 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMs are Overconfident: Evaluating Confidence Interval Calibration with FermiEval
Oct 30, 2025Large language models (LLMs) excel at numerical estimation but struggle to correctly quantify uncertainty. We study how well LLMs construct confidence intervals around their own answers and find that they are systematically overconfident. To evaluate this behavior, we introduce FermiEval, a benchmark of Fermi-style estimation questions with a rigorous scoring rule for confidence interval coverage and sharpness. Across several modern models, nominal 99\% intervals cover the true answer only 65\% of the time on average. With a conformal prediction based approach that adjusts the intervals, we obtain accurate 99\% observed coverage, and the Winkler interval score decreases by 54\%. We also propose direct log-probability elicitation and quantile adjustment methods, which further reduce overconfidence at high confidence levels. Finally, we develop a perception-tunnel theory explaining why LLMs exhibit overconfidence: when reasoning under uncertainty, they act as if sampling from a truncated region of their inferred distribution, neglecting its tails.
A Set-Sequence Model for Time Series
May 16, 2025In many financial prediction problems, the behavior of individual units (such as loans, bonds, or stocks) is influenced by observable unit-level factors and macroeconomic variables, as well as by latent cross-sectional effects. Traditional approaches attempt to capture these latent effects via handcrafted summary features. We propose a Set-Sequence model that eliminates the need for handcrafted features. The Set model first learns a shared cross-sectional summary at each period. The Sequence model then ingests the summary-augmented time series for each unit independently to predict its outcome. Both components are learned jointly over arbitrary sets sampled during training. Our approach harnesses the set nature of the cross-section and is computationally efficient, generating set summaries in linear time relative to the number of units. It is also flexible, allowing the use of existing sequence models and accommodating a variable number of units at inference. Empirical evaluations demonstrate that our Set-Sequence model significantly outperforms benchmarks on stock return prediction and mortgage behavior tasks. Code will be released.
Score-Debiased Kernel Density Estimation
Apr 27, 2025
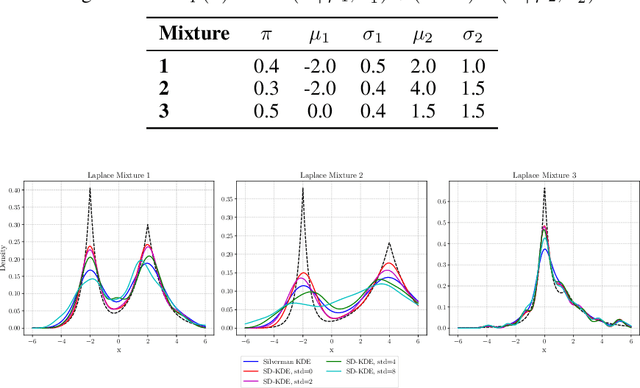
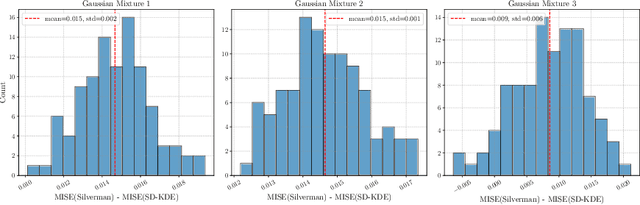

We propose a novel method for density estimation that leverages an estimated score function to debias kernel density estimation (SD-KDE). In our approach, each data point is adjusted by taking a single step along the score function with a specific choice of step size, followed by standard KDE with a modified bandwidth. The step size and modified bandwidth are chosen to remove the leading order bias in the KDE. Our experiments on synthetic tasks in 1D, 2D and on MNIST, demonstrate that our proposed SD-KDE method significantly reduces the mean integrated squared error compared to the standard Silverman KDE, even with noisy estimates in the score function. These results underscore the potential of integrating score-based corrections into nonparametric density estimation.
MMMT-IF: A Challenging Multimodal Multi-Turn Instruction Following Benchmark
Sep 26, 2024



Evaluating instruction following capabilities for multimodal, multi-turn dialogue is challenging. With potentially multiple instructions in the input model context, the task is time-consuming for human raters and we show LLM based judges are biased towards answers from the same model. We propose MMMT-IF, an image based multi-turn Q$\&$A evaluation set with added global instructions between questions, constraining the answer format. This challenges models to retrieve instructions dispersed across long dialogues and reason under instruction constraints. All instructions are objectively verifiable through code execution. We introduce the Programmatic Instruction Following ($\operatorname{PIF}$) metric to measure the fraction of the instructions that are correctly followed while performing a reasoning task. The $\operatorname{PIF-N-K}$ set of metrics further evaluates robustness by measuring the fraction of samples in a corpus where, for each sample, at least K out of N generated model responses achieve a $\operatorname{PIF}$ score of one. The $\operatorname{PIF}$ metric aligns with human instruction following ratings, showing 60 percent correlation. Experiments show Gemini 1.5 Pro, GPT-4o, and Claude 3.5 Sonnet, have a $\operatorname{PIF}$ metric that drops from 0.81 on average at turn 1 across the models, to 0.64 at turn 20. Across all turns, when each response is repeated 4 times ($\operatorname{PIF-4-4}$), GPT-4o and Gemini successfully follow all instructions only $11\%$ of the time. When all the instructions are also appended to the end of the model input context, the $\operatorname{PIF}$ metric improves by 22.3 points on average, showing that the challenge with the task lies not only in following the instructions, but also in retrieving the instructions spread out in the model context. We plan to open source the MMMT-IF dataset and metric computation code.
Simple Hardware-Efficient Long Convolutions for Sequence Modeling
Feb 13, 2023State space models (SSMs) have high performance on long sequence modeling but require sophisticated initialization techniques and specialized implementations for high quality and runtime performance. We study whether a simple alternative can match SSMs in performance and efficiency: directly learning long convolutions over the sequence. We find that a key requirement to achieving high performance is keeping the convolution kernels smooth. We find that simple interventions--such as squashing the kernel weights--result in smooth kernels and recover SSM performance on a range of tasks including the long range arena, image classification, language modeling, and brain data modeling. Next, we develop FlashButterfly, an IO-aware algorithm to improve the runtime performance of long convolutions. FlashButterfly appeals to classic Butterfly decompositions of the convolution to reduce GPU memory IO and increase FLOP utilization. FlashButterfly speeds up convolutions by 2.2$\times$, and allows us to train on Path256, a challenging task with sequence length 64K, where we set state-of-the-art by 29.1 points while training 7.2$\times$ faster than prior work. Lastly, we introduce an extension to FlashButterfly that learns the coefficients of the Butterfly decomposition, increasing expressivity without increasing runtime. Using this extension, we outperform a Transformer on WikiText103 by 0.2 PPL with 30% fewer parameters.