 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantum Algorithm for Sparse Online Learning with Truncated Gradient Descent
Nov 06, 2024
Logistic regression, the Support Vector Machine (SVM), and least squares are well-studied methods in the statistical and computer science community, with various practical applications. High-dimensional data arriving on a real-time basis makes the design of online learning algorithms that produce sparse solutions essential. The seminal work of \hyperlink{cite.langford2009sparse}{Langford, Li, and Zhang (2009)} developed a method to obtain sparsity via truncated gradient descent, showing a near-optimal online regret bound. Based on this method, we develop a quantum sparse online learning algorithm for logistic regression, the SVM, and least squares. Given efficient quantum access to the inputs, we show that a quadratic speedup in the time complexity with respect to the dimension of the problem is achievable, while maintaining a regret of $O(1/\sqrt{T})$, where $T$ is the number of iterations.
Logarithmic-Regret Quantum Learning Algorithms for Zero-Sum Games
Apr 27, 2023

We propose the first online quantum algorithm for zero-sum games with $\tilde O(1)$ regret under the game setting. Moreover, our quantum algorithm computes an $\varepsilon$-approximate Nash equilibrium of an $m \times n$ matrix zero-sum game in quantum time $\tilde O(\sqrt{m+n}/\varepsilon^{2.5})$, yielding a quadratic improvement over classical algorithms in terms of $m, n$. Our algorithm uses standard quantum inputs and generates classical outputs with succinct descriptions, facilitating end-to-end applications. As an application, we obtain a fast quantum linear programming solver. Technically, our online quantum algorithm "quantizes" classical algorithms based on the optimistic multiplicative weight update method. At the heart of our algorithm is a fast quantum multi-sampling procedure for the Gibbs sampling problem, which may be of independent interest.
Double-Ended Palindromic Trees: A Linear-Time Data Structure and Its Applications
Oct 06, 2022


The palindromic tree (a.k.a. eertree) is a linear-size data structure that provides access to all palindromic substrings of a string. In this paper, we propose a generalized version of eertree, called double-ended eertree, which supports linear-time online double-ended queue operations on the stored string. At the heart of our construction, is a class of substrings, called surfaces, of independent interest. Namely, surfaces are neither prefixes nor suffixes of any other palindromic substrings and characterize the link structure of all palindromic substrings in the eertree. As an application, we develop a framework for range queries involving palindromes on strings, including counting distinct palindromic substrings, and finding the longest palindromic substring, shortest unique palindromic substring and shortest absent palindrome of any substring. In particular, offline queries only use linear space. Apart from range queries, we enumerate palindromic rich strings with a given word in linear time on the length of the given word.
Hybrid Beamforming for mmWave MU-MISO Systems Exploiting Multi-agent Deep Reinforcement Learning
Feb 01, 2021



In this letter, we investigate the hybrid beamforming based on deep reinforcement learning (DRL) for millimeter Wave (mmWave) multi-user (MU) multiple-input-single-output (MISO) system. A multi-agent DRL method is proposed to solve the exploration efficiency problem in DRL. In the proposed method, prioritized replay buffer and more informative reward are applied to accelerate the convergence. Simulation results show that the proposed architecture achieves higher spectral efficiency and less time consumption than the benchmarks, thus is more suitable for practical applications.
Improving Positive Unlabeled Learning: Practical AUL Estimation and New Training Method for Extremely Imbalanced Data Sets
Apr 21, 2020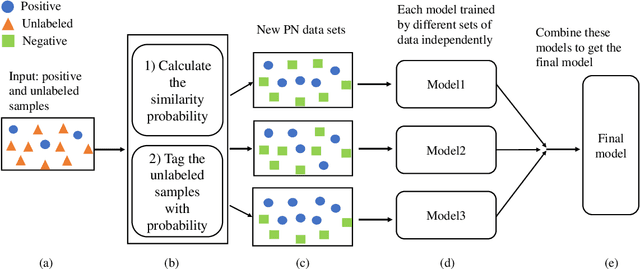
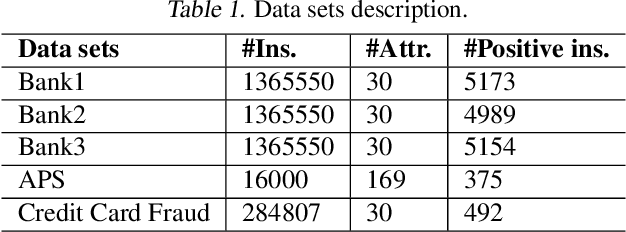
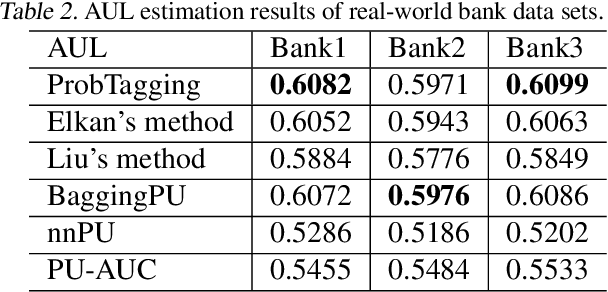
Positive Unlabeled (PU) learning is widely used in many applications, where a binary classifier is trained on the datasets consisting of only positive and unlabeled samples. In this paper, we improve PU learning over state-of-the-art from two aspects. Firstly, existing model evaluation methods for PU learning requires ground truth of unlabeled samples, which is unlikely to be obtained in practice. In order to release this restriction, we propose an asymptotic unbiased practical AUL (area under the lift) estimation method, which makes use of raw PU data without prior knowledge of unlabeled samples. Secondly, we propose ProbTagging, a new training method for extremely imbalanced data sets, where the number of unlabeled samples is hundreds or thousands of times that of positive samples. ProbTagging introduces probability into the aggregation method. Specifically, each unlabeled sample is tagged positive or negative with the probability calculated based on the similarity to its positive neighbors. Based on this, multiple data sets are generated to train different models, which are then combined into an ensemble model. Compared to state-of-the-art work, the experimental results show that ProbTagging can increase the AUC by up to 10%, based on three industrial and two artificial PU data sets.
PrecoderNet: Hybrid Beamforming for Millimeter Wave Systems Using Deep Reinforcement Learning
Jul 31, 2019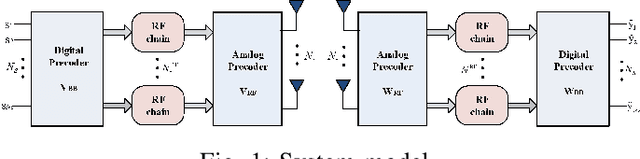
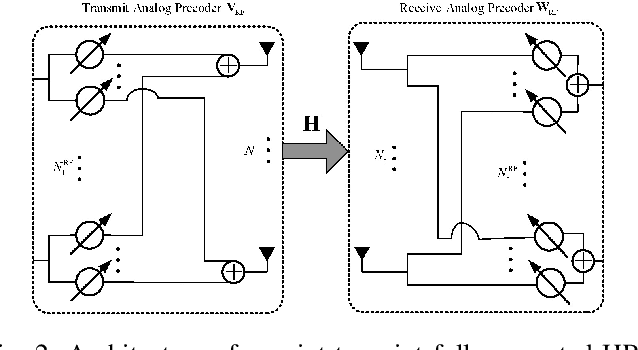
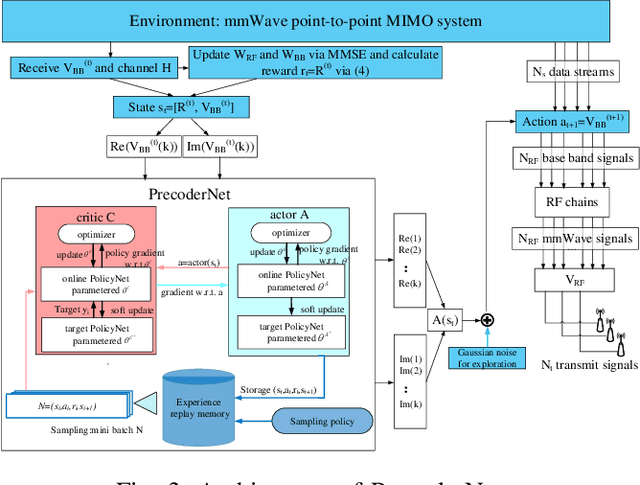
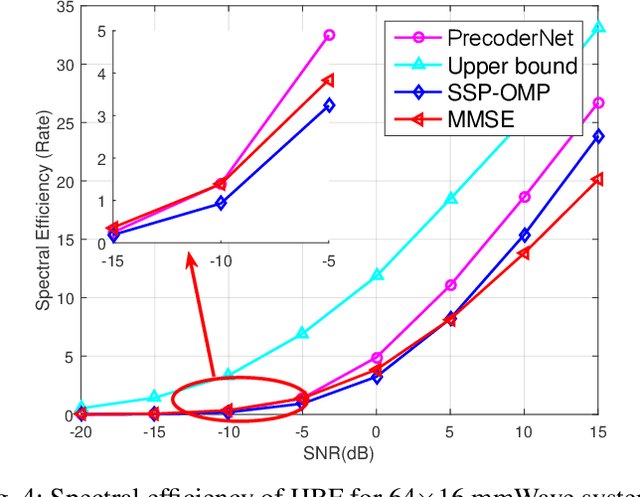
Millimeter wave (mmWave) with large-scale antenna arrays is a promising solution to resolve the frequency resource shortage in next generation wireless communication. However, fully digital beamforming structure becomes infeasible due to its prohibitively high hardware cost and unacceptable energy consumption while traditional hybrid beamforming algorithms have unnegligible gap to the optimal up bound. In this paper, we consider a mmWave point-to-point massive multiple-input-multiple-output (MIMO) system and propose a new hybrid analog and digital beamforming (HBF) scheme based on deep reinforcement learning (DRL) to improve the spectral efficiency and reduce system bit error rate (BER). At the base station (BS) side, we propose a novel DRL-based HBF design method called PrecoderNet to design the hybrid precoding matrix. The DRL agent denotes the system sum rate as state and the real /imaginary part of the digital beamformer as actions. For the user side, the minimum mean-square-error (MMSE) criterion is used to design the receiving hybrid precoders which minimizes the distance between the processed signals and the transmitted signals. Furthermore, HBF design algorithm such as weighted MMSE and orthogonal matching pursuit (OMP) are regarded as benchmarks to verify the performance of our algorithm. Finally, simulation results demonstrate that our proposed PrecoderNet outperforms the benchmarks in terms of spectral efficiency and BER while is more tractable in practical implementation.
Prioritized Guidance for Efficient Multi-Agent Reinforcement Learning Exploration
Jul 19, 2019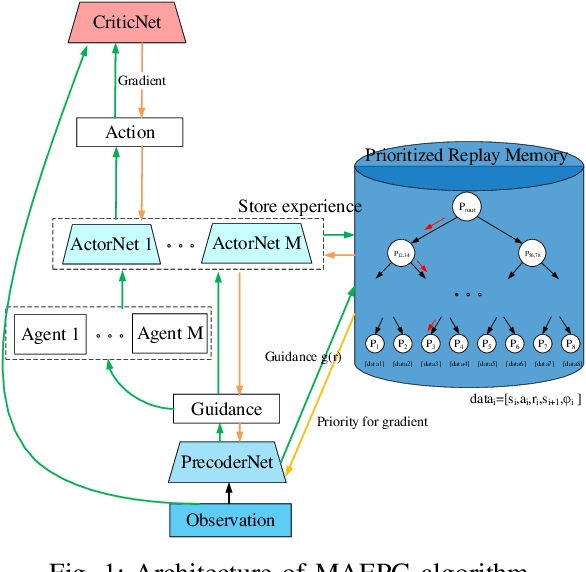
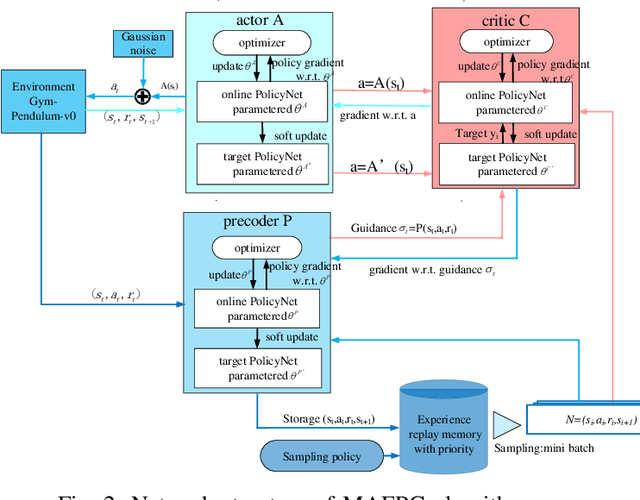

Exploration efficiency is a challenging problem in multi-agent reinforcement learning (MARL), as the policy learned by confederate MARL depends on the collaborative approach among multiple agents. Another important problem is the less informative reward restricts the learning speed of MARL compared with the informative label in supervised learning. In this work, we leverage on a novel communication method to guide MARL to accelerate exploration and propose a predictive network to forecast the reward of current state-action pair and use the guidance learned by the predictive network to modify the reward function. An improved prioritized experience replay is employed to better take advantage of the different knowledge learned by different agents which utilizes Time-difference (TD) error more effectively. Experimental results demonstrates that the proposed algorithm outperforms existing methods in cooperative multi-agent environments. We remark that this algorithm can be extended to supervised learning to speed up its training.