 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic Fusion of Large Atomic and Language Models to Accelerate Materials Discovery
Apr 26, 2026The discovery of novel materials is critical for global energy and quantum technology transitions. While deep learning has fundamentally reshaped this landscape, existing predictive or generative models typically operate in isolation, lacking the autonomous orchestration required to execute the full discovery process. Here we present ElementsClaw, an agentic framework for materials discovery that synergizes Large Atomic Models (LAMs) with Large Language Models (LLMs). In response to varied human requirements, ElementsClaw dynamically orchestrates a suite of LAM tools finetuned from our proposed model Elements for atomic-scale numerical computation, while leveraging LLMs for high-level semantic reasoning. This shift moves AI-driven materials science from isolated processes toward integrated and human interactive discovery. In the demanding domain of superconductors, our agentic system guides the experimental synthesis of four new superconductors, including Zr3ScRe8 with a transition temperature of 6.8 K and HfZrRe4 at 6.7 K. At scale, ElementsClaw screens more than 2.4 million stable crystals within only 28 GPU hours, identifying 68,000 high-confidence superconducting candidates and vastly expanding the known superconducting space. These results demonstrate how our agent accelerates materials discovery with high physical fidelity.
Lingshu-Cell: A generative cellular world model for transcriptome modeling toward virtual cells
Mar 26, 2026Modeling cellular states and predicting their responses to perturbations are central challenges in computational biology and the development of virtual cells. Existing foundation models for single-cell transcriptomics provide powerful static representations, but they do not explicitly model the distribution of cellular states for generative simulation. Here, we introduce Lingshu-Cell, a masked discrete diffusion model that learns transcriptomic state distributions and supports conditional simulation under perturbation. By operating directly in a discrete token space that is compatible with the sparse, non-sequential nature of single-cell transcriptomic data, Lingshu-Cell captures complex transcriptome-wide expression dependencies across approximately 18,000 genes without relying on prior gene selection, such as filtering by high variability or ranking by expression level. Across diverse tissues and species, Lingshu-Cell accurately reproduces transcriptomic distributions, marker-gene expression patterns and cell-subtype proportions, demonstrating its ability to capture complex cellular heterogeneity. Moreover, by jointly embedding cell type or donor identity with perturbation, Lingshu-Cell can predict whole-transcriptome expression changes for novel combinations of identity and perturbation. It achieves leading performance on the Virtual Cell Challenge H1 genetic perturbation benchmark and in predicting cytokine-induced responses in human PBMCs. Together, these results establish Lingshu-Cell as a flexible cellular world model for in silico simulation of cell states and perturbation responses, laying the foundation for a new paradigm in biological discovery and perturbation screening.
IBCircuit: Towards Holistic Circuit Discovery with Information Bottleneck
Feb 26, 2026Circuit discovery has recently attracted attention as a potential research direction to explain the non-trivial behaviors of language models. It aims to find the computational subgraphs, also known as circuits, within the model that are responsible for solving specific tasks. However, most existing studies overlook the holistic nature of these circuits and require designing specific corrupted activations for different tasks, which is inaccurate and inefficient. In this work, we propose an end-to-end approach based on the principle of Information Bottleneck, called IBCircuit, to identify informative circuits holistically. IBCircuit is an optimization framework for holistic circuit discovery and can be applied to any given task without tediously corrupted activation design. In both the Indirect Object Identification (IOI) and Greater-Than tasks, IBCircuit identifies more faithful and minimal circuits in terms of critical node components and edge components compared to recent related work.
Natural Language-Assisted Multi-modal Medication Recommendation
Jan 13, 2025Combinatorial medication recommendation(CMR) is a fundamental task of healthcare, which offers opportunities for clinical physicians to provide more precise prescriptions for patients with intricate health conditions, particularly in the scenarios of long-term medical care. Previous research efforts have sought to extract meaningful information from electronic health records (EHRs) to facilitate combinatorial medication recommendations. Existing learning-based approaches further consider the chemical structures of medications, but ignore the textual medication descriptions in which the functionalities are clearly described. Furthermore, the textual knowledge derived from the EHRs of patients remains largely underutilized. To address these issues, we introduce the Natural Language-Assisted Multi-modal Medication Recommendation(NLA-MMR), a multi-modal alignment framework designed to learn knowledge from the patient view and medication view jointly. Specifically, NLA-MMR formulates CMR as an alignment problem from patient and medication modalities. In this vein, we employ pretrained language models(PLMs) to extract in-domain knowledge regarding patients and medications, serving as the foundational representation for both modalities. In the medication modality, we exploit both chemical structures and textual descriptions to create medication representations. In the patient modality, we generate the patient representations based on textual descriptions of diagnosis, procedure, and symptom. Extensive experiments conducted on three publicly accessible datasets demonstrate that NLA-MMR achieves new state-of-the-art performance, with a notable average improvement of 4.72% in Jaccard score. Our source code is publicly available on https://github.com/jtan1102/NLA-MMR_CIKM_2024.
* 10 pages
Language Agents for Detecting Implicit Stereotypes in Text-to-image Models at Scale
Nov 02, 2023



The recent surge in the research of diffusion models has accelerated the adoption of text-to-image models in various Artificial Intelligence Generated Content (AIGC) commercial products. While these exceptional AIGC products are gaining increasing recognition and sparking enthusiasm among consumers, the questions regarding whether, when, and how these models might unintentionally reinforce existing societal stereotypes remain largely unaddressed. Motivated by recent advancements in language agents, here we introduce a novel agent architecture tailored for stereotype detection in text-to-image models. This versatile agent architecture is capable of accommodating free-form detection tasks and can autonomously invoke various tools to facilitate the entire process, from generating corresponding instructions and images, to detecting stereotypes. We build the stereotype-relevant benchmark based on multiple open-text datasets, and apply this architecture to commercial products and popular open source text-to-image models. We find that these models often display serious stereotypes when it comes to certain prompts about personal characteristics, social cultural context and crime-related aspects. In summary, these empirical findings underscore the pervasive existence of stereotypes across social dimensions, including gender, race, and religion, which not only validate the effectiveness of our proposed approach, but also emphasize the critical necessity of addressing potential ethical risks in the burgeoning realm of AIGC. As AIGC continues its rapid expansion trajectory, with new models and plugins emerging daily in staggering numbers, the challenge lies in the timely detection and mitigation of potential biases within these models.
Decision Support System for Chronic Diseases Based on Drug-Drug Interactions
Mar 04, 2023



Many patients with chronic diseases resort to multiple medications to relieve various symptoms, which raises concerns about the safety of multiple medication use, as severe drug-drug antagonism can lead to serious adverse effects or even death. This paper presents a Decision Support System, called DSSDDI, based on drug-drug interactions to support doctors prescribing decisions. DSSDDI contains three modules, Drug-Drug Interaction (DDI) module, Medical Decision (MD) module and Medical Support (MS) module. The DDI module learns safer and more effective drug representations from the drug-drug interactions. To capture the potential causal relationship between DDI and medication use, the MD module considers the representations of patients and drugs as context, DDI and patients' similarity as treatment, and medication use as outcome to construct counterfactual links for the representation learning. Furthermore, the MS module provides drug candidates to doctors with explanations. Experiments on the chronic data collected from the Hong Kong Chronic Disease Study Project and a public diagnostic data MIMIC-III demonstrate that DSSDDI can be a reliable reference for doctors in terms of safety and efficiency of clinical diagnosis, with significant improvements compared to baseline methods.
Revisiting Adversarial Attacks on Graph Neural Networks for Graph Classification
Aug 13, 2022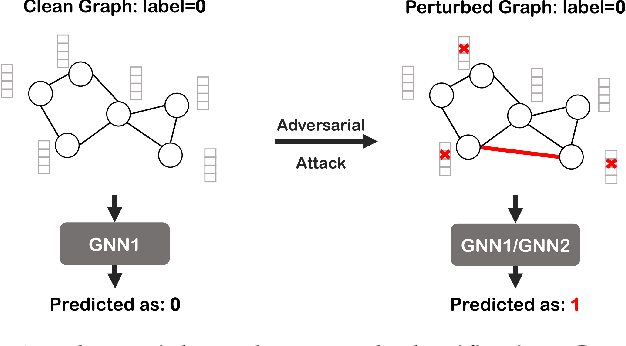
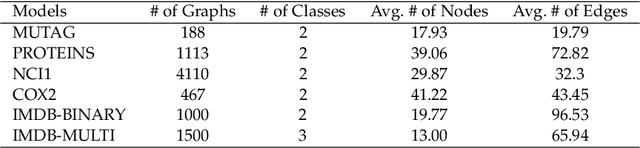
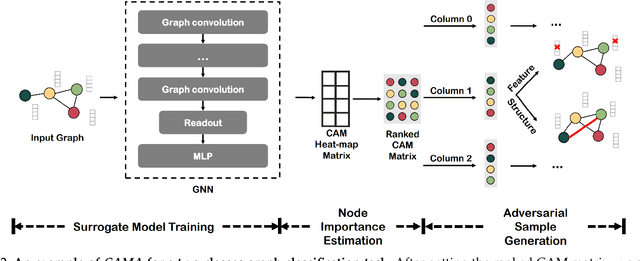
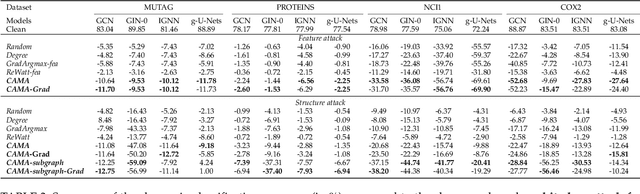
Graph neural networks (GNNs) have achieved tremendous success in the task of graph classification and diverse downstream real-world applications. Despite their success, existing approaches are either limited to structure attacks or restricted to local information. This calls for a more general attack framework on graph classification, which faces significant challenges due to the complexity of generating local-node-level adversarial examples using the global-graph-level information. To address this "global-to-local" problem, we present a general framework CAMA to generate adversarial examples by manipulating graph structure and node features in a hierarchical style. Specifically, we make use of Graph Class Activation Mapping and its variant to produce node-level importance corresponding to the graph classification task. Then through a heuristic design of algorithms, we can perform both feature and structure attacks under unnoticeable perturbation budgets with the help of both node-level and subgraph-level importance. Experiments towards attacking four state-of-the-art graph classification models on six real-world benchmarks verify the flexibility and effectiveness of our framework.
PI-GNN: A Novel Perspective on Semi-Supervised Node Classification against Noisy Labels
Jun 14, 2021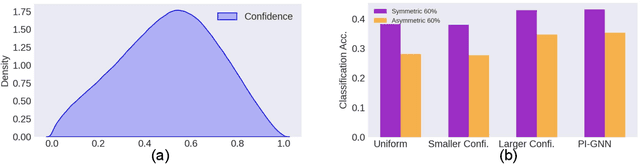

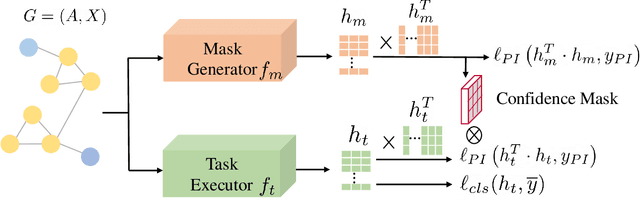
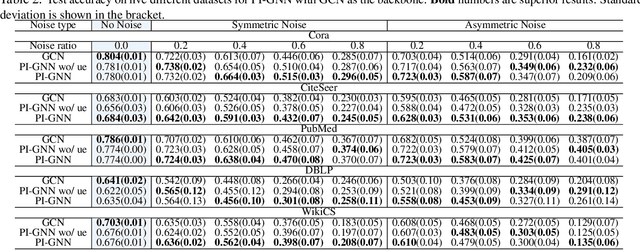
Semi-supervised node classification, as a fundamental problem in graph learning, leverages unlabeled nodes along with a small portion of labeled nodes for training. Existing methods rely heavily on high-quality labels, which, however, are expensive to obtain in real-world applications since certain noises are inevitably involved during the labeling process. It hence poses an unavoidable challenge for the learning algorithm to generalize well. In this paper, we propose a novel robust learning objective dubbed pairwise interactions (PI) for the model, such as Graph Neural Network (GNN) to combat noisy labels. Unlike classic robust training approaches that operate on the pointwise interactions between node and class label pairs, PI explicitly forces the embeddings for node pairs that hold a positive PI label to be close to each other, which can be applied to both labeled and unlabeled nodes. We design several instantiations for PI labels based on the graph structure and the node class labels, and further propose a new uncertainty-aware training technique to mitigate the negative effect of the sub-optimal PI labels. Extensive experiments on different datasets and GNN architectures demonstrate the effectiveness of PI, yielding a promising improvement over the state-of-the-art methods.
Inverse Graph Identification: Can We Identify Node Labels Given Graph Labels?
Jul 12, 2020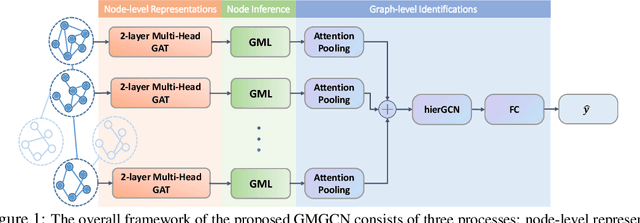
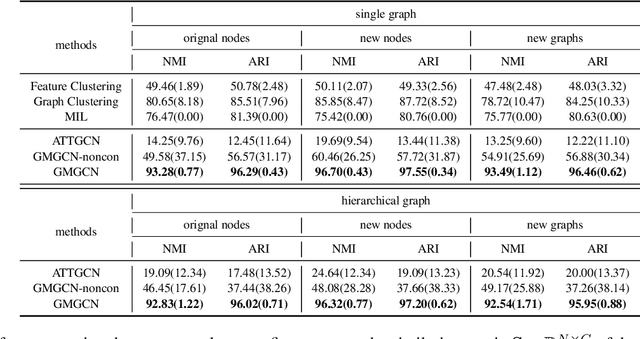

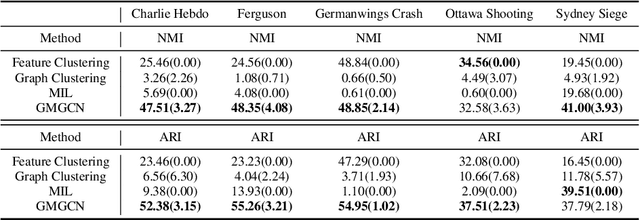
Graph Identification (GI) has long been researched in graph learning and is essential in certain applications (e.g. social community detection). Specifically, GI requires to predict the label/score of a target graph given its collection of node features and edge connections. While this task is common, more complex cases arise in practice---we are supposed to do the inverse thing by, for example, grouping similar users in a social network given the labels of different communities. This triggers an interesting thought: can we identify nodes given the labels of the graphs they belong to? Therefore, this paper defines a novel problem dubbed Inverse Graph Identification (IGI), as opposed to GI. Upon a formal discussion of the variants of IGI, we choose a particular case study of node clustering by making use of the graph labels and node features, with an assistance of a hierarchical graph that further characterizes the connections between different graphs. To address this task, we propose Gaussian Mixture Graph Convolutional Network (GMGCN), a simple yet effective method that makes the node-level message passing process using Graph Attention Network (GAT) under the protocol of GI and then infers the category of each node via a Gaussian Mixture Layer (GML). The training of GMGCN is further boosted by a proposed consensus loss to take advantage of the structure of the hierarchical graph. Extensive experiments are conducted to test the rationality of the formulation of IGI. We verify the superiority of the proposed method compared to other baselines on several benchmarks we have built up. We will release our codes along with the benchmark data to facilitate more research attention to the IGI problem.
Rumor Detection on Social Media with Bi-Directional Graph Convolutional Networks
Jan 17, 2020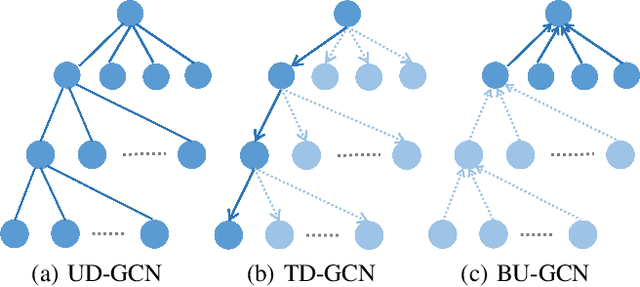
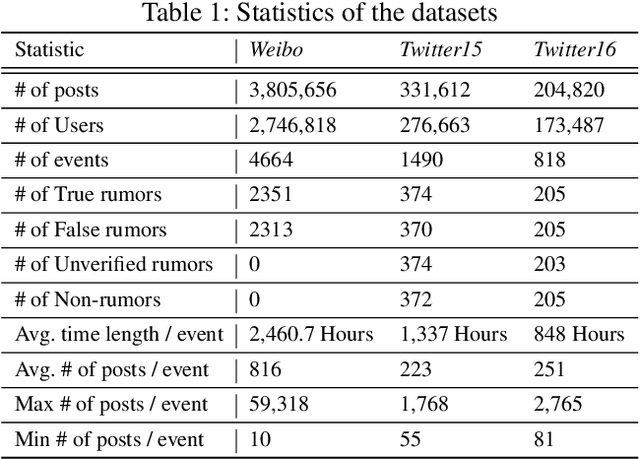
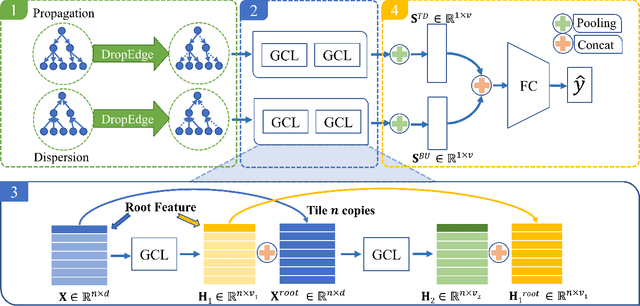
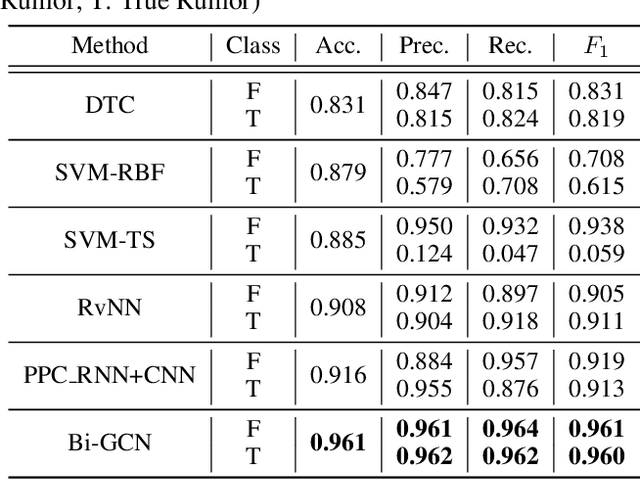
Social media has been developing rapidly in public due to its nature of spreading new information, which leads to rumors being circulated. Meanwhile, detecting rumors from such massive information in social media is becoming an arduous challenge. Therefore, some deep learning methods are applied to discover rumors through the way they spread, such as Recursive Neural Network (RvNN) and so on. However, these deep learning methods only take into account the patterns of deep propagation but ignore the structures of wide dispersion in rumor detection. Actually, propagation and dispersion are two crucial characteristics of rumors. In this paper, we propose a novel bi-directional graph model, named Bi-Directional Graph Convolutional Networks (Bi-GCN), to explore both characteristics by operating on both top-down and bottom-up propagation of rumors. It leverages a GCN with a top-down directed graph of rumor spreading to learn the patterns of rumor propagation, and a GCN with an opposite directed graph of rumor diffusion to capture the structures of rumor dispersion. Moreover, the information from the source post is involved in each layer of GCN to enhance the influences from the roots of rumors. Encouraging empirical results on several benchmarks confirm the superiority of the proposed method over the state-of-the-art approaches.