 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingMOS-Pro: An Comprehensive Benchmark for Singing Quality Assessment
Oct 02, 2025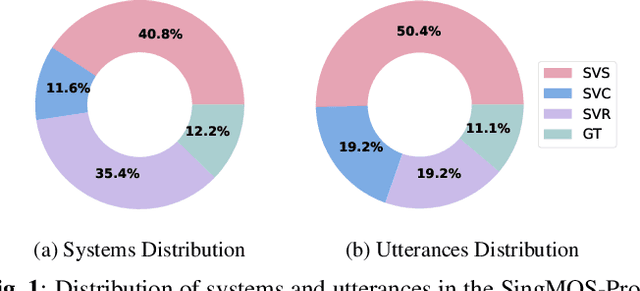

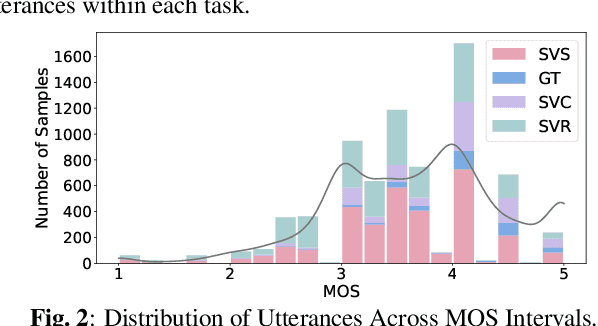

Singing voice generation progresses rapidly, yet evaluating singing quality remains a critical challenge. Human subjective assessment, typically in the form of listening tests, is costly and time consuming, while existing objective metrics capture only limited perceptual aspects. In this work, we introduce SingMOS-Pro, a dataset for automatic singing quality assessment. Building on our preview version SingMOS, which provides only overall ratings, SingMOS-Pro expands annotations of the additional part to include lyrics, melody, and overall quality, offering broader coverage and greater diversity. The dataset contains 7,981 singing clips generated by 41 models across 12 datasets, spanning from early systems to recent advances. Each clip receives at least five ratings from professional annotators, ensuring reliability and consistency. Furthermore, we explore how to effectively utilize MOS data annotated under different standards and benchmark several widely used evaluation methods from related tasks on SingMOS-Pro, establishing strong baselines and practical references for future research. The dataset can be accessed at https://huggingface.co/datasets/TangRain/SingMOS-Pro.
VERSA: A Versatile Evaluation Toolkit for Speech, Audio, and Music
Dec 23, 2024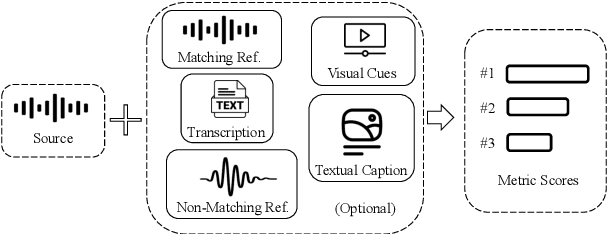
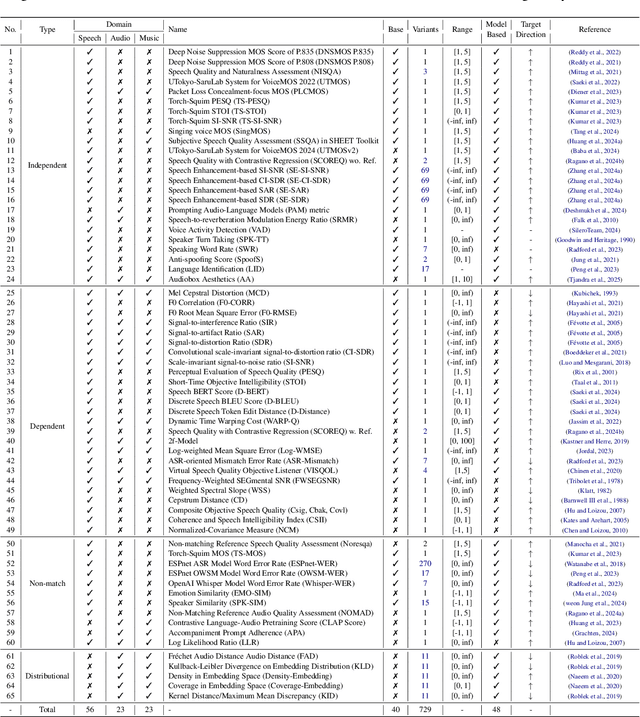

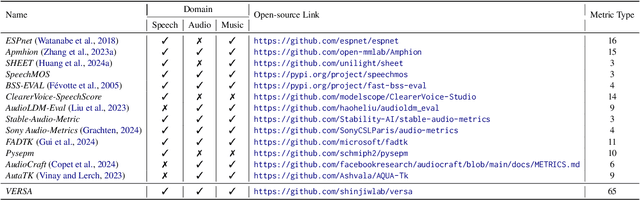
In this work, we introduce VERSA, a unified and standardized evaluation toolkit designed for various speech, audio, and music signals. The toolkit features a Pythonic interface with flexible configuration and dependency control, making it user-friendly and efficient. With full installation, VERSA offers 63 metrics with 711 metric variations based on different configurations. These metrics encompass evaluations utilizing diverse external resources, including matching and non-matching reference audio, text transcriptions, and text captions. As a lightweight yet comprehensive toolkit, VERSA is versatile to support the evaluation of a wide range of downstream scenarios. To demonstrate its capabilities, this work highlights example use cases for VERSA, including audio coding, speech synthesis, speech enhancement, singing synthesis, and music generation. The toolkit is available at https://github.com/shinjiwlab/versa.
Dynamic-SUPERB Phase-2: A Collaboratively Expanding Benchmark for Measuring the Capabilities of Spoken Language Models with 180 Tasks
Nov 08, 2024



Multimodal foundation models, such as Gemini and ChatGPT, have revolutionized human-machine interactions by seamlessly integrating various forms of data. Developing a universal spoken language model that comprehends a wide range of natural language instructions is critical for bridging communication gaps and facilitating more intuitive interactions. However, the absence of a comprehensive evaluation benchmark poses a significant challenge. We present Dynamic-SUPERB Phase-2, an open and evolving benchmark for the comprehensive evaluation of instruction-based universal speech models. Building upon the first generation, this second version incorporates 125 new tasks contributed collaboratively by the global research community, expanding the benchmark to a total of 180 tasks, making it the largest benchmark for speech and audio evaluation. While the first generation of Dynamic-SUPERB was limited to classification tasks, Dynamic-SUPERB Phase-2 broadens its evaluation capabilities by introducing a wide array of novel and diverse tasks, including regression and sequence generation, across speech, music, and environmental audio. Evaluation results indicate that none of the models performed well universally. SALMONN-13B excelled in English ASR, while WavLLM demonstrated high accuracy in emotion recognition, but current models still require further innovations to handle a broader range of tasks. We will soon open-source all task data and the evaluation pipeline.
ESPnet-EZ: Python-only ESPnet for Easy Fine-tuning and Integration
Sep 14, 2024We introduce ESPnet-EZ, an extension of the open-source speech processing toolkit ESPnet, aimed at quick and easy development of speech models. ESPnet-EZ focuses on two major aspects: (i) easy fine-tuning and inference of existing ESPnet models on various tasks and (ii) easy integration with popular deep neural network frameworks such as PyTorch-Lightning, Hugging Face transformers and datasets, and Lhotse. By replacing ESPnet design choices inherited from Kaldi with a Python-only, Bash-free interface, we dramatically reduce the effort required to build, debug, and use a new model. For example, to fine-tune a speech foundation model, ESPnet-EZ, compared to ESPnet, reduces the number of newly written code by 2.7x and the amount of dependent code by 6.7x while dramatically reducing the Bash script dependencies. The codebase of ESPnet-EZ is publicly available.
Muskits-ESPnet: A Comprehensive Toolkit for Singing Voice Synthesis in New Paradigm
Sep 11, 2024

This research presents Muskits-ESPnet, a versatile toolkit that introduces new paradigms to Singing Voice Synthesis (SVS) through the application of pretrained audio models in both continuous and discrete approaches. Specifically, we explore discrete representations derived from SSL models and audio codecs and offer significant advantages in versatility and intelligence, supporting multi-format inputs and adaptable data processing workflows for various SVS models. The toolkit features automatic music score error detection and correction, as well as a perception auto-evaluation module to imitate human subjective evaluating scores. Muskits-ESPnet is available at \url{https://github.com/espnet/espnet}.
On the Evaluation of Speech Foundation Models for Spoken Language Understanding
Jun 14, 2024The Spoken Language Understanding Evaluation (SLUE) suite of benchmark tasks was recently introduced to address the need for open resources and benchmarking of complex spoken language understanding (SLU) tasks, including both classification and sequence generation tasks, on natural speech. The benchmark has demonstrated preliminary success in using pre-trained speech foundation models (SFM) for these SLU tasks. However, the community still lacks a fine-grained understanding of the comparative utility of different SFMs. Inspired by this, we ask: which SFMs offer the most benefits for these complex SLU tasks, and what is the most effective approach for incorporating these SFMs? To answer this, we perform an extensive evaluation of multiple supervised and self-supervised SFMs using several evaluation protocols: (i) frozen SFMs with a lightweight prediction head, (ii) frozen SFMs with a complex prediction head, and (iii) fine-tuned SFMs with a lightweight prediction head. Although the supervised SFMs are pre-trained on much more speech recognition data (with labels), they do not always outperform self-supervised SFMs; the latter tend to perform at least as well as, and sometimes better than, supervised SFMs, especially on the sequence generation tasks in SLUE. While there is no universally optimal way of incorporating SFMs, the complex prediction head gives the best performance for most tasks, although it increases the inference time. We also introduce an open-source toolkit and performance leaderboard, SLUE-PERB, for these tasks and modeling strategies.
CtrSVDD: A Benchmark Dataset and Baseline Analysis for Controlled Singing Voice Deepfake Detection
Jun 04, 2024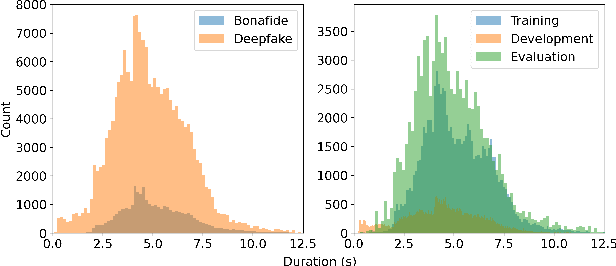
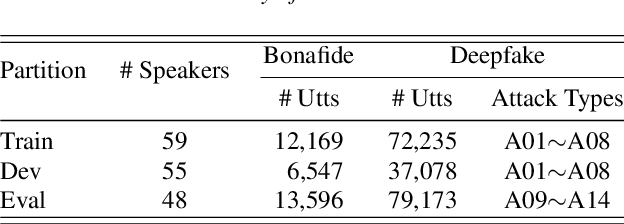
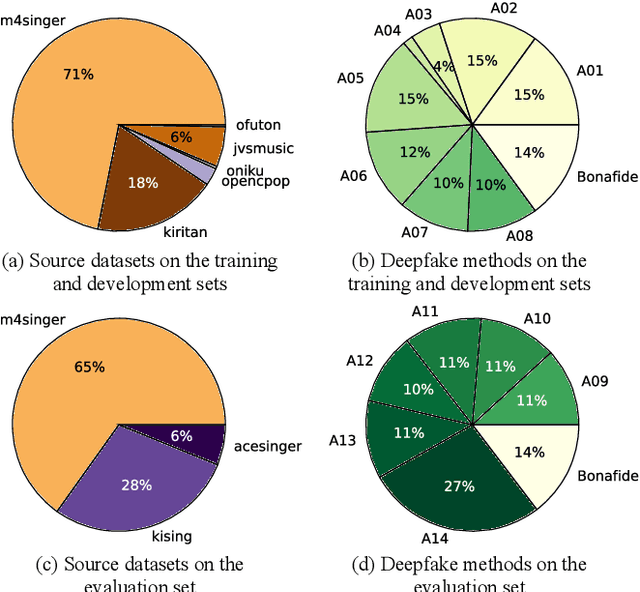

Recent singing voice synthesis and conversion advancements necessitate robust singing voice deepfake detection (SVDD) models. Current SVDD datasets face challenges due to limited controllability, diversity in deepfake methods, and licensing restrictions. Addressing these gaps, we introduce CtrSVDD, a large-scale, diverse collection of bonafide and deepfake singing vocals. These vocals are synthesized using state-of-the-art methods from publicly accessible singing voice datasets. CtrSVDD includes 47.64 hours of bonafide and 260.34 hours of deepfake singing vocals, spanning 14 deepfake methods and involving 164 singer identities. We also present a baseline system with flexible front-end features, evaluated against a structured train/dev/eval split. The experiments show the importance of feature selection and highlight a need for generalization towards deepfake methods that deviate further from training distribution. The CtrSVDD dataset and baselines are publicly accessible.
SVDD Challenge 2024: A Singing Voice Deepfake Detection Challenge Evaluation Plan
May 08, 2024



The rapid advancement of AI-generated singing voices, which now closely mimic natural human singing and align seamlessly with musical scores, has led to heightened concerns for artists and the music industry. Unlike spoken voice, singing voice presents unique challenges due to its musical nature and the presence of strong background music, making singing voice deepfake detection (SVDD) a specialized field requiring focused attention. To promote SVDD research, we recently proposed the "SVDD Challenge," the very first research challenge focusing on SVDD for lab-controlled and in-the-wild bonafide and deepfake singing voice recordings. The challenge will be held in conjunction with the 2024 IEEE Spoken Language Technology Workshop (SLT 2024).