 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes Graph Prompt Work? A Data Operation Perspective with Theoretical Analysis
Paper and Code
Oct 02, 2024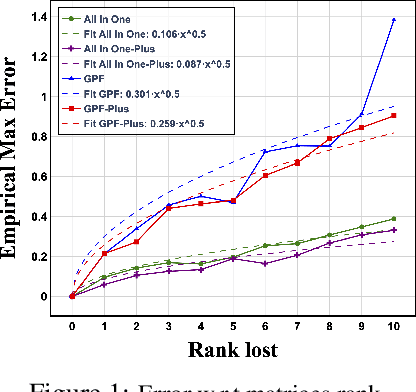
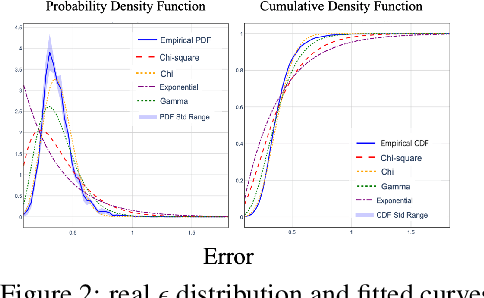


In recent years, graph prompting has emerged as a promising research direction, enabling the learning of additional tokens or subgraphs appended to the original graphs without requiring retraining of pre-trained graph models across various applications. This novel paradigm, shifting from the traditional pretraining and finetuning to pretraining and prompting has shown significant empirical success in simulating graph data operations, with applications ranging from recommendation systems to biological networks and graph transferring. However, despite its potential, the theoretical underpinnings of graph prompting remain underexplored, raising critical questions about its fundamental effectiveness. The lack of rigorous theoretical proof of why and how much it works is more like a dark cloud over the graph prompt area to go further. To fill this gap, this paper introduces a theoretical framework that rigorously analyzes graph prompting from a data operation perspective. Our contributions are threefold: First, we provide a formal guarantee theorem, demonstrating graph prompts capacity to approximate graph transformation operators, effectively linking upstream and downstream tasks. Second, we derive upper bounds on the error of these data operations by graph prompts for a single graph and extend this discussion to batches of graphs, which are common in graph model training. Third, we analyze the distribution of data operation errors, extending our theoretical findings from linear graph models (e.g., GCN) to non-linear graph models (e.g., GAT). Extensive experiments support our theoretical results and confirm the practical implications of these guarantees.