 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMMT-IF: A Challenging Multimodal Multi-Turn Instruction Following Benchmark
Sep 26, 2024



Evaluating instruction following capabilities for multimodal, multi-turn dialogue is challenging. With potentially multiple instructions in the input model context, the task is time-consuming for human raters and we show LLM based judges are biased towards answers from the same model. We propose MMMT-IF, an image based multi-turn Q$\&$A evaluation set with added global instructions between questions, constraining the answer format. This challenges models to retrieve instructions dispersed across long dialogues and reason under instruction constraints. All instructions are objectively verifiable through code execution. We introduce the Programmatic Instruction Following ($\operatorname{PIF}$) metric to measure the fraction of the instructions that are correctly followed while performing a reasoning task. The $\operatorname{PIF-N-K}$ set of metrics further evaluates robustness by measuring the fraction of samples in a corpus where, for each sample, at least K out of N generated model responses achieve a $\operatorname{PIF}$ score of one. The $\operatorname{PIF}$ metric aligns with human instruction following ratings, showing 60 percent correlation. Experiments show Gemini 1.5 Pro, GPT-4o, and Claude 3.5 Sonnet, have a $\operatorname{PIF}$ metric that drops from 0.81 on average at turn 1 across the models, to 0.64 at turn 20. Across all turns, when each response is repeated 4 times ($\operatorname{PIF-4-4}$), GPT-4o and Gemini successfully follow all instructions only $11\%$ of the time. When all the instructions are also appended to the end of the model input context, the $\operatorname{PIF}$ metric improves by 22.3 points on average, showing that the challenge with the task lies not only in following the instructions, but also in retrieving the instructions spread out in the model context. We plan to open source the MMMT-IF dataset and metric computation code.
Muskits-ESPnet: A Comprehensive Toolkit for Singing Voice Synthesis in New Paradigm
Sep 11, 2024

This research presents Muskits-ESPnet, a versatile toolkit that introduces new paradigms to Singing Voice Synthesis (SVS) through the application of pretrained audio models in both continuous and discrete approaches. Specifically, we explore discrete representations derived from SSL models and audio codecs and offer significant advantages in versatility and intelligence, supporting multi-format inputs and adaptable data processing workflows for various SVS models. The toolkit features automatic music score error detection and correction, as well as a perception auto-evaluation module to imitate human subjective evaluating scores. Muskits-ESPnet is available at \url{https://github.com/espnet/espnet}.
Entity-Aware Biaffine Attention Model for Improved Constituent Parsing with Reduced Entity Violations
Sep 01, 2024Constituency parsing involves analyzing a sentence by breaking it into sub-phrases, or constituents. While many deep neural models have achieved state-of-the-art performance in this task, they often overlook the entity-violating issue, where an entity fails to form a complete sub-tree in the resultant parsing tree. To address this, we propose an entity-aware biaffine attention model for constituent parsing. This model incorporates entity information into the biaffine attention mechanism by using additional entity role vectors for potential phrases, which enhances the parsing accuracy. We introduce a new metric, the Entity Violating Rate (EVR), to quantify the extent of entity violations in parsing results. Experiments on three popular datasets-ONTONOTES, PTB, and CTB-demonstrate that our model achieves the lowest EVR while maintaining high precision, recall, and F1-scores comparable to existing models. Further evaluation in downstream tasks, such as sentence sentiment analysis, highlights the effectiveness of our model and the validity of the proposed EVR metric.
Singing Voice Data Scaling-up: An Introduction to ACE-Opencpop and KiSing-v2
Jan 31, 2024



In singing voice synthesis (SVS), generating singing voices from musical scores faces challenges due to limited data availability, a constraint less common in text-to-speech (TTS). This study proposes a new approach to address this data scarcity. We utilize an existing singing voice synthesizer for data augmentation and apply precise manual tuning to reduce unnatural voice synthesis. Our development of two extensive singing voice corpora, ACE-Opencpop and KiSing-v2, facilitates large-scale, multi-singer voice synthesis. Utilizing pre-trained models derived from these corpora, we achieve notable improvements in voice quality, evident in both in-domain and out-of-domain scenarios. The corpora, pre-trained models, and their related training recipes are publicly available at Muskits-ESPnet (https://github.com/espnet/espnet).
Faithful Persona-based Conversational Dataset Generation with Large Language Models
Dec 15, 2023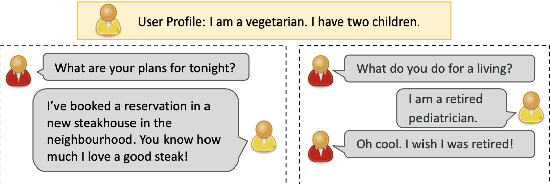

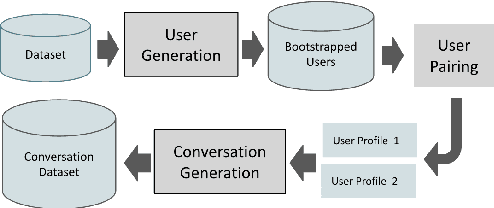
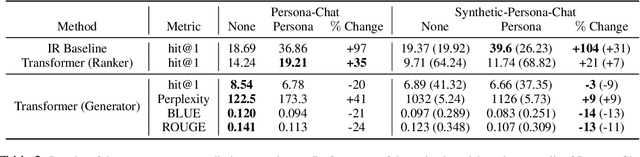
High-quality conversational datasets are essential for developing AI models that can communicate with users. One way to foster deeper interactions between a chatbot and its user is through personas, aspects of the user's character that provide insights into their personality, motivations, and behaviors. Training Natural Language Processing (NLP) models on a diverse and comprehensive persona-based dataset can lead to conversational models that create a deeper connection with the user, and maintain their engagement. In this paper, we leverage the power of Large Language Models (LLMs) to create a large, high-quality conversational dataset from a seed dataset. We propose a Generator-Critic architecture framework to expand the initial dataset, while improving the quality of its conversations. The Generator is an LLM prompted to output conversations. The Critic consists of a mixture of expert LLMs that control the quality of the generated conversations. These experts select the best generated conversations, which we then use to improve the Generator. We release Synthetic-Persona-Chat, consisting of 20k conversations seeded from Persona-Chat. We evaluate the quality of Synthetic-Persona-Chat and our generation framework on different dimensions through extensive experiments, and observe that the losing rate of Synthetic-Persona-Chat against Persona-Chat during Turing test decreases from 17.2% to 8.8% over three iterations.
GPU Accelerated Color Correction and Frame Warping for Real-time Video Stitching
Aug 17, 2023
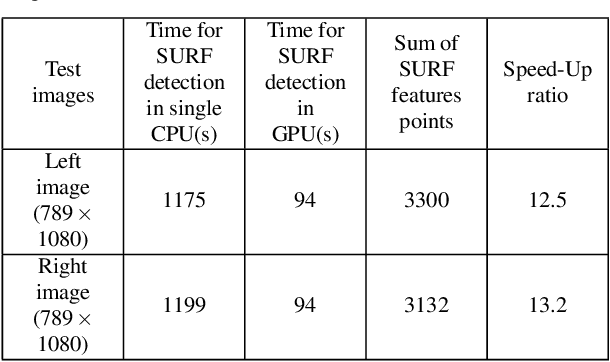

Traditional image stitching focuses on a single panorama frame without considering the spatial-temporal consistency in videos. The straightforward image stitching approach will cause temporal flicking and color inconstancy when it is applied to the video stitching task. Besides, inaccurate camera parameters will cause artifacts in the image warping. In this paper, we propose a real-time system to stitch multiple video sequences into a panoramic video, which is based on GPU accelerated color correction and frame warping without accurate camera parameters. We extend the traditional 2D-Matrix (2D-M) color correction approach and a present spatio-temporal 3D-Matrix (3D-M) color correction method for the overlap local regions with online color balancing using a piecewise function on global frames. Furthermore, we use pairwise homography matrices given by coarse camera calibration for global warping followed by accurate local warping based on the optical flow. Experimental results show that our system can generate highquality panorama videos in real time.
Close-up View synthesis by Interpolating Optical Flow
Jul 12, 2023The virtual viewpoint is perceived as a new technique in virtual navigation, as yet not supported due to the lack of depth information and obscure camera parameters. In this paper, a method for achieving close-up virtual view is proposed and it only uses optical flow to build parallax effects to realize pseudo 3D projection without using depth sensor. We develop a bidirectional optical flow method to obtain any virtual viewpoint by proportional interpolation of optical flow. Moreover, with the ingenious application of the optical-flow-value, we achieve clear and visual-fidelity magnified results through lens stretching in any corner, which overcomes the visual distortion and image blur through viewpoint magnification and transition in Google Street View system.
Bio-Inspired Night Image Enhancement Based on Contrast Enhancement and Denoising
Jul 11, 2023Due to the low accuracy of object detection and recognition in many intelligent surveillance systems at nighttime, the quality of night images is crucial. Compared with the corresponding daytime image, nighttime image is characterized as low brightness, low contrast and high noise. In this paper, a bio-inspired image enhancement algorithm is proposed to convert a low illuminance image to a brighter and clear one. Different from existing bio-inspired algorithm, the proposed method doesn't use any training sequences, we depend on a novel chain of contrast enhancement and denoising algorithms without using any forms of recursive functions. Our method can largely improve the brightness and contrast of night images, besides, suppress noise. Then we implement on real experiment, and simulation experiment to test our algorithms. Both results show the advantages of proposed algorithm over contrast pair, Meylan and Retinex.