outperforms Qwen-2.5-Omni on MMAU and AIRBench for audio understanding and surpasses CosyVoice3 and TangoFlux in generation quality, capable of synthesizing arbitrary compositions of speech, music, and sound effects. To the best of our knowledge, Bagpiper is among the first works that achieve unified understanding generation for general audio. Model, data, and code are available at Bagpiper Home Page.
Context-Driven Dynamic Pruning for Large Speech Foundation Models
May 24, 2025



Speech foundation models achieve strong generalization across languages and acoustic conditions, but require significant computational resources for inference. In the context of speech foundation models, pruning techniques have been studied that dynamically optimize model structures based on the target audio leveraging external context. In this work, we extend this line of research and propose context-driven dynamic pruning, a technique that optimizes the model computation depending on the context between different input frames and additional context during inference. We employ the Open Whisper-style Speech Model (OWSM) and incorporate speaker embeddings, acoustic event embeddings, and language information as additional context. By incorporating the speaker embedding, our method achieves a reduction of 56.7 GFLOPs while improving BLEU scores by a relative 25.7% compared to the fully fine-tuned OWSM model.
Towards Inclusive ASR: Investigating Voice Conversion for Dysarthric Speech Recognition in Low-Resource Languages
May 20, 2025Automatic speech recognition (ASR) for dysarthric speech remains challenging due to data scarcity, particularly in non-English languages. To address this, we fine-tune a voice conversion model on English dysarthric speech (UASpeech) to encode both speaker characteristics and prosodic distortions, then apply it to convert healthy non-English speech (FLEURS) into non-English dysarthric-like speech. The generated data is then used to fine-tune a multilingual ASR model, Massively Multilingual Speech (MMS), for improved dysarthric speech recognition. Evaluation on PC-GITA (Spanish), EasyCall (Italian), and SSNCE (Tamil) demonstrates that VC with both speaker and prosody conversion significantly outperforms the off-the-shelf MMS performance and conventional augmentation techniques such as speed and tempo perturbation. Objective and subjective analyses of the generated data further confirm that the generated speech simulates dysarthric characteristics.
ESPnet-EZ: Python-only ESPnet for Easy Fine-tuning and Integration
Sep 14, 2024We introduce ESPnet-EZ, an extension of the open-source speech processing toolkit ESPnet, aimed at quick and easy development of speech models. ESPnet-EZ focuses on two major aspects: (i) easy fine-tuning and inference of existing ESPnet models on various tasks and (ii) easy integration with popular deep neural network frameworks such as PyTorch-Lightning, Hugging Face transformers and datasets, and Lhotse. By replacing ESPnet design choices inherited from Kaldi with a Python-only, Bash-free interface, we dramatically reduce the effort required to build, debug, and use a new model. For example, to fine-tune a speech foundation model, ESPnet-EZ, compared to ESPnet, reduces the number of newly written code by 2.7x and the amount of dependent code by 6.7x while dramatically reducing the Bash script dependencies. The codebase of ESPnet-EZ is publicly available.
Segment-Level Vectorized Beam Search Based on Partially Autoregressive Inference
Oct 01, 2023



Attention-based encoder-decoder models with autoregressive (AR) decoding have proven to be the dominant approach for automatic speech recognition (ASR) due to their superior accuracy. However, they often suffer from slow inference. This is primarily attributed to the incremental calculation of the decoder. This work proposes a partially AR framework, which employs segment-level vectorized beam search for improving the inference speed of an ASR model based on the hybrid connectionist temporal classification (CTC) attention-based architecture. It first generates an initial hypothesis using greedy CTC decoding, identifying low-confidence tokens based on their output probabilities. We then utilize the decoder to perform segment-level vectorized beam search on these tokens, re-predicting in parallel with minimal decoder calculations. Experimental results show that our method is 12 to 13 times faster in inference on the LibriSpeech corpus over AR decoding whilst preserving high accuracy.
ESPnet-ONNX: Bridging a Gap Between Research and Production
Sep 20, 2022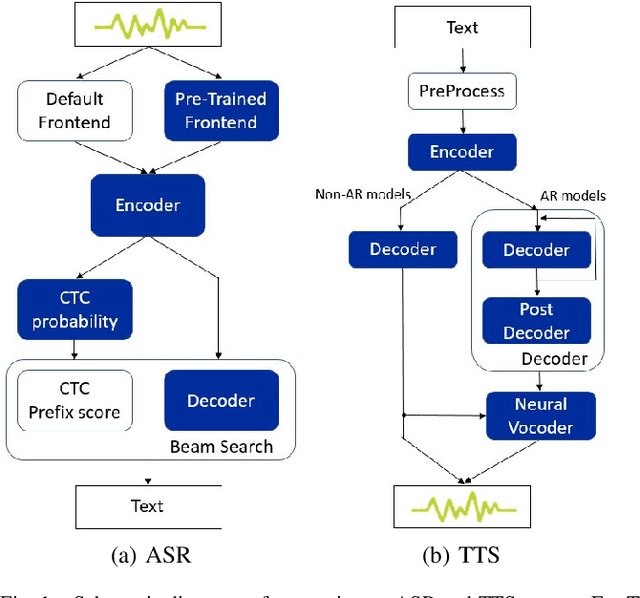
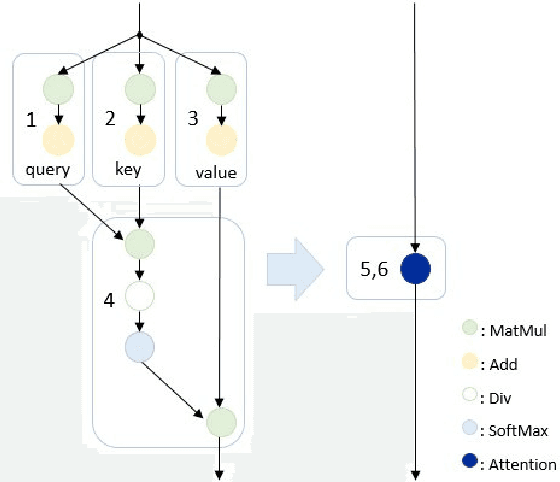

In the field of deep learning, researchers often focus on inventing novel neural network models and improving benchmarks. In contrast, application developers are interested in making models suitable for actual products, which involves optimizing a model for faster inference and adapting a model to various platforms (e.g., C++ and Python). In this work, to fill the gap between the two, we establish an effective procedure for optimizing a PyTorch-based research-oriented model for deployment, taking ESPnet, a widely used toolkit for speech processing, as an instance. We introduce different techniques to ESPnet, including converting a model into an ONNX format, fusing nodes in a graph, and quantizing parameters, which lead to approximately 1.3-2$\times$ speedup in various tasks (i.e., ASR, TTS, speech translation, and spoken language understanding) while keeping its performance without any additional training. Our ESPnet-ONNX will be publicly available at https://github.com/espnet/espnet_onnx
A Comparative Study on Transformer vs RNN in Speech Applications
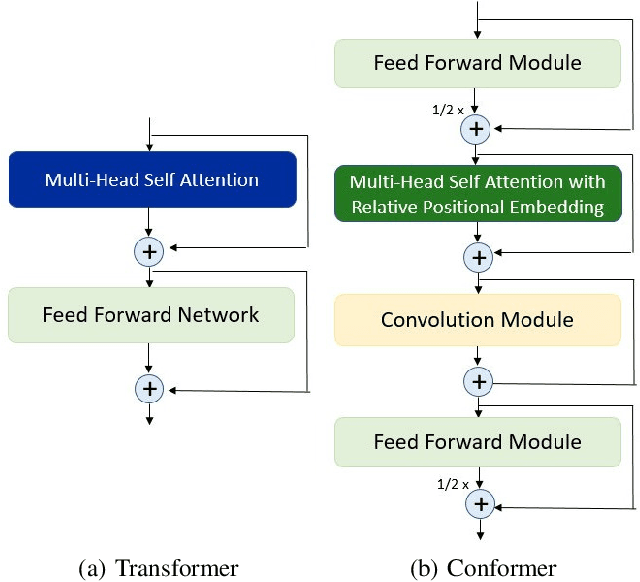
Sep 28, 2019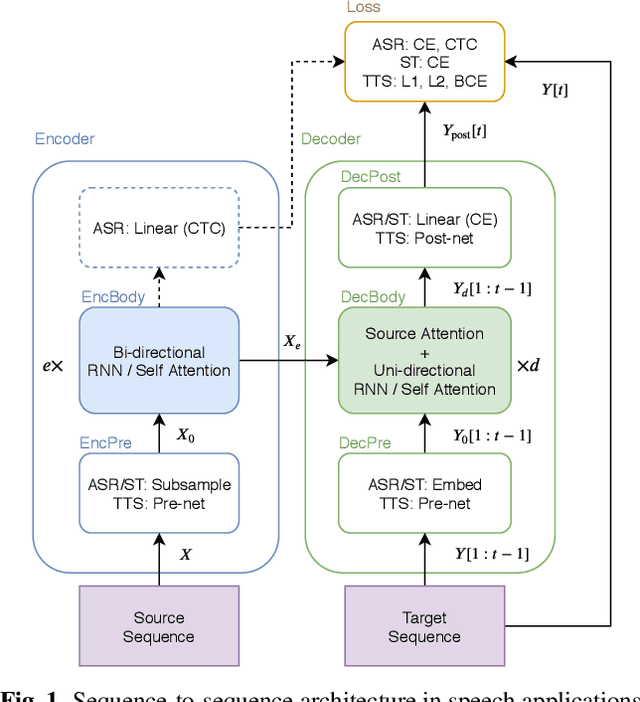
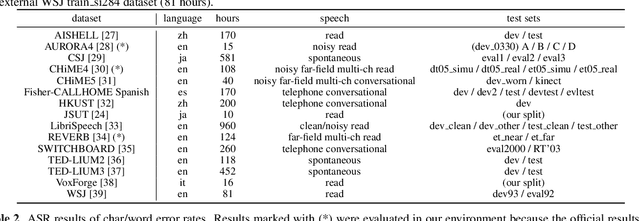
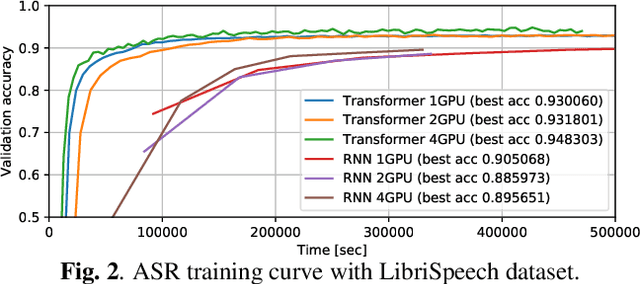
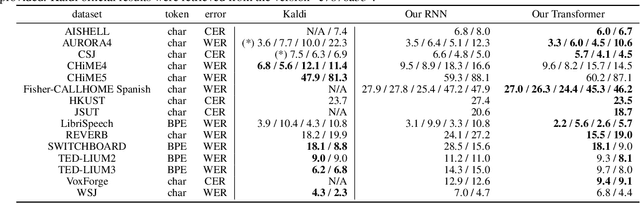
Sequence-to-sequence models have been widely used in end-to-end speech processing, for example, automatic speech recognition (ASR), speech translation (ST), and text-to-speech (TTS). This paper focuses on an emergent sequence-to-sequence model called Transformer, which achieves state-of-the-art performance in neural machine translation and other natural language processing applications. We undertook intensive studies in which we experimentally compared and analyzed Transformer and conventional recurrent neural networks (RNN) in a total of 15 ASR, one multilingual ASR, one ST, and two TTS benchmarks. Our experiments revealed various training tips and significant performance benefits obtained with Transformer for each task including the surprising superiority of Transformer in 13/15 ASR benchmarks in comparison with RNN. We are preparing to release Kaldi-style reproducible recipes using open source and publicly available datasets for all the ASR, ST, and TTS tasks for the community to succeed our exciting outcomes.
* Accepted at ASRU 2019