 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpherical Geometry Diffusion: Generating High-quality 3D Face Geometry via Sphere-anchored Representations
Jan 19, 2026A fundamental challenge in text-to-3D face generation is achieving high-quality geometry. The core difficulty lies in the arbitrary and intricate distribution of vertices in 3D space, making it challenging for existing models to establish clean connectivity and resulting in suboptimal geometry. To address this, our core insight is to simplify the underlying geometric structure by constraining the distribution onto a simple and regular manifold, a topological sphere. Building on this, we first propose the Spherical Geometry Representation, a novel face representation that anchors geometric signals to uniform spherical coordinates. This guarantees a regular point distribution, from which the mesh connectivity can be robustly reconstructed. Critically, this canonical sphere can be seamlessly unwrapped into a 2D map, creating a perfect synergy with powerful 2D generative models. We then introduce Spherical Geometry Diffusion, a conditional diffusion framework built upon this 2D map. It enables diverse and controllable generation by jointly modeling geometry and texture, where the geometry explicitly conditions the texture synthesis process. Our method's effectiveness is demonstrated through its success in a wide range of tasks: text-to-3D generation, face reconstruction, and text-based 3D editing. Extensive experiments show that our approach substantially outperforms existing methods in geometric quality, textual fidelity, and inference efficiency.
SciDA: Scientific Dynamic Assessor of LLMs
Jun 15, 2025Advancement in Large Language Models (LLMs) reasoning capabilities enables them to solve scientific problems with enhanced efficacy. Thereby, a high-quality benchmark for comprehensive and appropriate assessment holds significance, while existing ones either confront the risk of data contamination or lack involved disciplines. To be specific, due to the data source overlap of LLMs training and static benchmark, the keys or number pattern of answers inadvertently memorized (i.e. data contamination), leading to systematic overestimation of their reasoning capabilities, especially numerical reasoning. We propose SciDA, a multidisciplinary benchmark that consists exclusively of over 1k Olympic-level numerical computation problems, allowing randomized numerical initializations for each inference round to avoid reliance on fixed numerical patterns. We conduct a series of experiments with both closed-source and open-source top-performing LLMs, and it is observed that the performance of LLMs drop significantly under random numerical initialization. Thus, we provide truthful and unbiased assessments of the numerical reasoning capabilities of LLMs. The data is available at https://huggingface.co/datasets/m-a-p/SciDA
3D Point Cloud Generation via Autoregressive Up-sampling
Mar 11, 2025We introduce a pioneering autoregressive generative model for 3D point cloud generation. Inspired by visual autoregressive modeling (VAR), we conceptualize point cloud generation as an autoregressive up-sampling process. This leads to our novel model, PointARU, which progressively refines 3D point clouds from coarse to fine scales. PointARU follows a two-stage training paradigm: first, it learns multi-scale discrete representations of point clouds, and then it trains an autoregressive transformer for next-scale prediction. To address the inherent unordered and irregular structure of point clouds, we incorporate specialized point-based up-sampling network modules in both stages and integrate 3D absolute positional encoding based on the decoded point cloud at each scale during the second stage. Our model surpasses state-of-the-art (SoTA) diffusion-based approaches in both generation quality and parameter efficiency across diverse experimental settings, marking a new milestone for autoregressive methods in 3D point cloud generation. Furthermore, PointARU demonstrates exceptional performance in completing partial 3D shapes and up-sampling sparse point clouds, outperforming existing generative models in these tasks.
Recent Advances in Speech Language Models: A Survey
Oct 01, 2024



Large Language Models (LLMs) have recently garnered significant attention, primarily for their capabilities in text-based interactions. However, natural human interaction often relies on speech, necessitating a shift towards voice-based models. A straightforward approach to achieve this involves a pipeline of ``Automatic Speech Recognition (ASR) + LLM + Text-to-Speech (TTS)", where input speech is transcribed to text, processed by an LLM, and then converted back to speech. Despite being straightforward, this method suffers from inherent limitations, such as information loss during modality conversion and error accumulation across the three stages. To address these issues, Speech Language Models (SpeechLMs) -- end-to-end models that generate speech without converting from text -- have emerged as a promising alternative. This survey paper provides the first comprehensive overview of recent methodologies for constructing SpeechLMs, detailing the key components of their architecture and the various training recipes integral to their development. Additionally, we systematically survey the various capabilities of SpeechLMs, categorize the evaluation metrics for SpeechLMs, and discuss the challenges and future research directions in this rapidly evolving field.
Parameter-Efficient Fine-Tuning with Discrete Fourier Transform
May 05, 2024Low-rank adaptation~(LoRA) has recently gained much interest in fine-tuning foundation models. It effectively reduces the number of trainable parameters by incorporating low-rank matrices $A$ and $B$ to represent the weight change, i.e., $\Delta W=BA$. Despite LoRA's progress, it faces storage challenges when handling extensive customization adaptations or larger base models. In this work, we aim to further compress trainable parameters by enjoying the powerful expressiveness of the Fourier transform. Specifically, we introduce FourierFT, which treats $\Delta W$ as a matrix in the spatial domain and learns only a small fraction of its spectral coefficients. With the trained spectral coefficients, we implement the inverse discrete Fourier transform to recover $\Delta W$. Empirically, our FourierFT method shows comparable or better performance with fewer parameters than LoRA on various tasks, including natural language understanding, natural language generation, instruction tuning, and image classification. For example, when performing instruction tuning on the LLaMA2-7B model, FourierFT surpasses LoRA with only 0.064M trainable parameters, compared to LoRA's 33.5M. Our code is released at \url{https://github.com/Chaos96/fourierft}.
Language Agents for Detecting Implicit Stereotypes in Text-to-image Models at Scale
Nov 02, 2023



The recent surge in the research of diffusion models has accelerated the adoption of text-to-image models in various Artificial Intelligence Generated Content (AIGC) commercial products. While these exceptional AIGC products are gaining increasing recognition and sparking enthusiasm among consumers, the questions regarding whether, when, and how these models might unintentionally reinforce existing societal stereotypes remain largely unaddressed. Motivated by recent advancements in language agents, here we introduce a novel agent architecture tailored for stereotype detection in text-to-image models. This versatile agent architecture is capable of accommodating free-form detection tasks and can autonomously invoke various tools to facilitate the entire process, from generating corresponding instructions and images, to detecting stereotypes. We build the stereotype-relevant benchmark based on multiple open-text datasets, and apply this architecture to commercial products and popular open source text-to-image models. We find that these models often display serious stereotypes when it comes to certain prompts about personal characteristics, social cultural context and crime-related aspects. In summary, these empirical findings underscore the pervasive existence of stereotypes across social dimensions, including gender, race, and religion, which not only validate the effectiveness of our proposed approach, but also emphasize the critical necessity of addressing potential ethical risks in the burgeoning realm of AIGC. As AIGC continues its rapid expansion trajectory, with new models and plugins emerging daily in staggering numbers, the challenge lies in the timely detection and mitigation of potential biases within these models.
A Machine Learning Method for Predicting Traffic Signal Timing from Probe Vehicle Data
Aug 04, 2023



Traffic signals play an important role in transportation by enabling traffic flow management, and ensuring safety at intersections. In addition, knowing the traffic signal phase and timing data can allow optimal vehicle routing for time and energy efficiency, eco-driving, and the accurate simulation of signalized road networks. In this paper, we present a machine learning (ML) method for estimating traffic signal timing information from vehicle probe data. To the authors best knowledge, very few works have presented ML techniques for determining traffic signal timing parameters from vehicle probe data. In this work, we develop an Extreme Gradient Boosting (XGBoost) model to estimate signal cycle lengths and a neural network model to determine the corresponding red times per phase from probe data. The green times are then be derived from the cycle length and red times. Our results show an error of less than 0.56 sec for cycle length, and red times predictions within 7.2 sec error on average.
Attention Paper: How Generative AI Reshapes Digital Shadow Industry?
May 26, 2023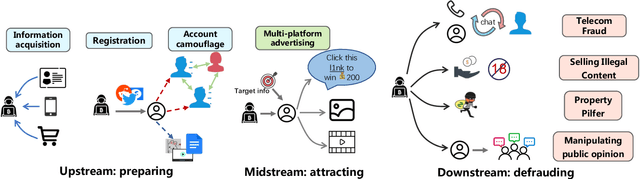
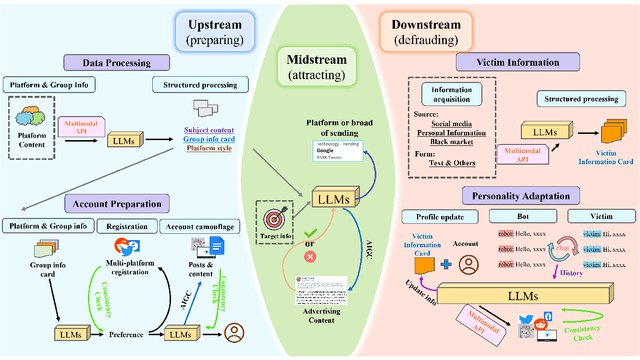

The rapid development of digital economy has led to the emergence of various black and shadow internet industries, which pose potential risks that can be identified and managed through digital risk management (DRM) that uses different techniques such as machine learning and deep learning. The evolution of DRM architecture has been driven by changes in data forms. However, the development of AI-generated content (AIGC) technology, such as ChatGPT and Stable Diffusion, has given black and shadow industries powerful tools to personalize data and generate realistic images and conversations for fraudulent activities. This poses a challenge for DRM systems to control risks from the source of data generation and to respond quickly to the fast-changing risk environment. This paper aims to provide a technical analysis of the challenges and opportunities of AIGC from upstream, midstream, and downstream paths of black/shadow industries and suggest future directions for improving existing risk control systems. The paper will explore the new black and shadow techniques triggered by generative AI technology and provide insights for building the next-generation DRM system.
Prioritized Guidance for Efficient Multi-Agent Reinforcement Learning Exploration
Jul 19, 2019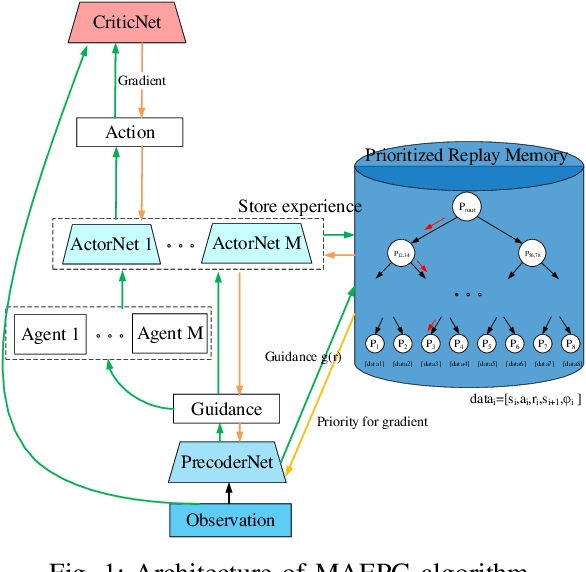
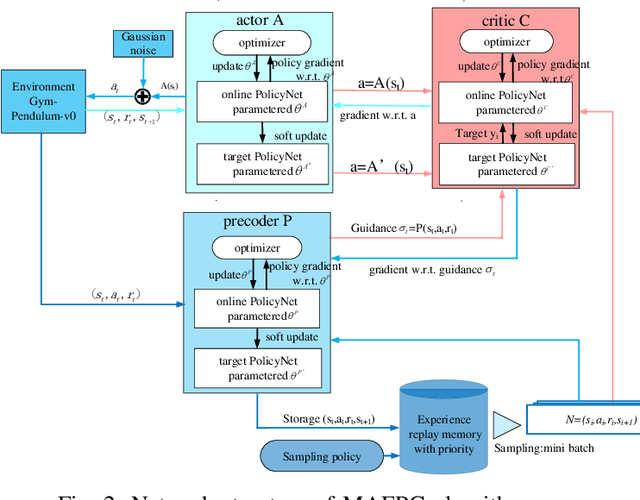

Exploration efficiency is a challenging problem in multi-agent reinforcement learning (MARL), as the policy learned by confederate MARL depends on the collaborative approach among multiple agents. Another important problem is the less informative reward restricts the learning speed of MARL compared with the informative label in supervised learning. In this work, we leverage on a novel communication method to guide MARL to accelerate exploration and propose a predictive network to forecast the reward of current state-action pair and use the guidance learned by the predictive network to modify the reward function. An improved prioritized experience replay is employed to better take advantage of the different knowledge learned by different agents which utilizes Time-difference (TD) error more effectively. Experimental results demonstrates that the proposed algorithm outperforms existing methods in cooperative multi-agent environments. We remark that this algorithm can be extended to supervised learning to speed up its training.