 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the Behaviors of Environment-aware Information Retrieval
Jun 15, 2026Recent retrieval-augmented generation (RAG) approaches have demonstrated strong capability in handling complex queries, yet current research overlooks a critical challenge: different retrievers require fundamentally different query formulation strategies for optimal performance. In this work, we present the first systematic analysis of how LLMs can learn to adapt their query formulation strategies for different retrievers via reinforcement learning (RL). Our empirical study reveals that RL effectively teaches an LLM to tailor its queries to specific retriever characteristics. We discover that different retrievers exhibit surprisingly distinct optimal query styles (e.g., descriptive vs. question-like), suggesting strategies learned for one retriever ineffective for another. We further show that performance can be enhanced by incorporating retriever-specific human guidance and by scaling model size. To facilitate learning over multi-retrieval-step trajectories, we introduce a branching-based rollout technique that improves training stability. Our work provides the first empirical evidence and actionable insights for building truly retriever-aware RAG systems. Code and resources are available at https://github.com/LCO-Embedding/Envs-aware-Information-Retrieval.
Dynamic Skill Lifecycle Management for Agentic Reinforcement Learning
May 11, 2026Large language model agents increasingly rely on external skills to solve complex tasks, where skills act as modular units that extend their capabilities beyond what parametric memory alone supports. Existing methods assume external skills either accumulate as persistent guidance or internalized into the policy, eventually leading to zero-skill inference. We argue this assumption is overly restrictive, since with limited parametric capacity and uneven marginal contribution across skills, the optimal active skill set is non-monotonic, task- and stage-dependent. In this work, we propose SLIM, a framework of dynamic Skill LIfecycle Management for agentic reinforcement learning (RL), which treats the active external skill set as a dynamic optimization variable jointly updated with policy learning. Specifically, SLIM estimates each active skill's marginal external contribution through leave-one-skill-out validation, then applies three lifecycle operations: retaining high-value skills, retiring skills whose contribution becomes negligible after sufficient exposure, and expanding the skill bank when persistent failures reveal missing capability coverage. Experiments show that SLIM outperforms the best baselines by an average of 7.1% points across ALFWorld and SearchQA. Results further indicate that policy learning and external skill retention are not mutually exclusive: some skills are absorbed into the policy, while others continue to provide external value, supporting SLIM as a more general paradigm for skill-based agentic RL.
UniPool: A Globally Shared Expert Pool for Mixture-of-Experts
May 07, 2026Modern Mixture-of-Experts (MoE) architectures allocate expert capacity through a rigid per-layer rule: each transformer layer owns a separate expert set. This convention couples depth scaling with linear expert-parameter growth and assumes that every layer needs isolated expert capacity. However, recent analyses and our routing probe challenge this allocation rule: replacing a deeper layer's learned top-k router with uniform random routing drops downstream accuracy by only 1.0-1.6 points across multiple production MoE models. Motivated by this redundancy, we propose UniPool, an MoE architecture that treats expert capacity as a global architectural budget by replacing per-layer expert ownership with a single shared pool accessed by independent per-layer routers. To enable stable and balanced training under sharing, we introduce a pool-level auxiliary loss that balances expert utilization across the entire pool, and adopt NormRouter to provide sparse and scale-stable routing into the shared expert pool. Across five LLaMA-architecture model scales (182M, 469M, 650M, 830M, and 978M parameters) trained on 30B tokens from the Pile, UniPool consistently improves validation loss and perplexity over the matched vanilla MoE baselines. Across these scales, UniPool reduces validation loss by up to 0.0386 relative to vanilla MoE. Beyond raw loss improvement, our results identify pool size as an explicit depth-scaling hyperparameter: reduced-pool UniPool variants using only 41.6%-66.7% of the vanilla expert-parameter budget match or outperform layer-wise MoE at the tested scales. This shows that, under a shared-pool design, expert parameters need not grow linearly with depth; they can grow sublinearly while remaining more efficient and effective than vanilla MoE. Further analysis shows that UniPool's benefits compose with finer-grained expert decomposition.
Lingshu-Cell: A generative cellular world model for transcriptome modeling toward virtual cells
Mar 26, 2026Modeling cellular states and predicting their responses to perturbations are central challenges in computational biology and the development of virtual cells. Existing foundation models for single-cell transcriptomics provide powerful static representations, but they do not explicitly model the distribution of cellular states for generative simulation. Here, we introduce Lingshu-Cell, a masked discrete diffusion model that learns transcriptomic state distributions and supports conditional simulation under perturbation. By operating directly in a discrete token space that is compatible with the sparse, non-sequential nature of single-cell transcriptomic data, Lingshu-Cell captures complex transcriptome-wide expression dependencies across approximately 18,000 genes without relying on prior gene selection, such as filtering by high variability or ranking by expression level. Across diverse tissues and species, Lingshu-Cell accurately reproduces transcriptomic distributions, marker-gene expression patterns and cell-subtype proportions, demonstrating its ability to capture complex cellular heterogeneity. Moreover, by jointly embedding cell type or donor identity with perturbation, Lingshu-Cell can predict whole-transcriptome expression changes for novel combinations of identity and perturbation. It achieves leading performance on the Virtual Cell Challenge H1 genetic perturbation benchmark and in predicting cytokine-induced responses in human PBMCs. Together, these results establish Lingshu-Cell as a flexible cellular world model for in silico simulation of cell states and perturbation responses, laying the foundation for a new paradigm in biological discovery and perturbation screening.
Demystifying Reinforcement Learning for Long-Horizon Tool-Using Agents: A Comprehensive Recipe
Mar 23, 2026Reinforcement Learning (RL) is essential for evolving Large Language Models (LLMs) into autonomous agents capable of long-horizon planning, yet a practical recipe for scaling RL in complex, multi-turn environments remains elusive. This paper presents a systematic empirical study using TravelPlanner, a challenging testbed requiring tool orchestration to satisfy multifaceted constraints. We decompose the agentic RL design space along 5 axes: reward shaping, model scaling, data composition, algorithm selection, and environmental stability. Our controlled experiments yield 7 key takeaways, e.g., (1) reward and algorithm choices are scale-dependent as smaller models benefit from staged rewards and enhanced exploration, whereas larger models converge efficiently with simpler dense rewards, (2) ~ 1K training samples with a balanced difficulty mixture mark a sweet spot for both in-domain and out-of-domain performance, and (3) environmental stability is critical to prevent policy degradation. Based on our distilled recipe, our RL-trained models achieve state-of-the-art performance on TravelPlanner, significantly outperforming leading LLMs.
AGCD: Agent-Guided Cross-Modal Decoding for Weather Forecasting
Mar 16, 2026Accurate weather forecasting is more than grid-wise regression: it must preserve coherent synoptic structures and physical consistency of meteorological fields, especially under autoregressive rollouts where small one-step errors can amplify into structural bias. Existing physics-priors approaches typically impose global, once-for-all constraints via architectures, regularization, or NWP coupling, offering limited state-adaptive and sample-specific controllability at deployment. To bridge this gap, we propose Agent-Guided Cross-modal Decoding (AGCD), a plug-and-play decoding-time prior-injection paradigm that derives state-conditioned physics-priors from the current multivariate atmosphere and injects them into forecasters in a controllable and reusable way. Specifically, We design a multi-agent meteorological narration pipeline to generate state-conditioned physics-priors, utilizing MLLMs to extract various meteorological elements effectively. To effectively apply the priors, AGCD further introduce cross-modal region interaction decoding that performs region-aware multi-scale tokenization and efficient physics-priors injection to refine visual features without changing the backbone interface. Experiments on WeatherBench demonstrate consistent gains for 6-hour forecasting across two resolutions (5.625 degree and 1.40625 degree) and diverse backbones (generic and weather-specialized), including strictly causal 48-hour autoregressive rollouts that reduce early-stage error accumulation and improve long-horizon stability.
IBCircuit: Towards Holistic Circuit Discovery with Information Bottleneck
Feb 26, 2026Circuit discovery has recently attracted attention as a potential research direction to explain the non-trivial behaviors of language models. It aims to find the computational subgraphs, also known as circuits, within the model that are responsible for solving specific tasks. However, most existing studies overlook the holistic nature of these circuits and require designing specific corrupted activations for different tasks, which is inaccurate and inefficient. In this work, we propose an end-to-end approach based on the principle of Information Bottleneck, called IBCircuit, to identify informative circuits holistically. IBCircuit is an optimization framework for holistic circuit discovery and can be applied to any given task without tediously corrupted activation design. In both the Indirect Object Identification (IOI) and Greater-Than tasks, IBCircuit identifies more faithful and minimal circuits in terms of critical node components and edge components compared to recent related work.
ParaFormer: A Generalized PageRank Graph Transformer for Graph Representation Learning
Dec 16, 2025Graph Transformers (GTs) have emerged as a promising graph learning tool, leveraging their all-pair connected property to effectively capture global information. To address the over-smoothing problem in deep GNNs, global attention was initially introduced, eliminating the necessity for using deep GNNs. However, through empirical and theoretical analysis, we verify that the introduced global attention exhibits severe over-smoothing, causing node representations to become indistinguishable due to its inherent low-pass filtering. This effect is even stronger than that observed in GNNs. To mitigate this, we propose PageRank Transformer (ParaFormer), which features a PageRank-enhanced attention module designed to mimic the behavior of deep Transformers. We theoretically and empirically demonstrate that ParaFormer mitigates over-smoothing by functioning as an adaptive-pass filter. Experiments show that ParaFormer achieves consistent performance improvements across both node classification and graph classification tasks on 11 datasets ranging from thousands to millions of nodes, validating its efficacy. The supplementary material, including code and appendix, can be found in https://github.com/chaohaoyuan/ParaFormer.
Task-Adaptive Parameter-Efficient Fine-Tuning for Weather Foundation Models
Sep 26, 2025While recent advances in machine learning have equipped Weather Foundation Models (WFMs) with substantial generalization capabilities across diverse downstream tasks, the escalating computational requirements associated with their expanding scale increasingly hinder practical deployment. Current Parameter-Efficient Fine-Tuning (PEFT) methods, designed for vision or language tasks, fail to address the unique challenges of weather downstream tasks, such as variable heterogeneity, resolution diversity, and spatiotemporal coverage variations, leading to suboptimal performance when applied to WFMs. To bridge this gap, we introduce WeatherPEFT, a novel PEFT framework for WFMs incorporating two synergistic innovations. First, during the forward pass, Task-Adaptive Dynamic Prompting (TADP) dynamically injects the embedding weights within the encoder to the input tokens of the pre-trained backbone via internal and external pattern extraction, enabling context-aware feature recalibration for specific downstream tasks. Furthermore, during backpropagation, Stochastic Fisher-Guided Adaptive Selection (SFAS) not only leverages Fisher information to identify and update the most task-critical parameters, thereby preserving invariant pre-trained knowledge, but also introduces randomness to stabilize the selection. We demonstrate the effectiveness and efficiency of WeatherPEFT on three downstream tasks, where existing PEFT methods show significant gaps versus Full-Tuning, and WeatherPEFT achieves performance parity with Full-Tuning using fewer trainable parameters. The code of this work will be released.
ReSum: Unlocking Long-Horizon Search Intelligence via Context Summarization
Sep 16, 2025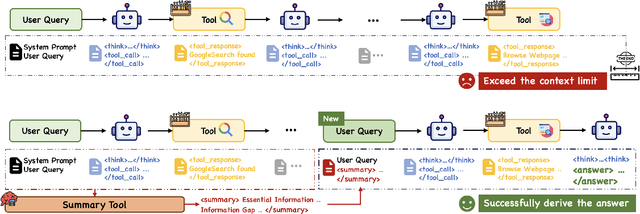
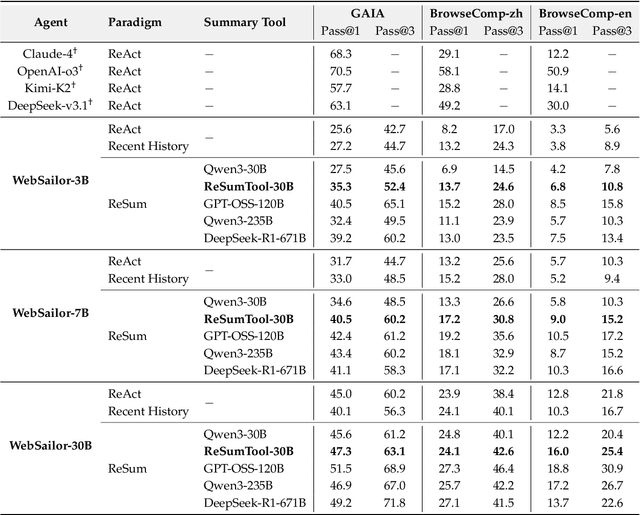
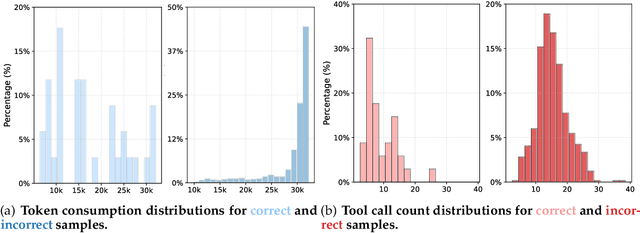
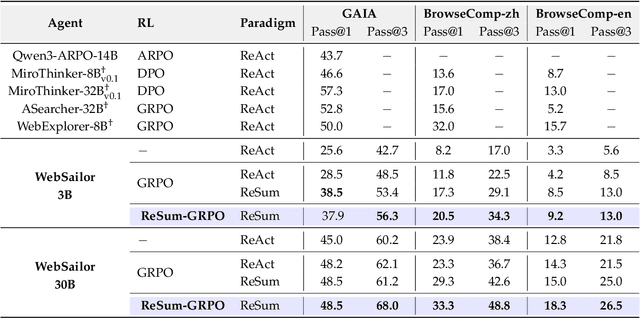
Large Language Model (LLM)-based web agents demonstrate strong performance on knowledge-intensive tasks but are hindered by context window limitations in paradigms like ReAct. Complex queries involving multiple entities, intertwined relationships, and high uncertainty demand extensive search cycles that rapidly exhaust context budgets before reaching complete solutions. To overcome this challenge, we introduce ReSum, a novel paradigm that enables indefinite exploration through periodic context summarization. ReSum converts growing interaction histories into compact reasoning states, maintaining awareness of prior discoveries while bypassing context constraints. For paradigm adaptation, we propose ReSum-GRPO, integrating GRPO with segmented trajectory training and advantage broadcasting to familiarize agents with summary-conditioned reasoning. Extensive experiments on web agents of varying scales across three benchmarks demonstrate that ReSum delivers an average absolute improvement of 4.5\% over ReAct, with further gains of up to 8.2\% following ReSum-GRPO training. Notably, with only 1K training samples, our WebResummer-30B (a ReSum-GRPO-trained version of WebSailor-30B) achieves 33.3\% Pass@1 on BrowseComp-zh and 18.3\% on BrowseComp-en, surpassing existing open-source web agents.